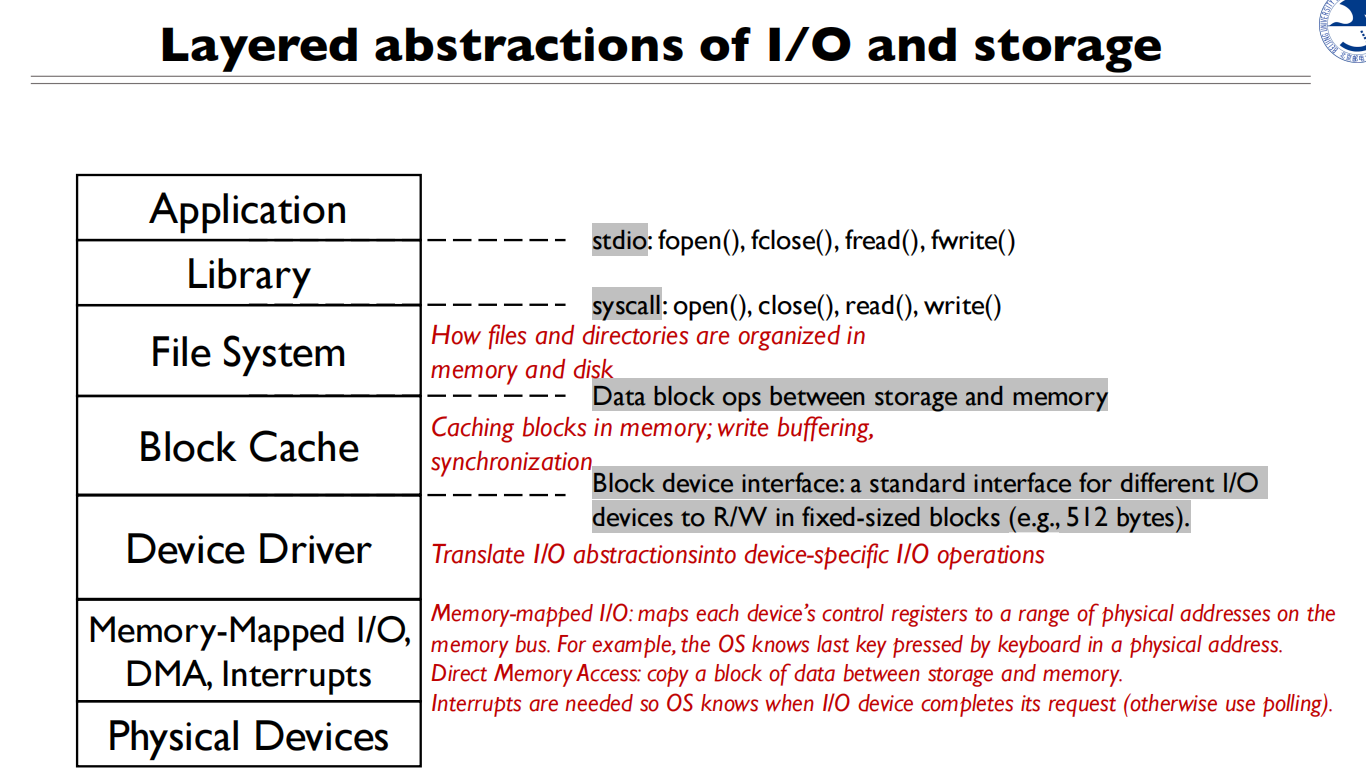
Introduce
 Block是操作系统层面管理IO数据的粒度
Block是操作系统层面管理IO数据的粒度
 写是异步的,读的时候不会有同步的问题,直接读到最新的数据
写是异步的,读的时候不会有同步的问题,直接读到最新的数据
FS的定义
File System: Layer of OS that transforms block interface of disks (orother block devices) into Files, Directories, etc.
• File System Components
- Naming: Interface to find files by name, not by blocks 命名
- Disk Management: collecting disk blocks into files 磁盘的管理
- Protection: Layers to keep data secure 保护,不太涉及
- Reliability/Durability: Keeping of files durable despite crashes, media failures,attacks, etc. 可靠性
 一个block是逻辑上的读写单元,一般会大于扇区(1KB)
一个block是逻辑上的读写单元,一般会大于扇区(1KB)
 在文件系统里面,Block就是读写的最小单元
在文件系统里面,Block就是读写的最小单元
 不关心物理结构,对FS是很多个block
不关心物理结构,对FS是很多个block
 文件头会存文件的信息
文件头会存文件的信息
File

- 有名字的
- 永久存储的
- 是一块存储
meta data存在block里面
目录
 目录也有属性,和文件的不同点在于,目录没有数据
目录也有属性,和文件的不同点在于,目录没有数据
 挂载就是把一个卷的物理存储区域,挂载到文件系统的某个区域
挂载就是把一个卷的物理存储区域,挂载到文件系统的某个区域

 解析文件名,获得文件号 → 定位Block
解析文件名,获得文件号 → 定位Block
Inode
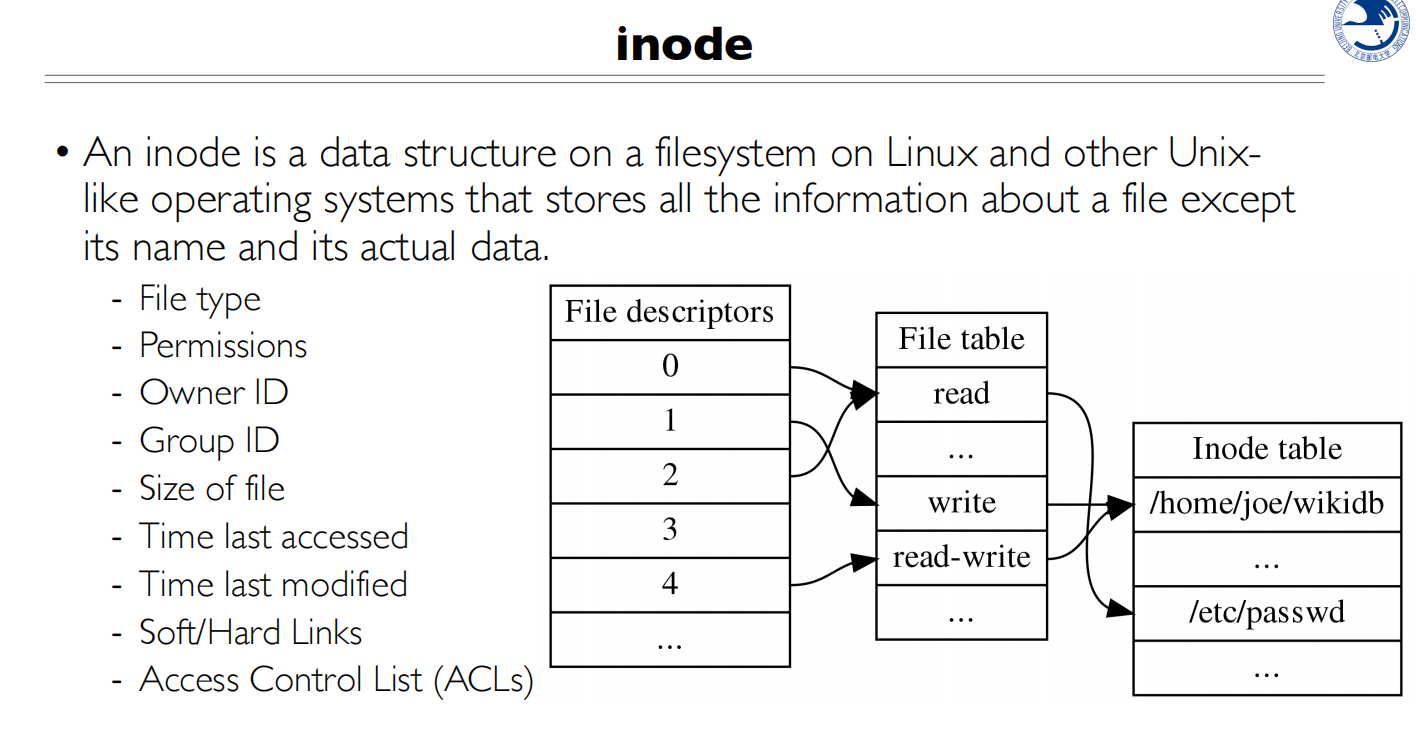 每个文件都有一一对应的Inode,永久存储的(有可能不一一对应)
每个文件都有一一对应的Inode,永久存储的(有可能不一一对应)
文件的移动不会改变Inode

For 32-bit inode number, it’s 2^32 (about 4 billions)
- Max
It’s also configurable in many file systems
Out of inode error..
