Introduce


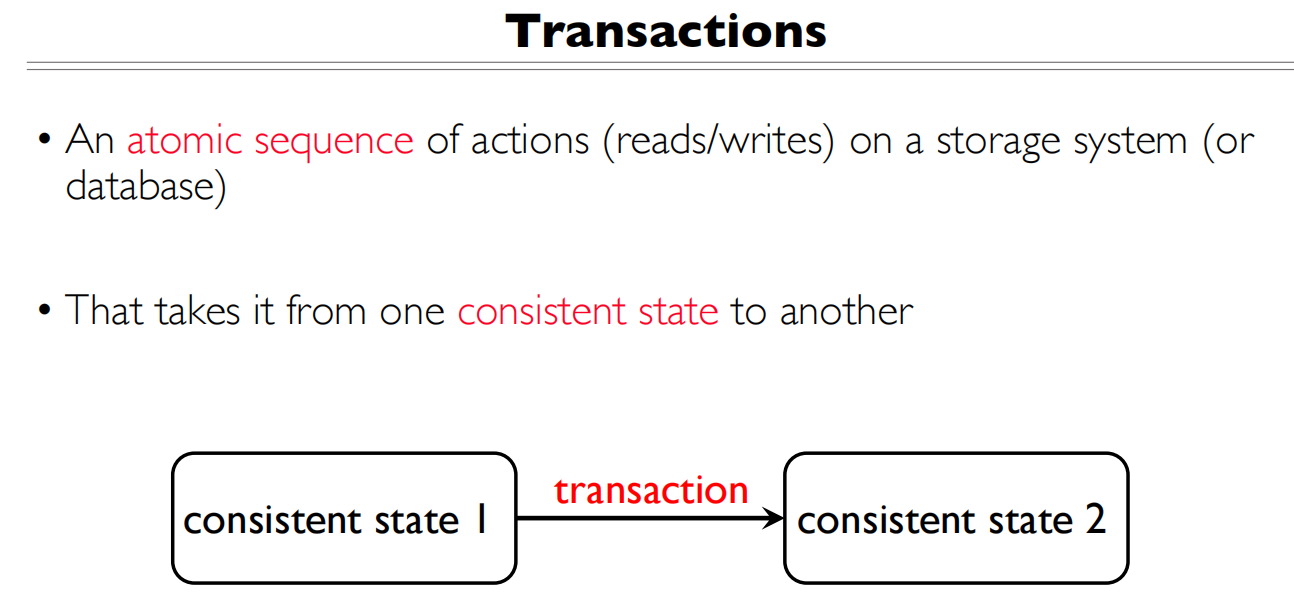
Transactions



Use Transactions (事务) for atomic updates
-
Ensure that multiple related updates are performed atomically
-
i.e., if a crash occurs in the middle, the state of the systems reflects either all or none of the updates
-
Most modern file systems use transactions internally to update filesystem structures and metadata
-
Many applications implement their own transactions
-
They extend concept of atomic update from memory to stable storage
- Atomically update multiple persistent data structures
做原子的多步更新


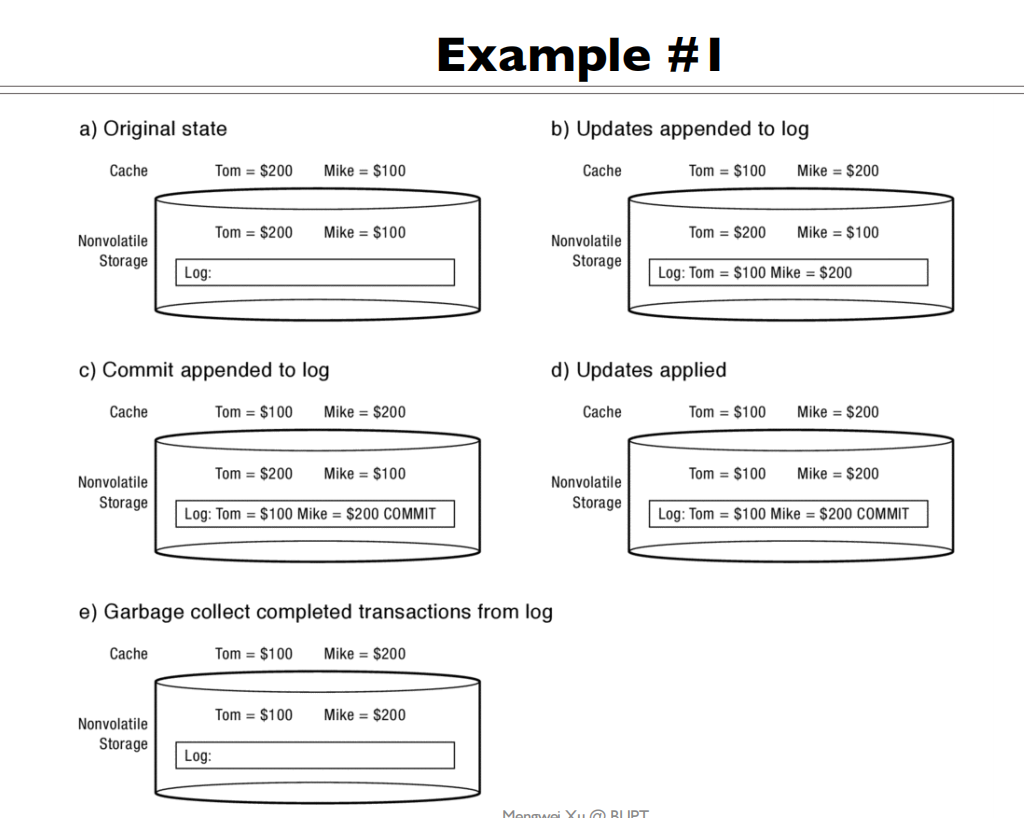
Logging



 如何判断commit前还是commit后?