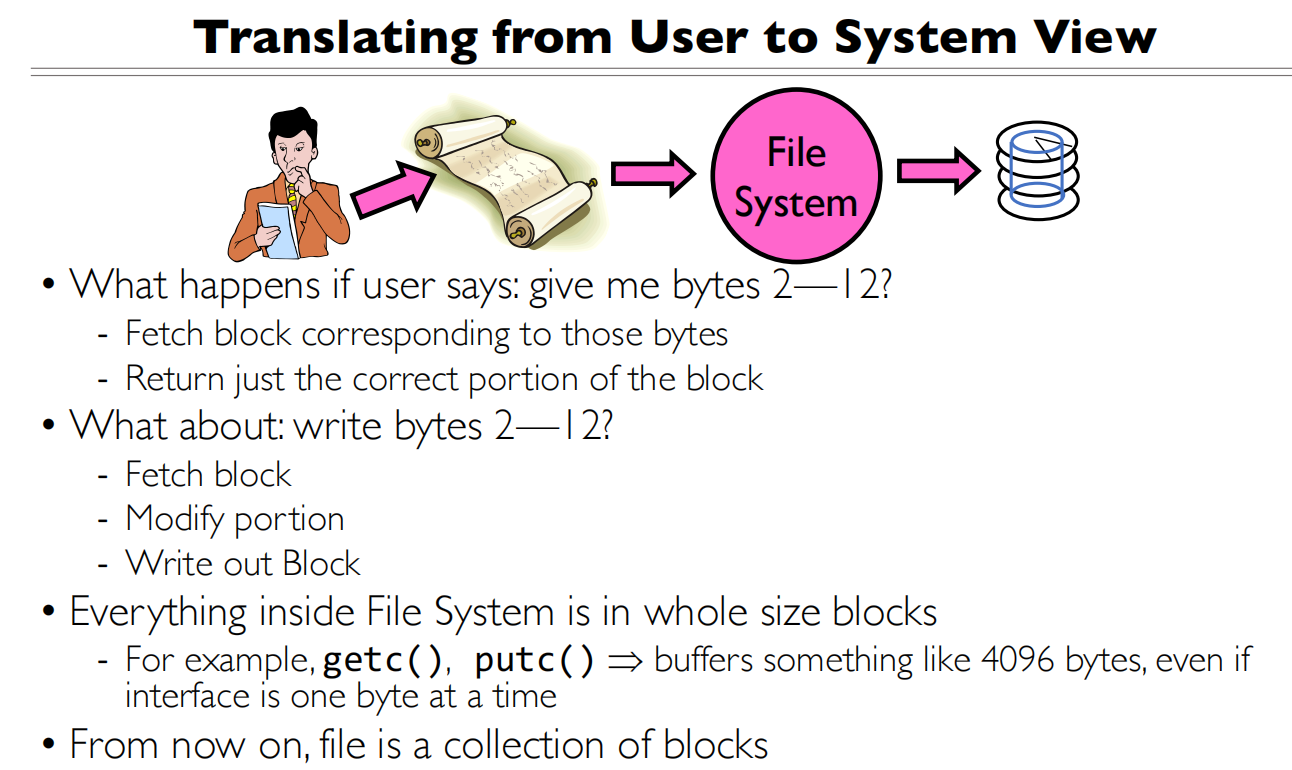
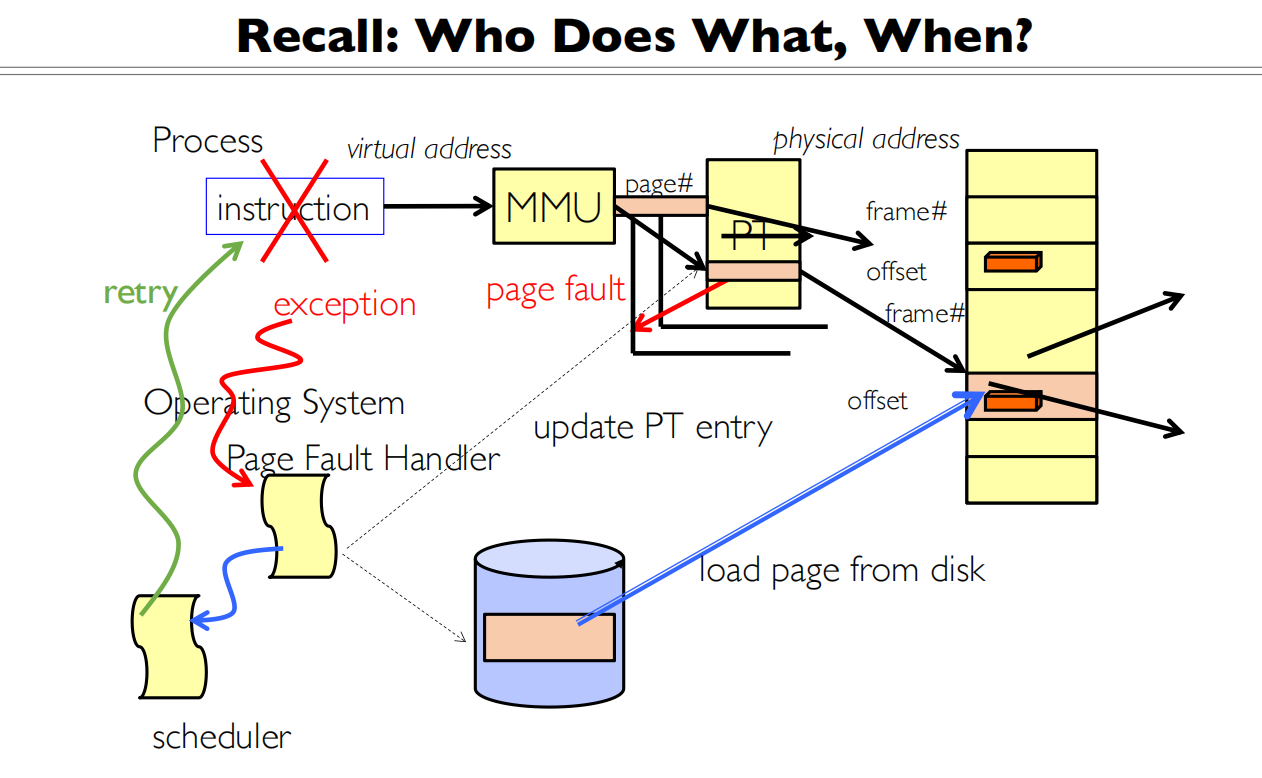
IO函数都做了什么
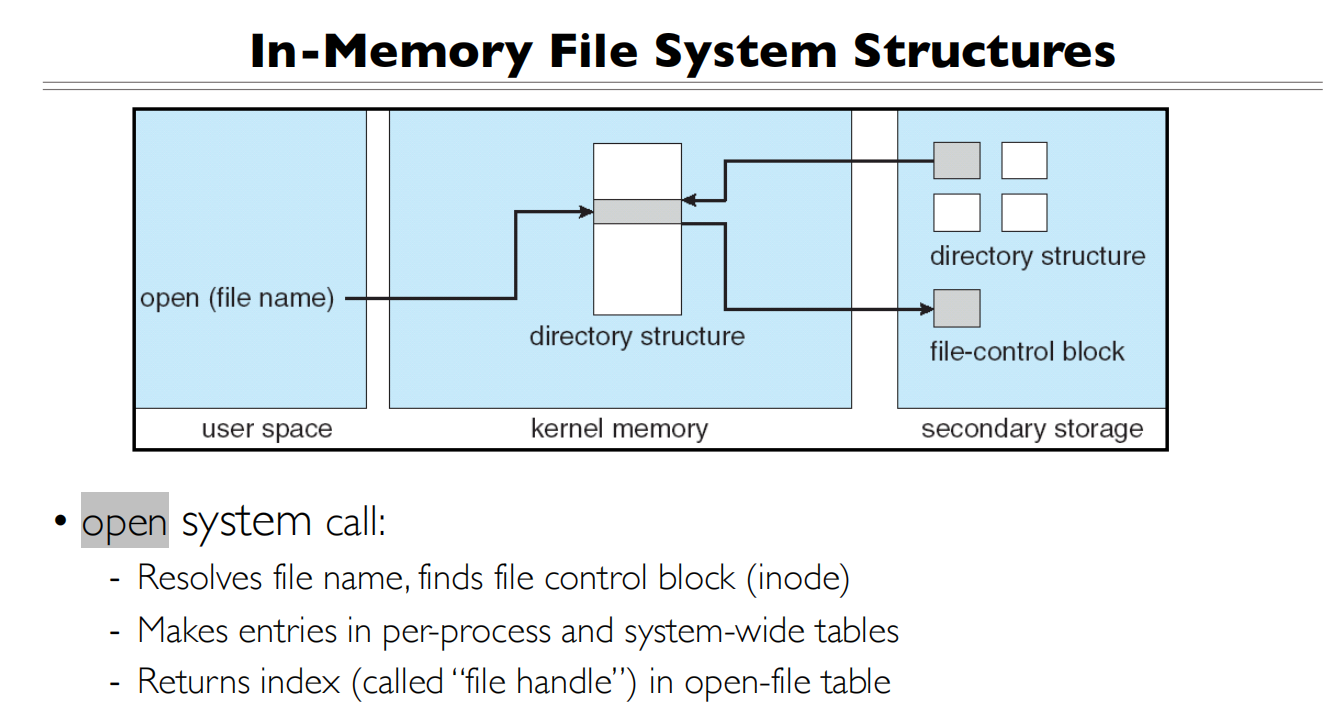