如何判断commit前还是commit后?
- commit前无commit记录
- commit之后有commit记录
例子
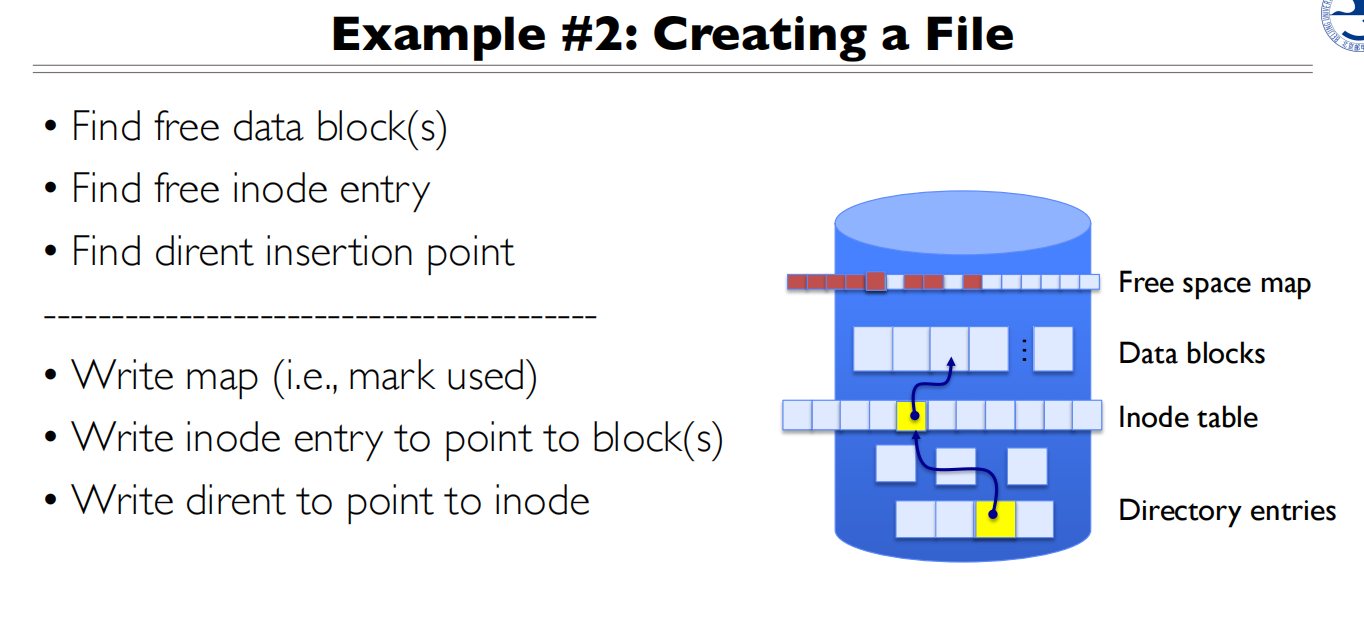
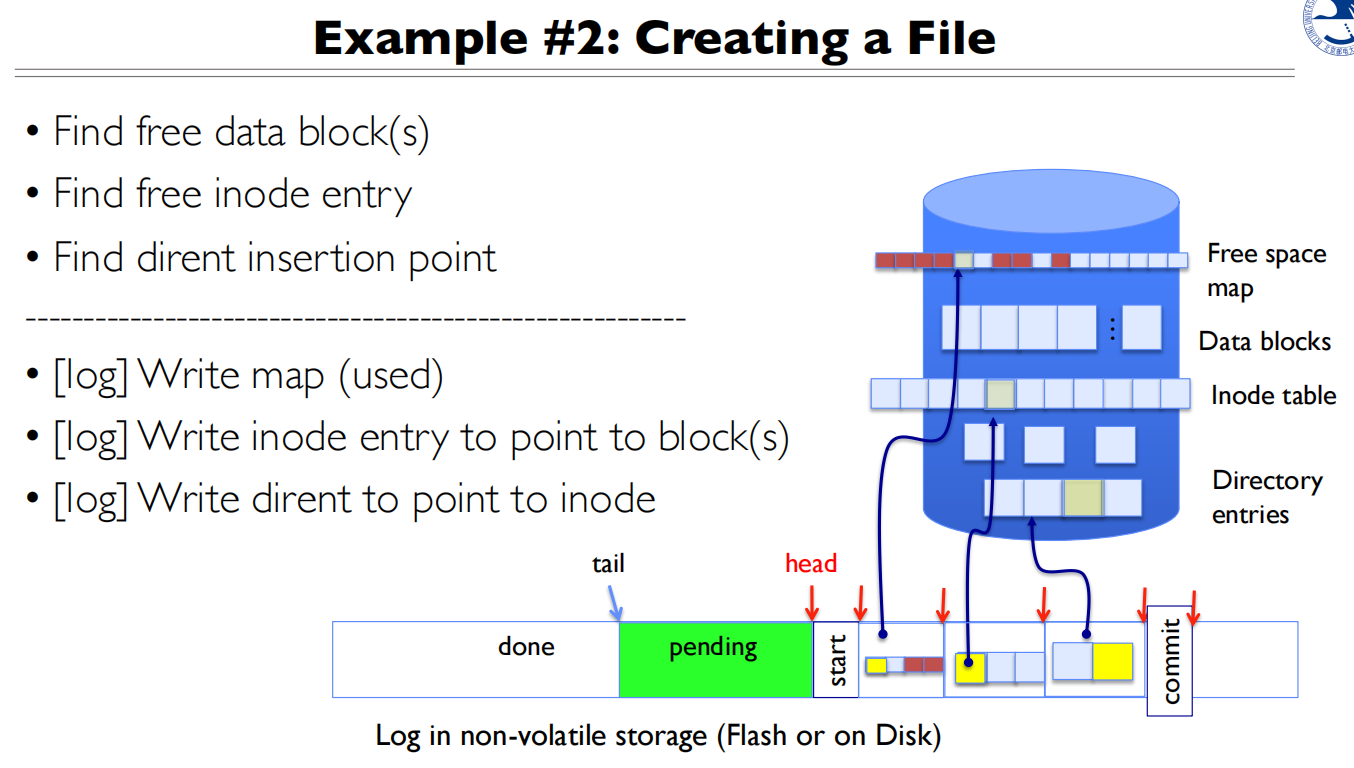
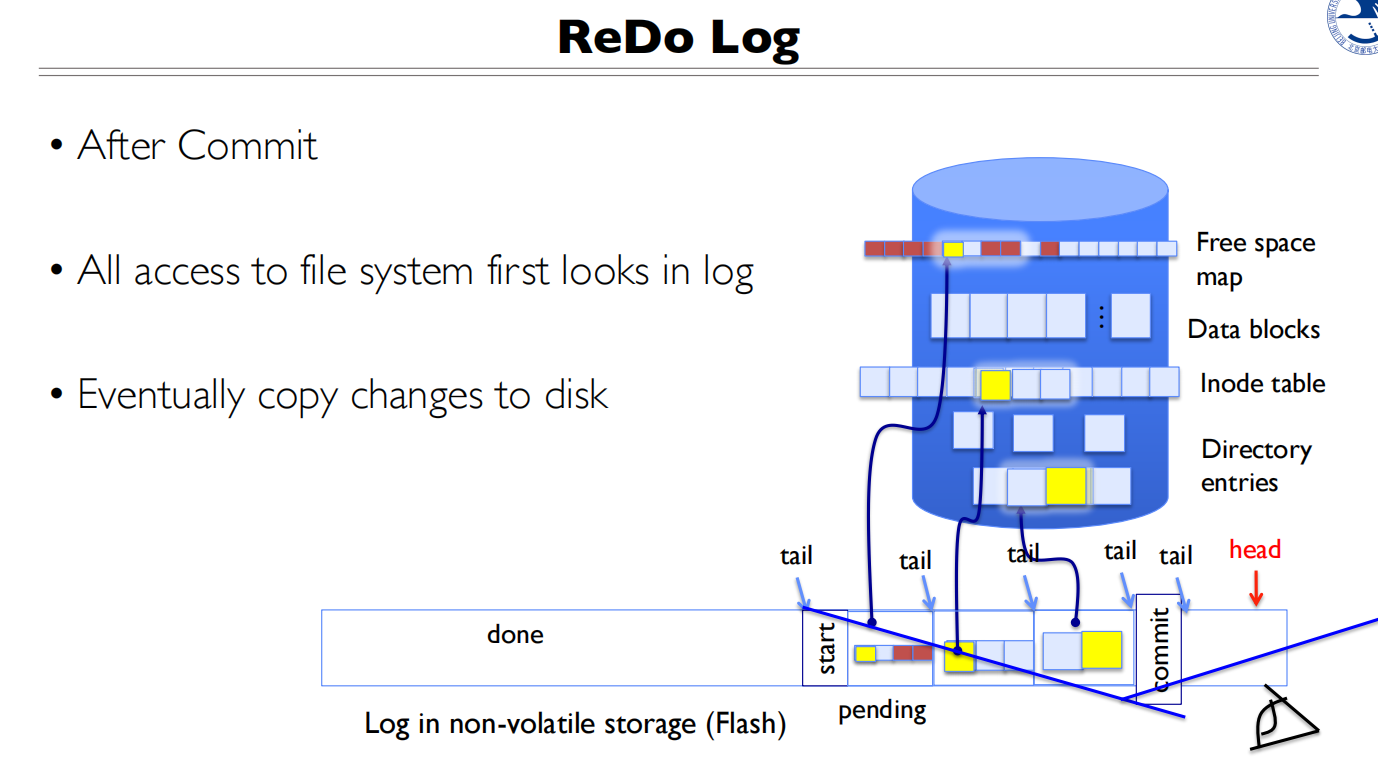
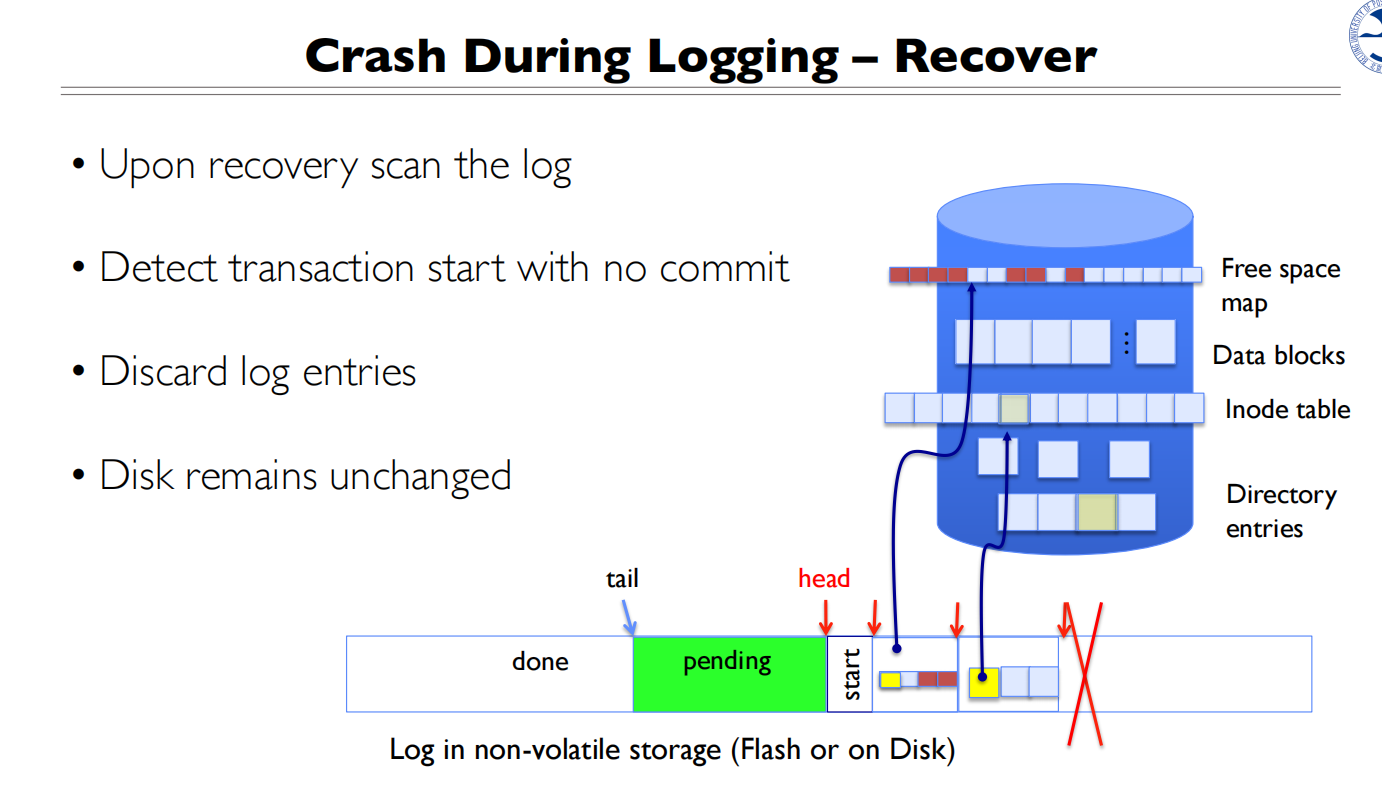
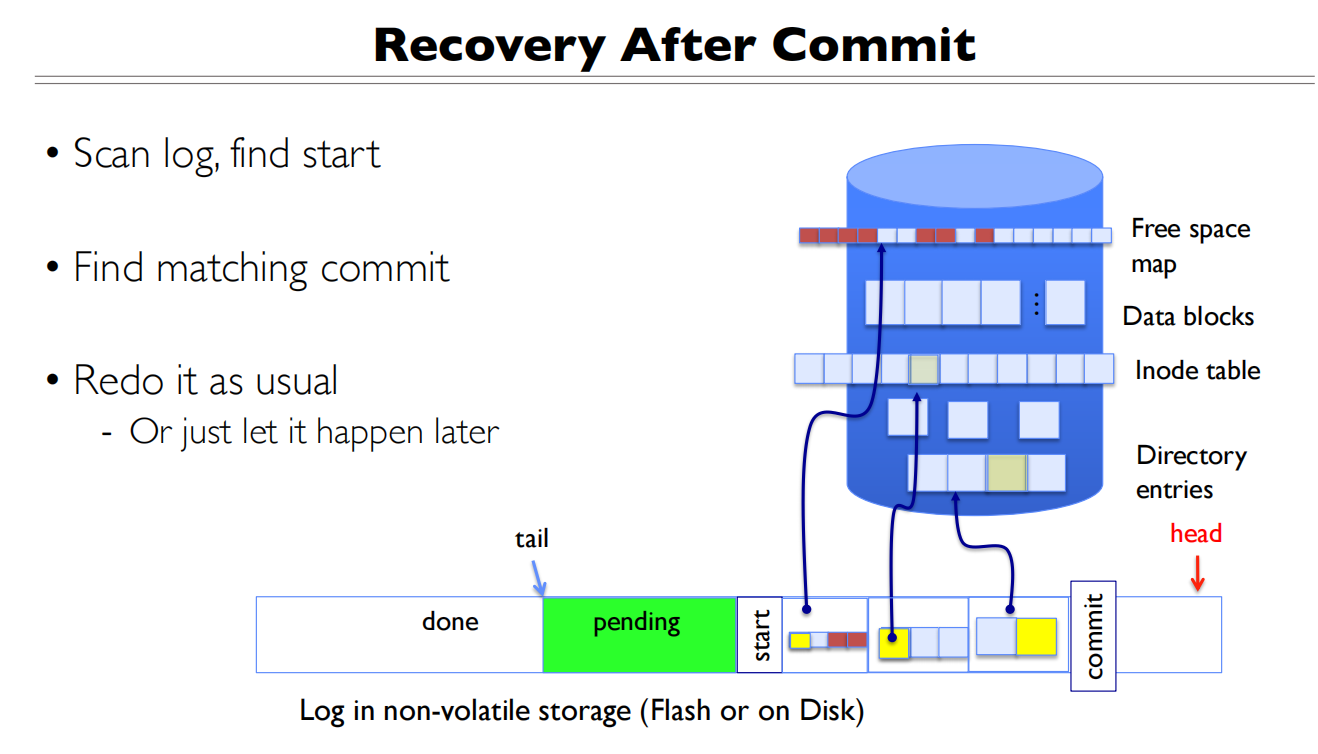
实现细节
 操作必须是幂等的,多次操作的结果不变
操作必须是幂等的,多次操作的结果不变
兼容多次crash的可行性
 可以先读日志,看有没有写操作,没有再去磁盘里面读
可以先读日志,看有没有写操作,没有再去磁盘里面读
性能上有缺陷,一次写操作变成两次写操作