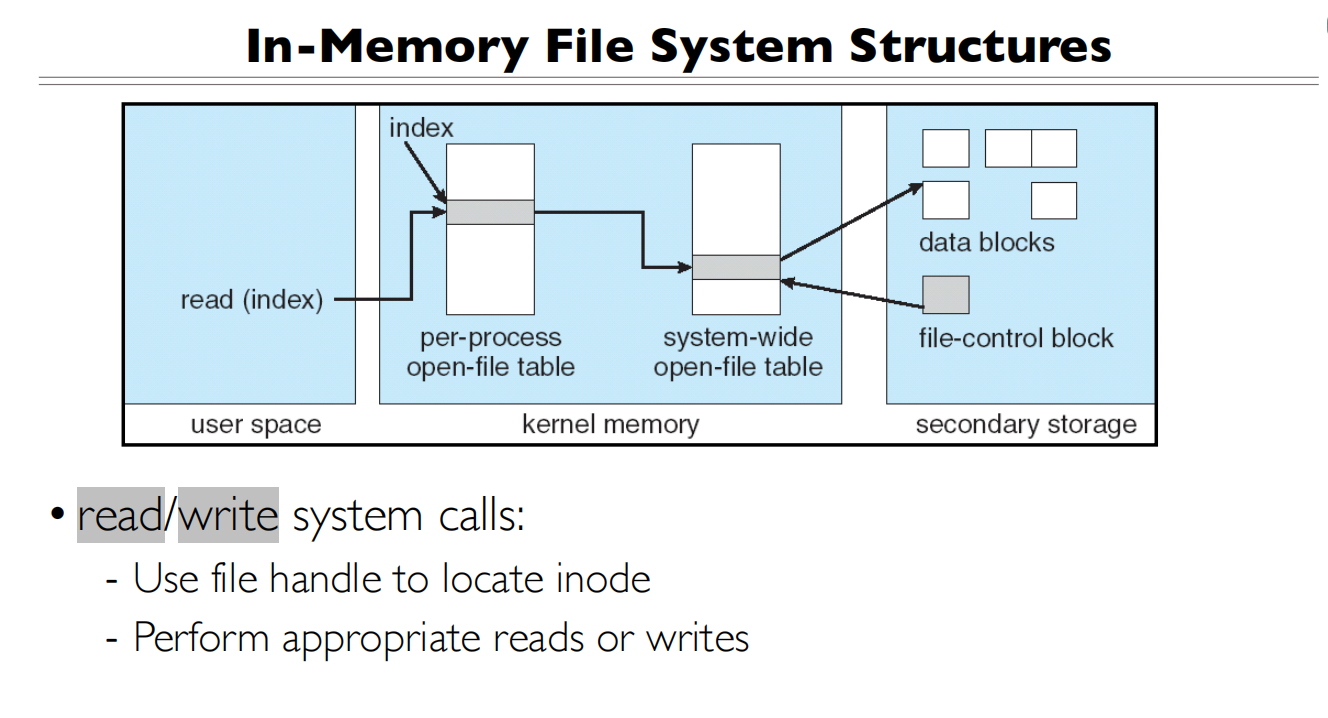
File System

Directories

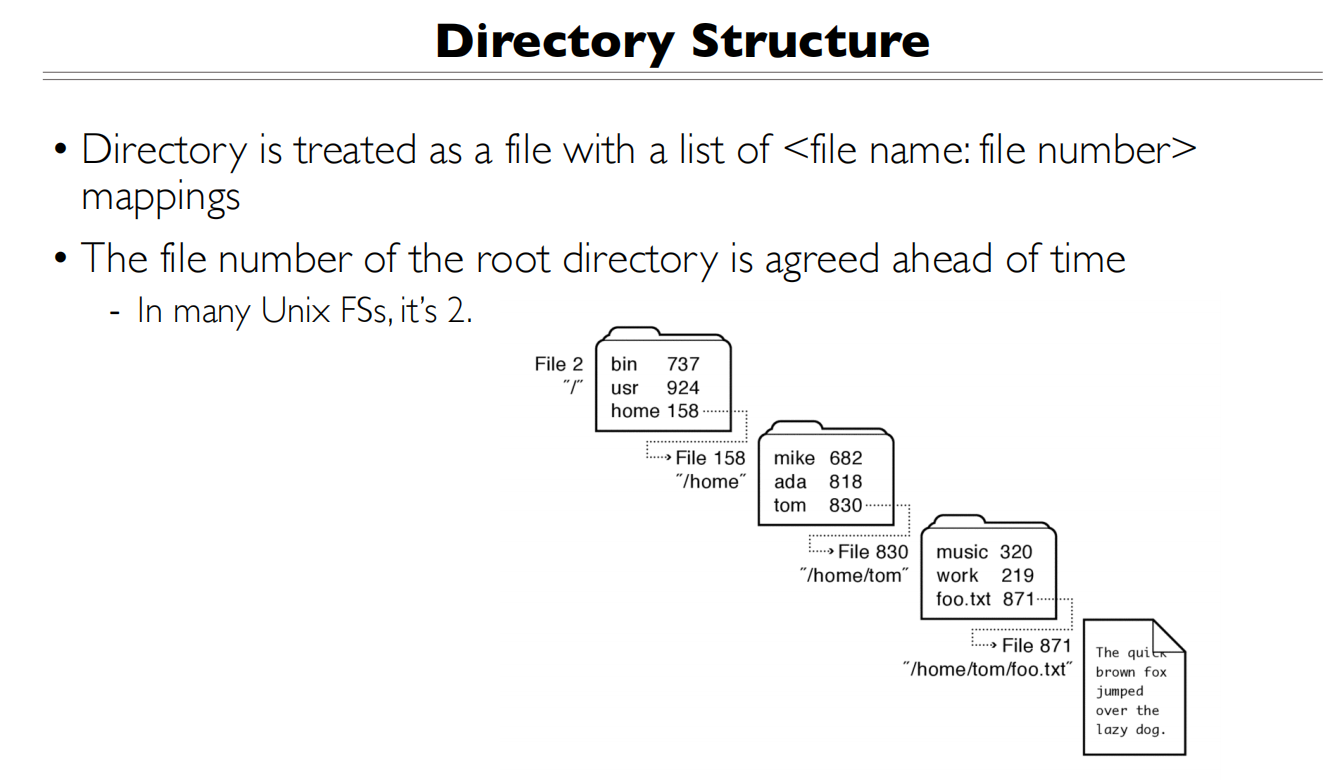 这是解析文件名的一个过程,后面会详细讲解
这是解析文件名的一个过程,后面会详细讲解
 如果没有文件对应Inode,那么文件就会被自动删除
如果没有文件对应Inode,那么文件就会被自动删除
 链表的查找速度太慢了,改用树
链表的查找速度太慢了,改用树
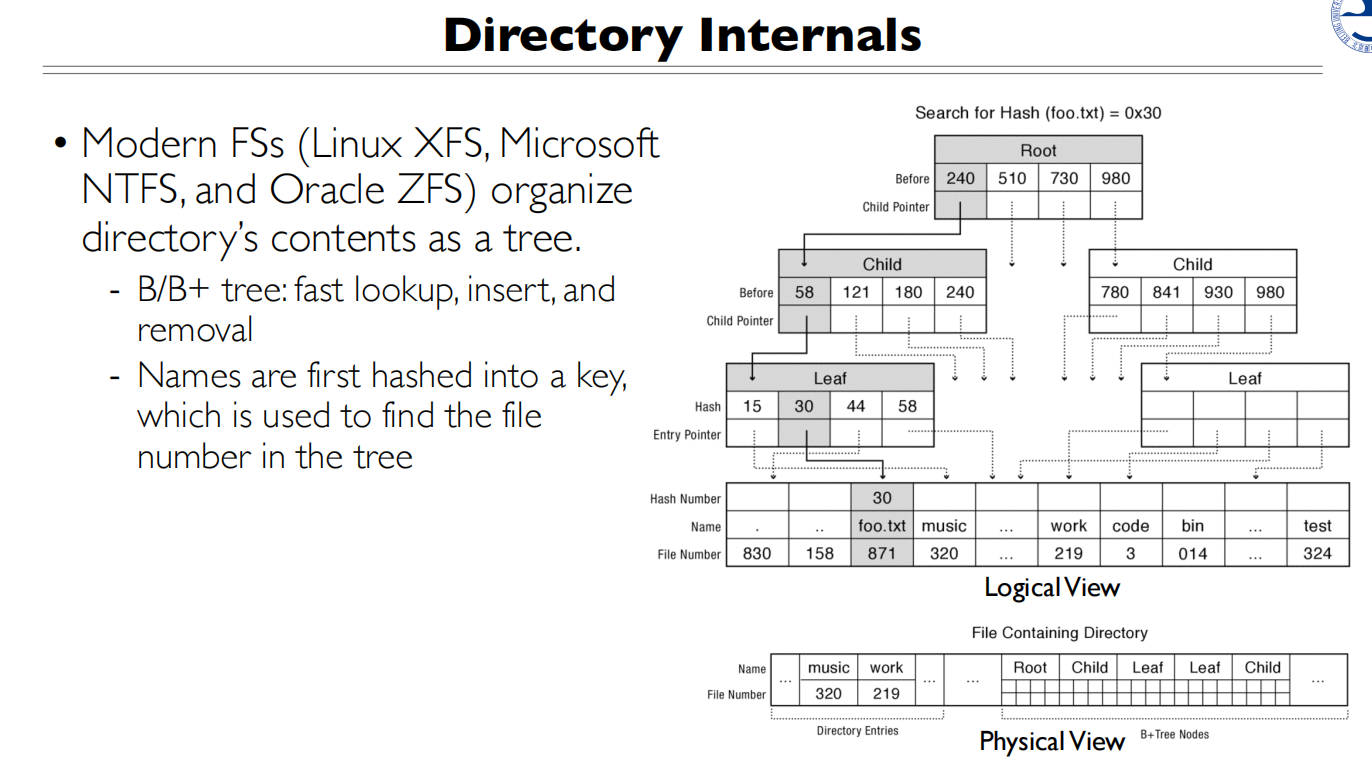
 要访问多少次磁盘?
要访问多少次磁盘?