优化
- 多个transaction batch到一起
- write back
Transactional File System
 Jounaling:不完全做logging,性能少损失,没法保证完全的可靠性
Jounaling:不完全做logging,性能少损失,没法保证完全的可靠性

RAID
Redundancy for media failures
RAID 1 Disk Mirroring/Shadowing
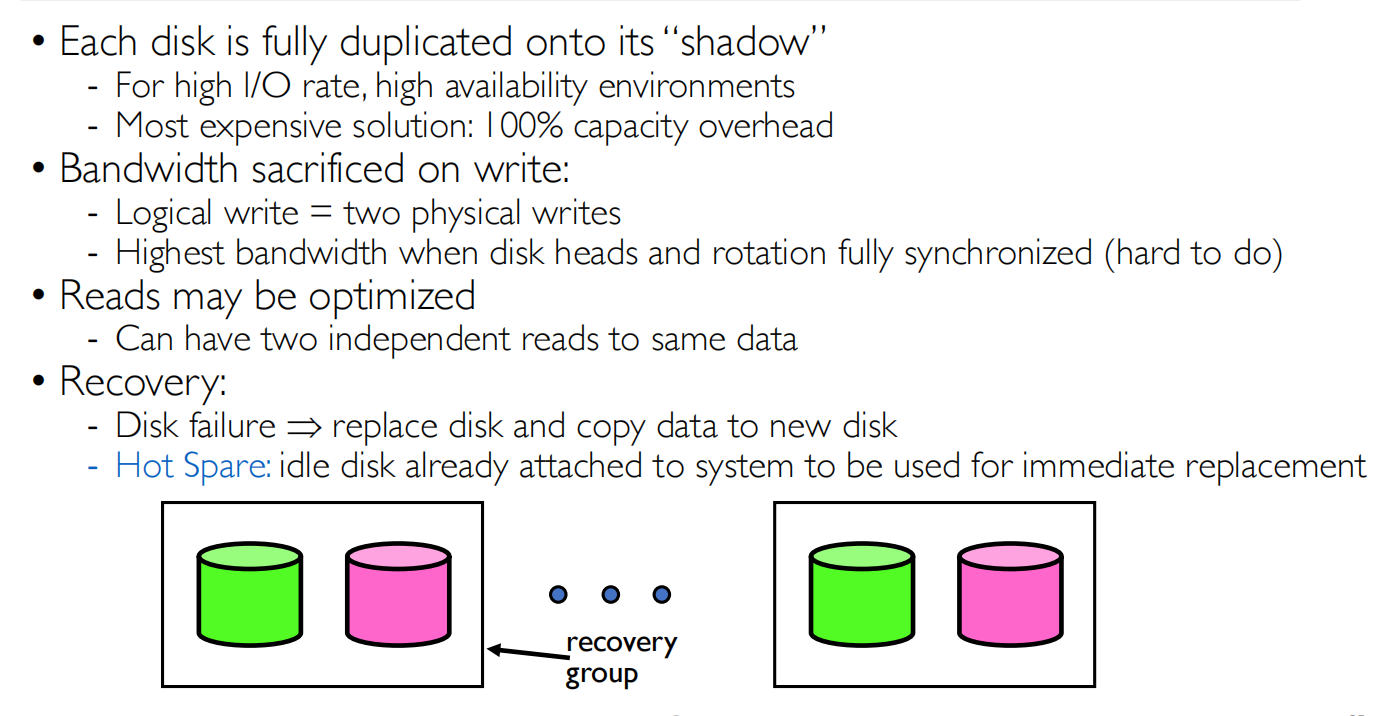 RAID1是完全复制磁盘中的数据
RAID1是完全复制磁盘中的数据
容量和开销:
- 存储效率低:100%的容量开销
- 实际可用容量是总容量的50%
- 是最昂贵的RAID解决方案之一
故障恢复:
- 基本恢复:当一个磁盘失效时,更换新磁盘并复制数据
- 热备份:系统中预留空闲磁盘,可以立即替换故障磁盘