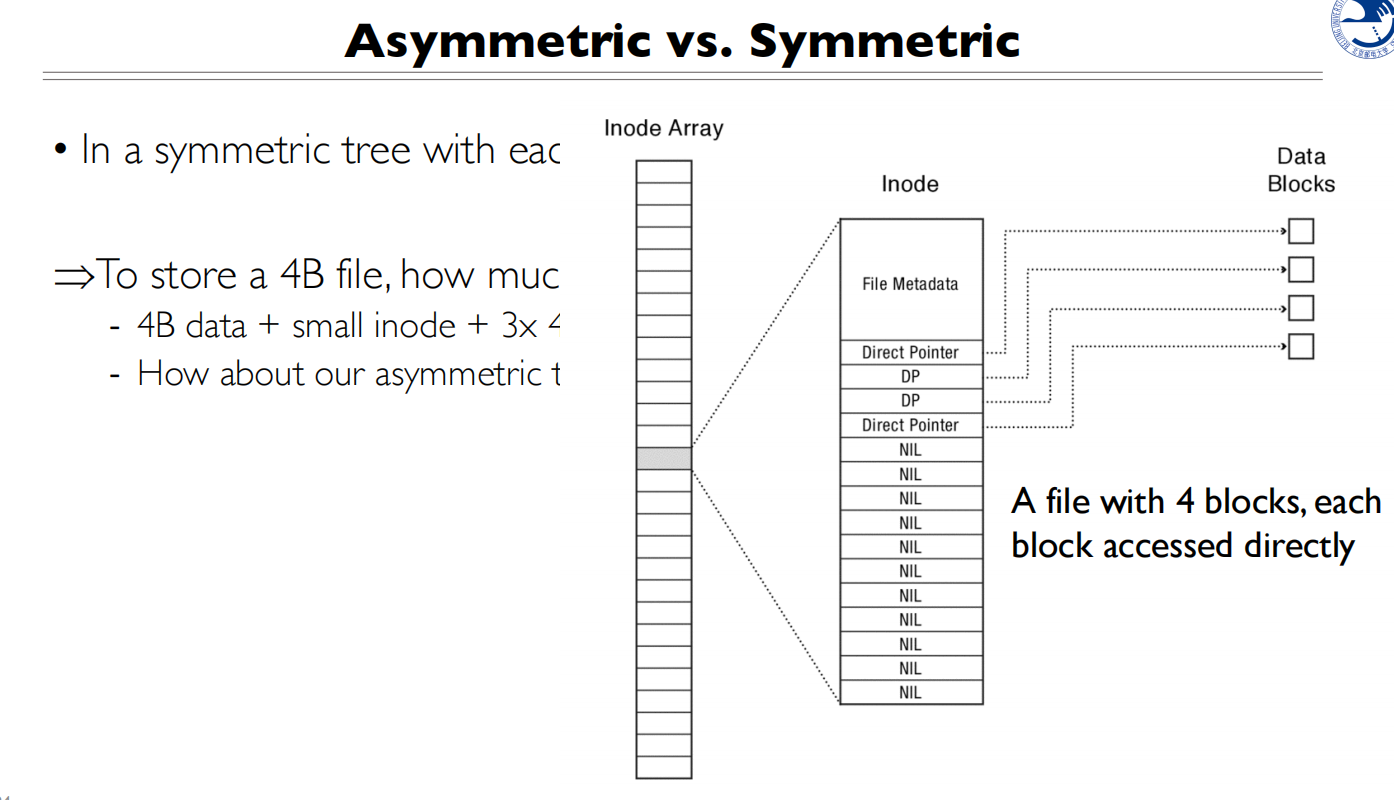
文件头和数据会分开放
软硬连接
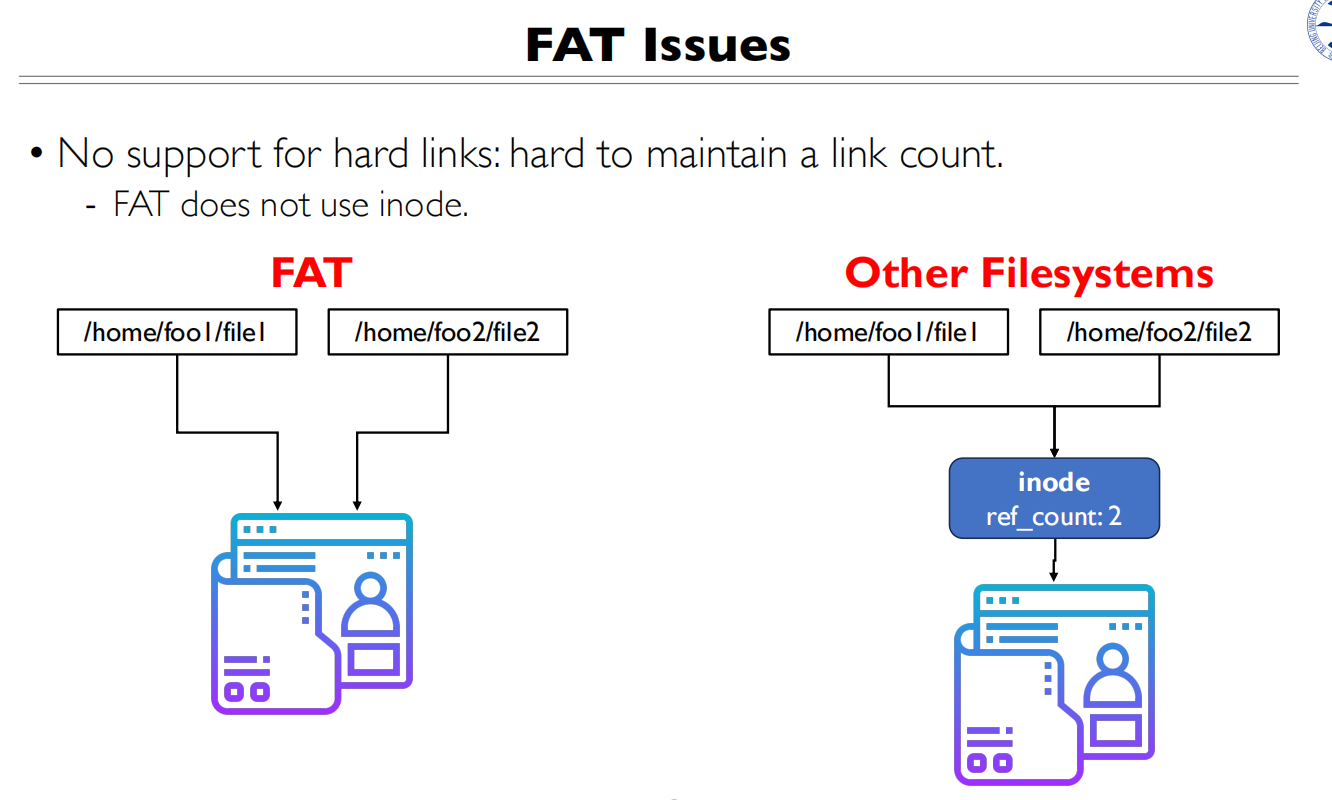
 两个文件的Inode号相同,有两个Inode指向同一个物理文件,删除一个另一个还能继续读,文件类型都是-或者d
两个文件的Inode号相同,有两个Inode指向同一个物理文件,删除一个另一个还能继续读,文件类型都是-或者d
OS会记录物理文件的Inode数量,当数量为0的时候才会删除
 软连接是一种特殊的文件类型,Inode和连接的文件不同,文件类型是l
软连接是一种特殊的文件类型,Inode和连接的文件不同,文件类型是l
 软连接存储的数据是被连接文件的文件名
软连接存储的数据是被连接文件的文件名

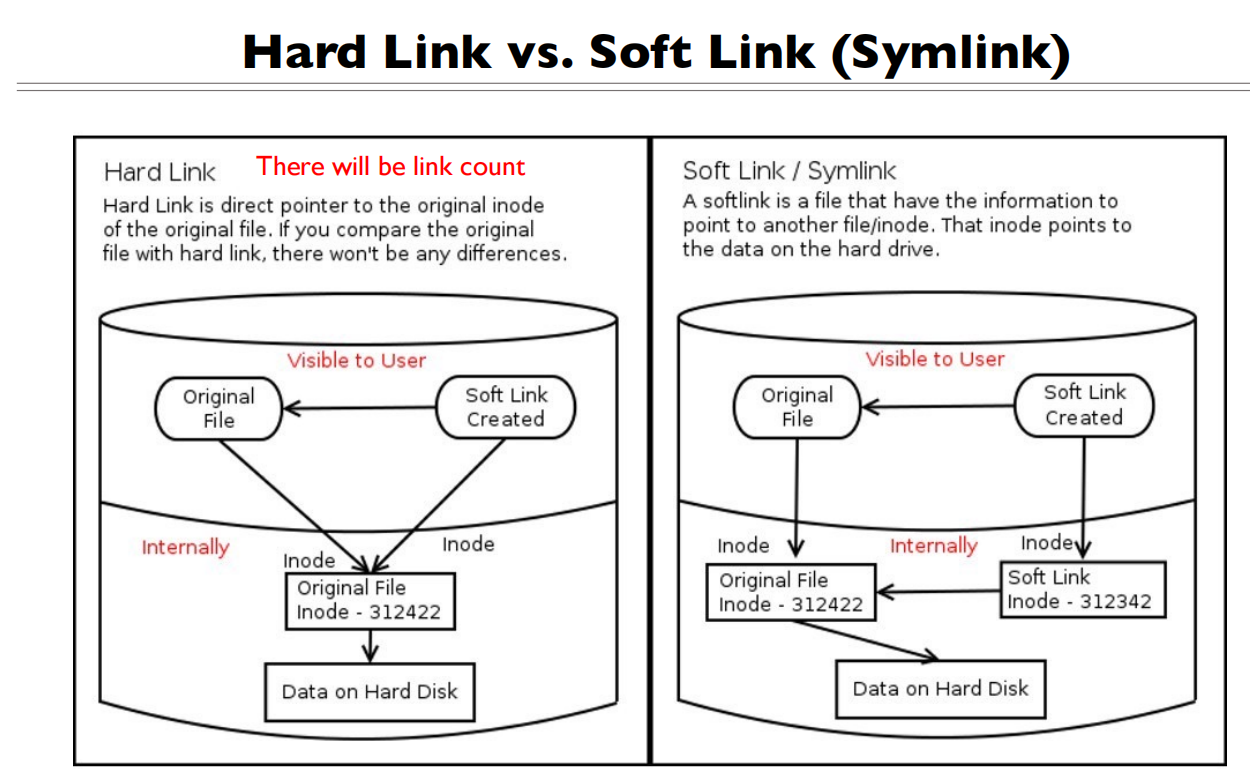 左图的右边的块是Hard Link,写错了
左图的右边的块是Hard Link,写错了
软连接有独立的Inode,硬连接的Inode相同
 硬连接做版本控制,软连接做快照
硬连接做版本控制,软连接做快照
FAT(File Allocation Table)
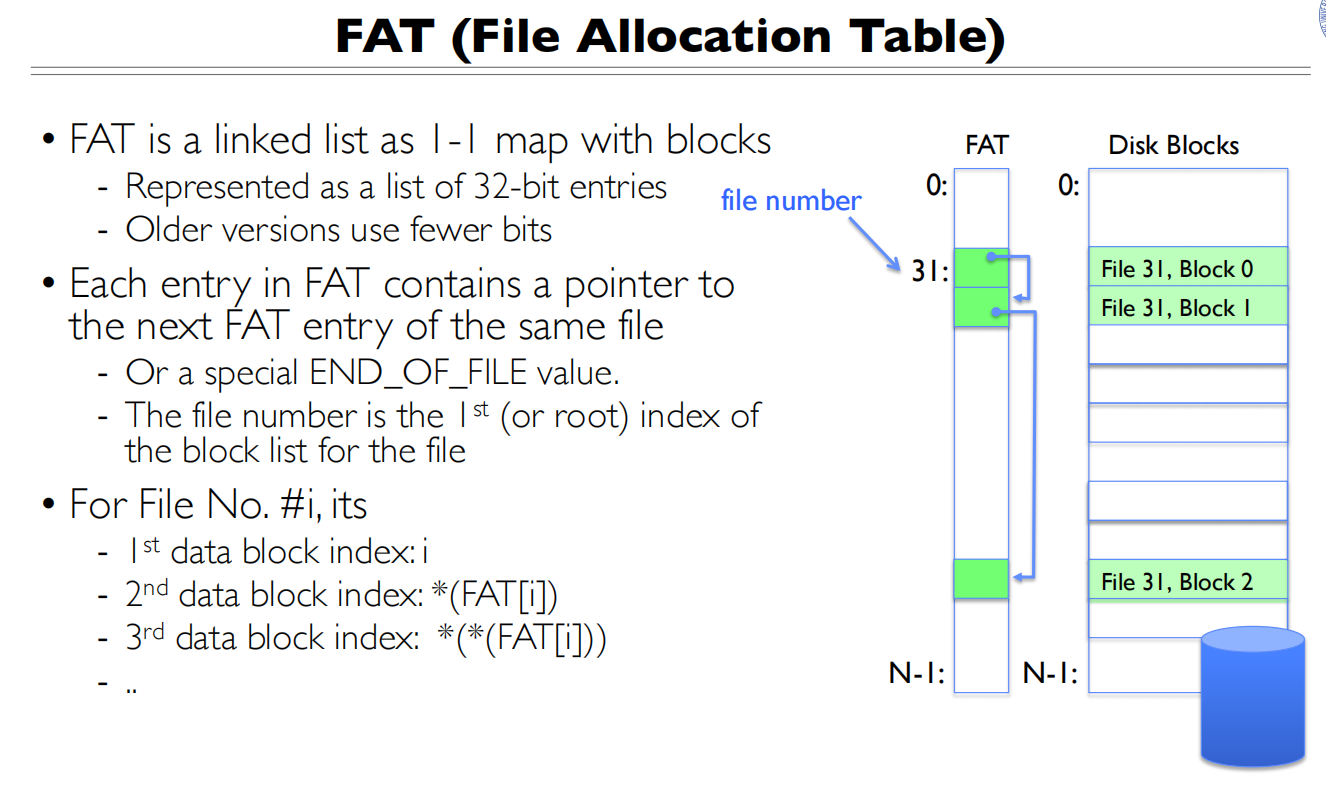 本质上用的是一个数组,将表和磁盘中的数据块做一一映射