 异或操作的一些内容,后面用来做数据验证
异或操作的一些内容,后面用来做数据验证
RAID 5+
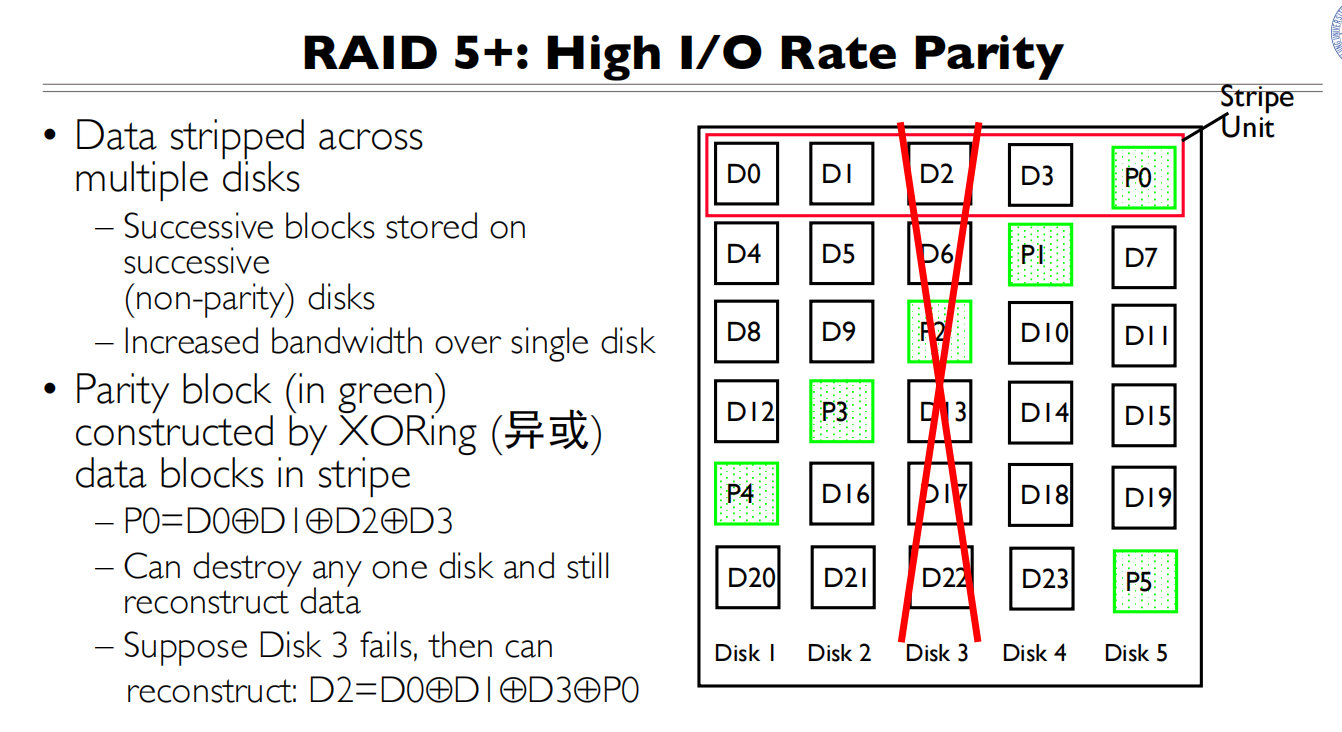
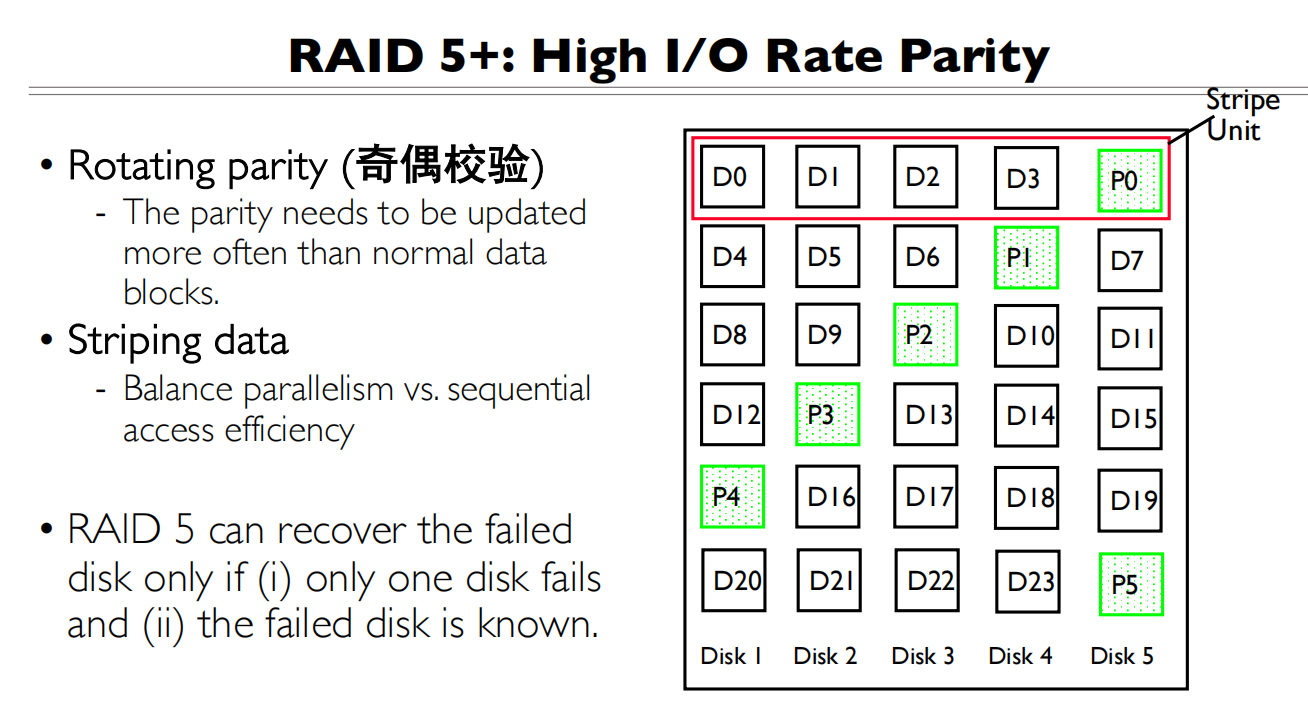
- 数据分布方式:
- 数据条带化:数据被分散存储在多个磁盘上(图中的D0-D23)
- 奇偶校验:每个条带都有一个奇偶校验块(图中绿色的P0-P5)
- 校验块分散:校验信息轮流存储在不同磁盘上,避免单个磁盘成为瓶颈
- 奇偶校验计算:
- 使用异或(XOR)运算计算校验块
- 如图所示:P0 = D0 ⊕ D1 ⊕ D2 ⊕ D3
- 当任何一块磁盘损坏时,可以通过其他数据块和校验块重建数据 例如:如果D2损坏,可以通过 D2 = D0 ⊕ D1 ⊕ D3 ⊕ P0 恢复
- 性能特点:
- 读性能:优于RAID 1,因为数据分布在多个磁盘上
- 写性能:每次写都需要计算并更新校验块,会有一定开销
- 带宽:由于条带化的原因,比单个磁盘高
- 存储效率:
- 只损失一个磁盘的容量用于存储校验信息
- 比RAID 1的50%空间利用率要好得多
- N个磁盘的可用容量为(N-1)个磁盘的容量
- 容错能力:
- 可以承受任意一块磁盘的故障
- 通过其他磁盘的数据和校验信息可以重建失效磁盘的数据
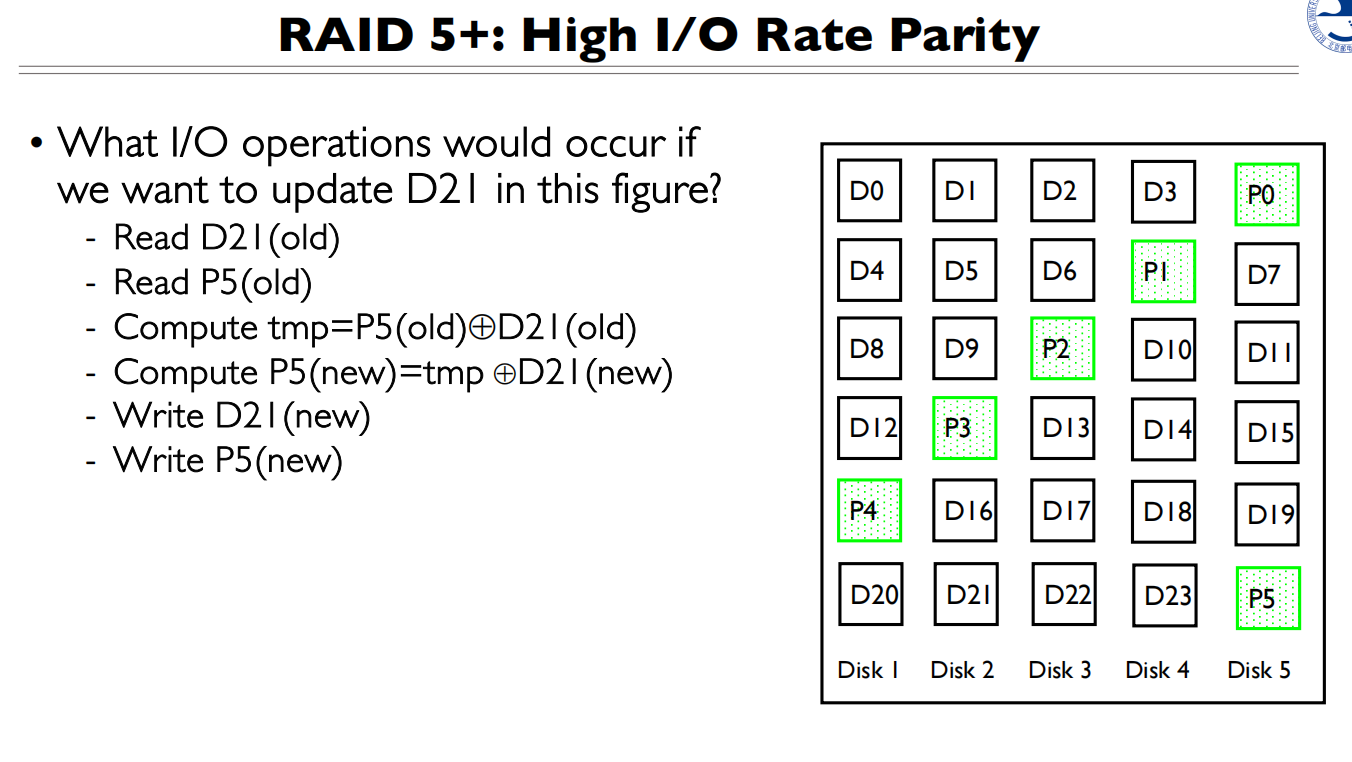
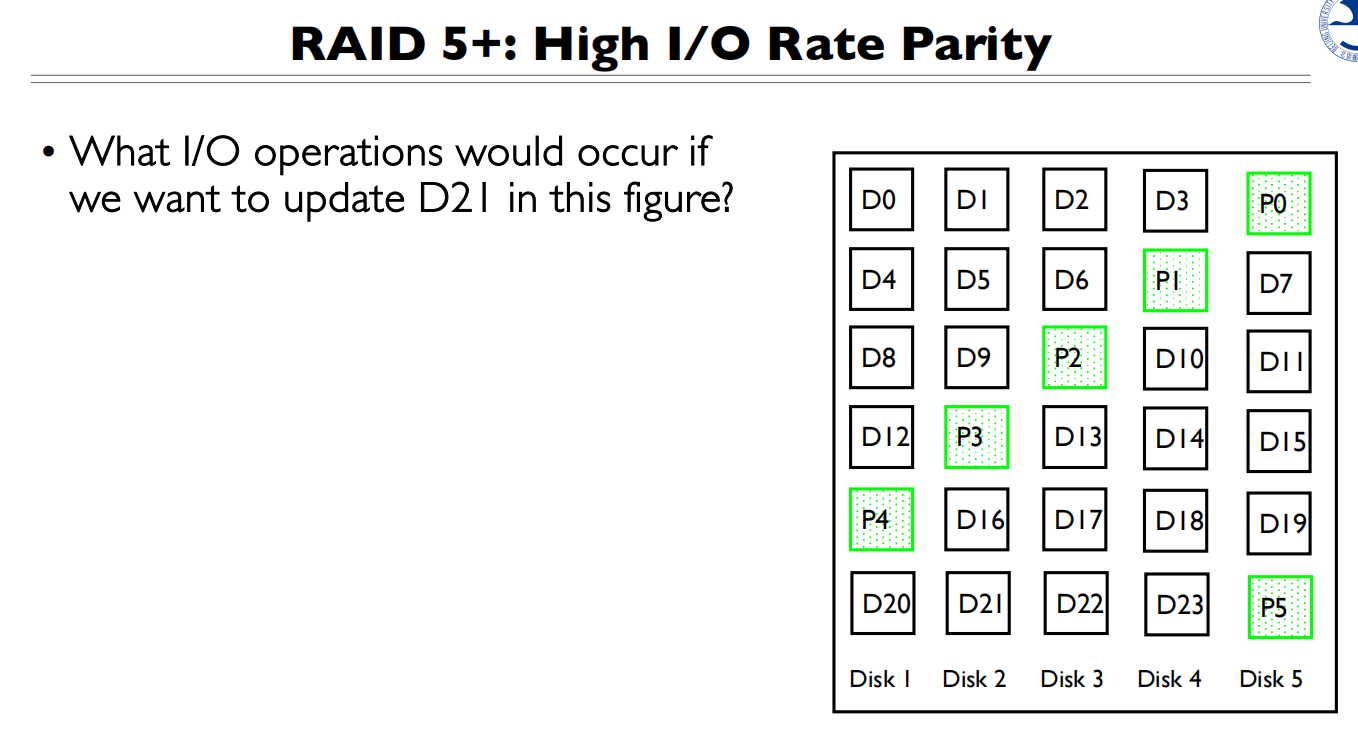 如果更新D21,需要更新P5,所以需要做2次读和2次写操作
如果更新D21,需要更新P5,所以需要做2次读和2次写操作
例题
 Inode组成
Inode组成
- user id (2 bytes)
- three time stamps(4 bytes)