本质上用的是一个数组,将表和磁盘中的数据块做一一映射
文件号就是第一个数据块的位置,然后有指向下一个数据块对应的位置的指针
文件尾部用END_OF_FILE代替
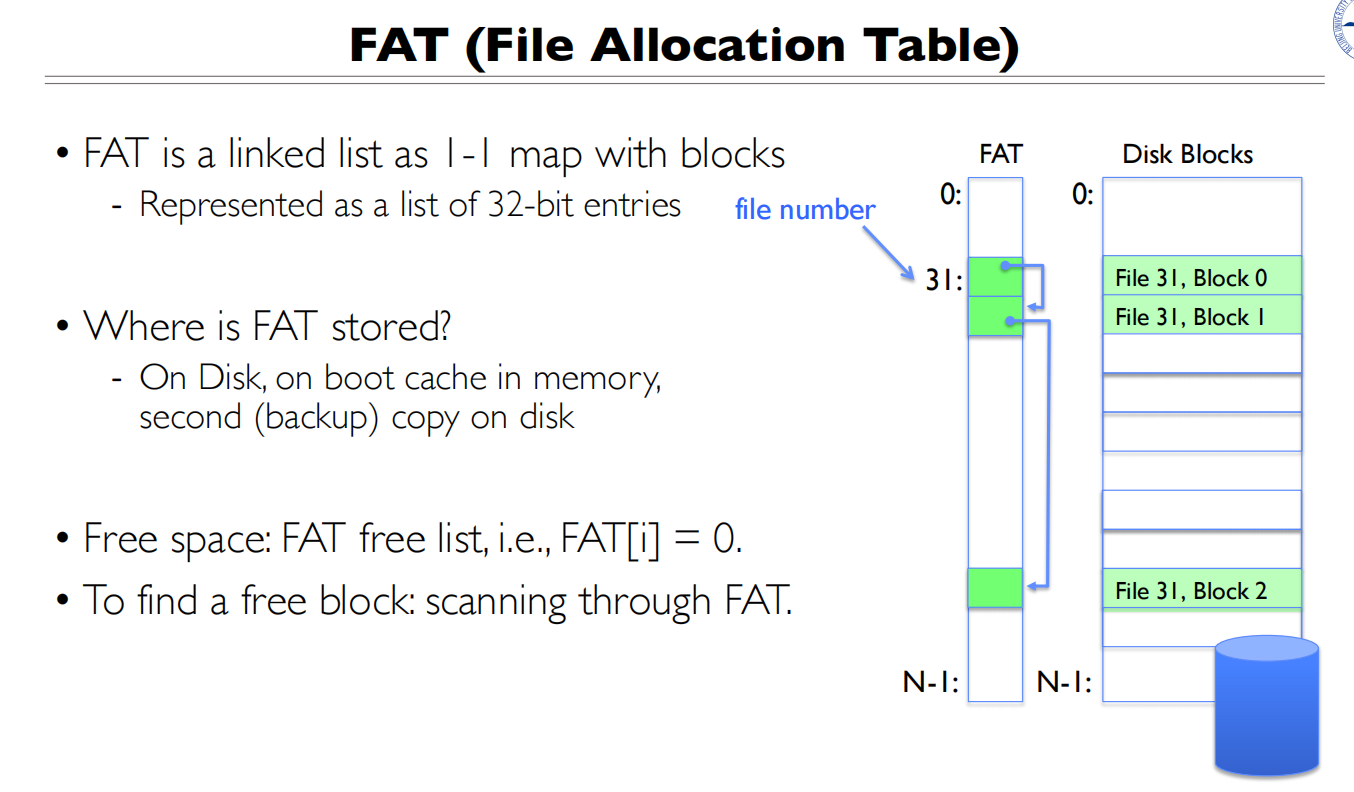 FAT 存在磁盘,在boot cache
FAT 存在磁盘,在boot cache
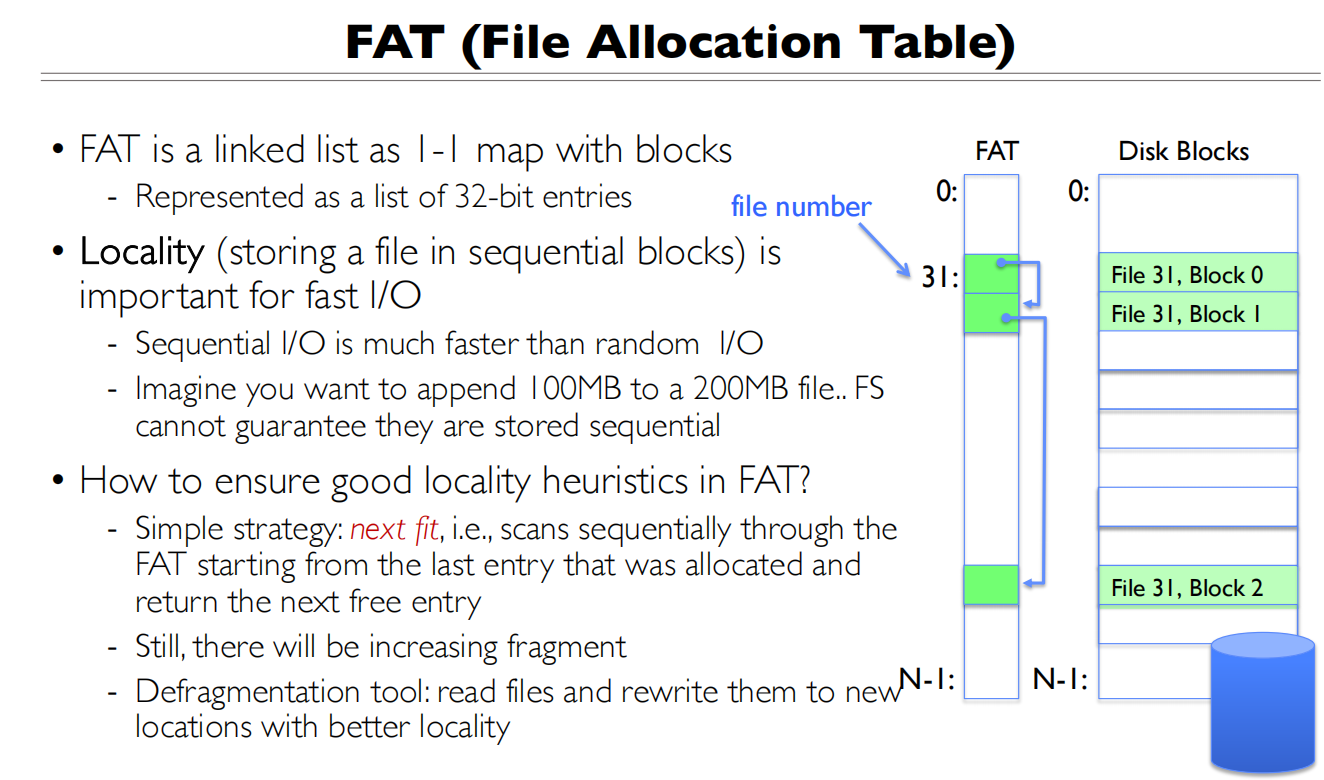 Locality是最难的点,我们希望文件系统能连续存储(读取快),但是文件的分配是不连续的
Locality是最难的点,我们希望文件系统能连续存储(读取快),但是文件的分配是不连续的