- protection bits (2 bytes)
- reference count(2 byte)
- file type(2 bytes)
- size(4 bytes)
- 13 DP (13 * 4 bytes)
- 1st index (4 bytes)
- 2nd index (4 bytes)
- 3rd index (4 bytes) +436 bytes
a disk sector is 512 bytes,任何辅助index表都占用一个扇区512 bytes
Maximum size for a file in this system
这个设计有几个主要优点:
- 快速访问:对于小文件(≤436字节)来说,可以直接从inode读取数据,不需要额外的磁盘访问
- 提高效率:因为很多系统文件和配置文件都很小,这种设计可以显著提高这类文件的访问速度
- 减少磁盘碎片:小文件直接存储在inode中,不需要占用额外的数据块,减少了磁盘碎片
- 性能优化:减少了I/O操作,特别是对于频繁访问的小文件
 不同文件系统是如何区分目录和文件的
不同文件系统是如何区分目录和文件的
- FAT (File Allocation Table) 文件系统:
- FAT使用目录条目(Directory Entry)中的属性字段来标识文件类型
- 具体使用一个8位的属性字节,其中包含:
- 0x10: 表示该条目是一个目录
- 0x20: 表示该条目是一个普通文件
- 其他位用于表示只读、隐藏、系统等属性
- FFS (Fast File System/Unix File System):
- FFS在inode结构中使用mode字段来标识文件类型
- mode字段通常是16位,其中:
- 高4位用于表示文件类型(普通文件、目录、符号链接等)
- 低12位用于存储权限信息
- 常见的文件类型标识:
- 0x8000: 普通文件
- 0x4000: 目录
- 0x2000: 字符设备
- 0x6000: 块设备
- NTFS (New Technology File System):
- NTFS使用MFT(主文件表)条目中的文件属性来标识文件类型
- 每个文件的MFT条目包含一个标准信息属性(Standard Information Attribute)
- 在标准信息属性中:
- 使用文件属性标志来标识文件类型
- 目录标志位设置为1表示目录
- 还包含其他属性如只读、隐藏、系统等
 只用直接索引的最大文件:
最大的文件:
只用直接索引的最大文件:
最大的文件:
 假如现在在磁道88,向上移动,使用电梯算法,服务的顺序是什么
假如现在在磁道88,向上移动,使用电梯算法,服务的顺序是什么
100 116 185 87 75 22 11 3