Next fit的算法,找到当前文件最后一个块的下一个空闲块
随着文件的增删,会存在碎片化
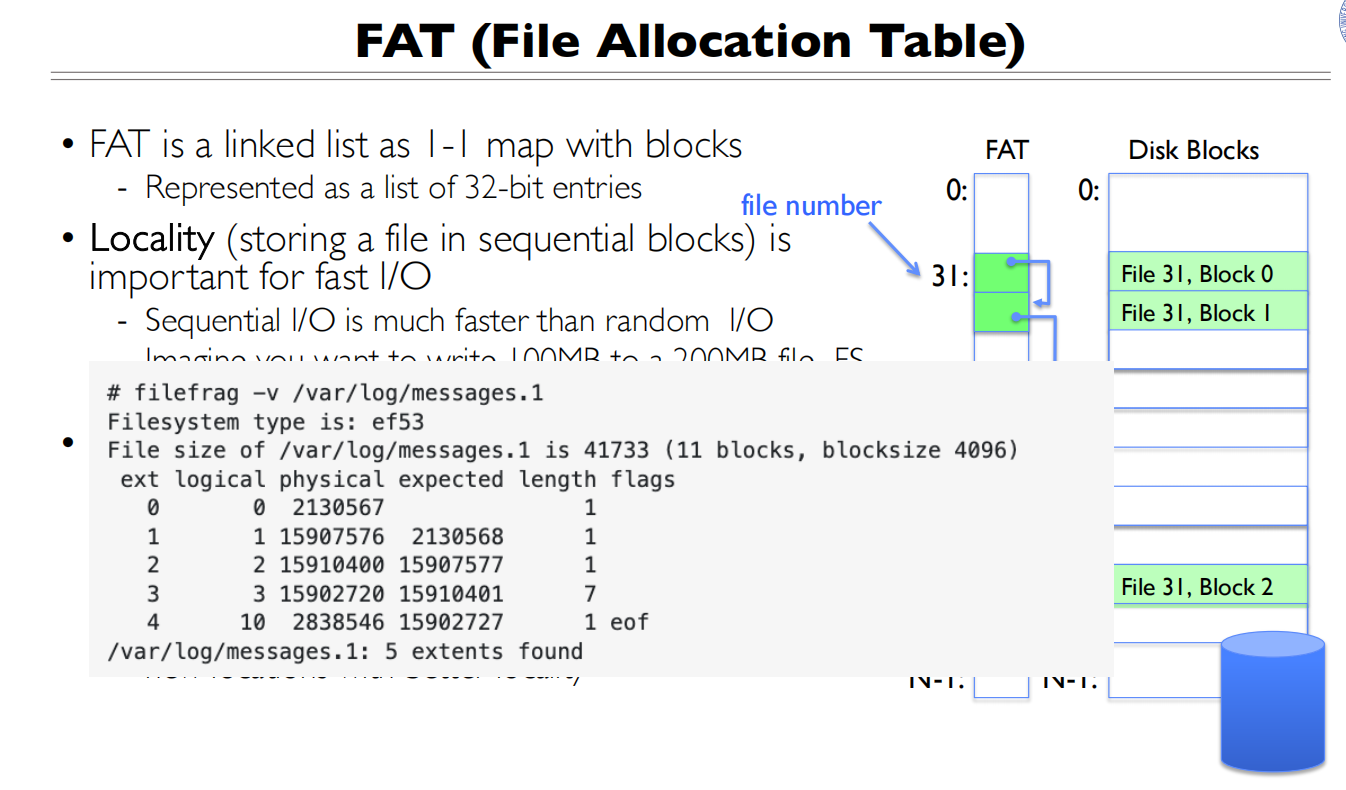
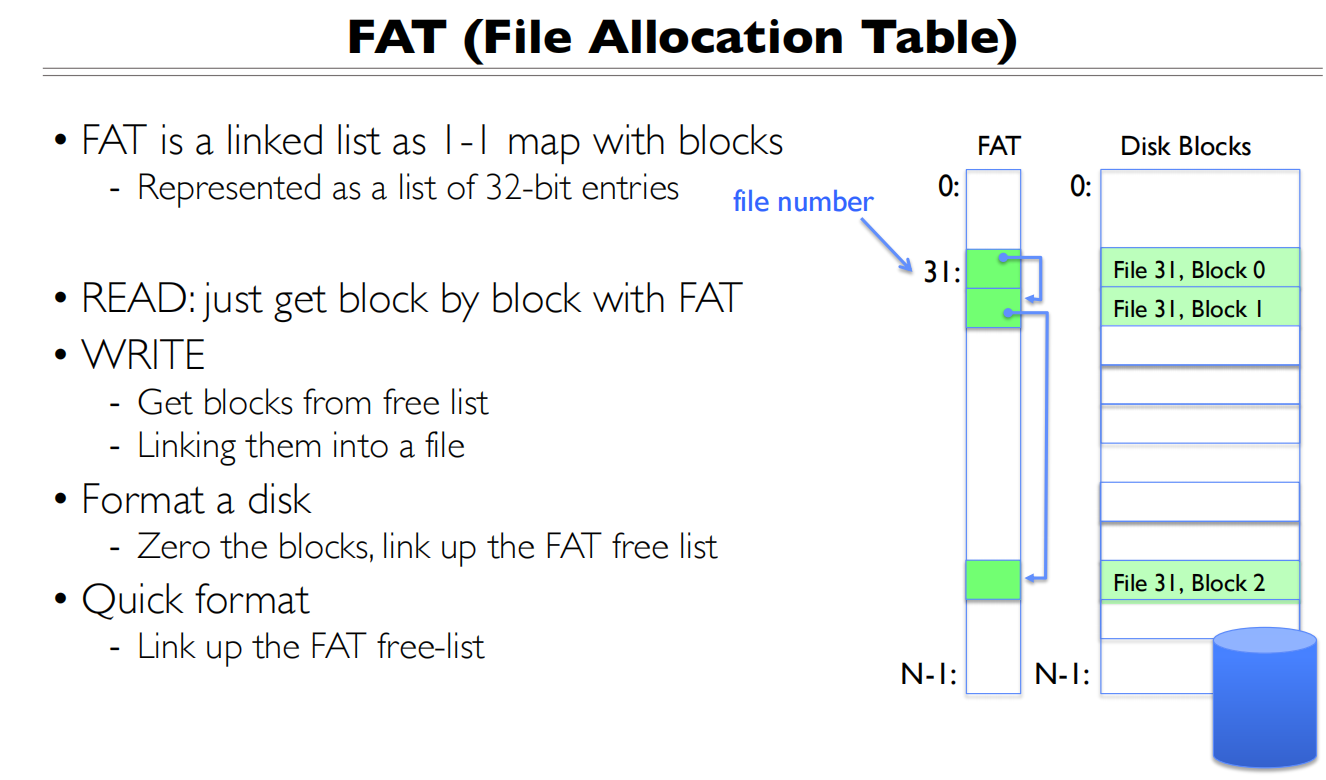 FAT表是没有Inode的设计的
FAT表是没有Inode的设计的
FAT的一些问题
 目录项用32bit 存储大小,所以是
目录项用32bit 存储大小,所以是
随机读会慢,因为需要顺序地遍历FAT表 4GB的文件随机读需要访问100w次FAT表
没有Inode,相关信息是存在了FAT表内的
BSD/FFS


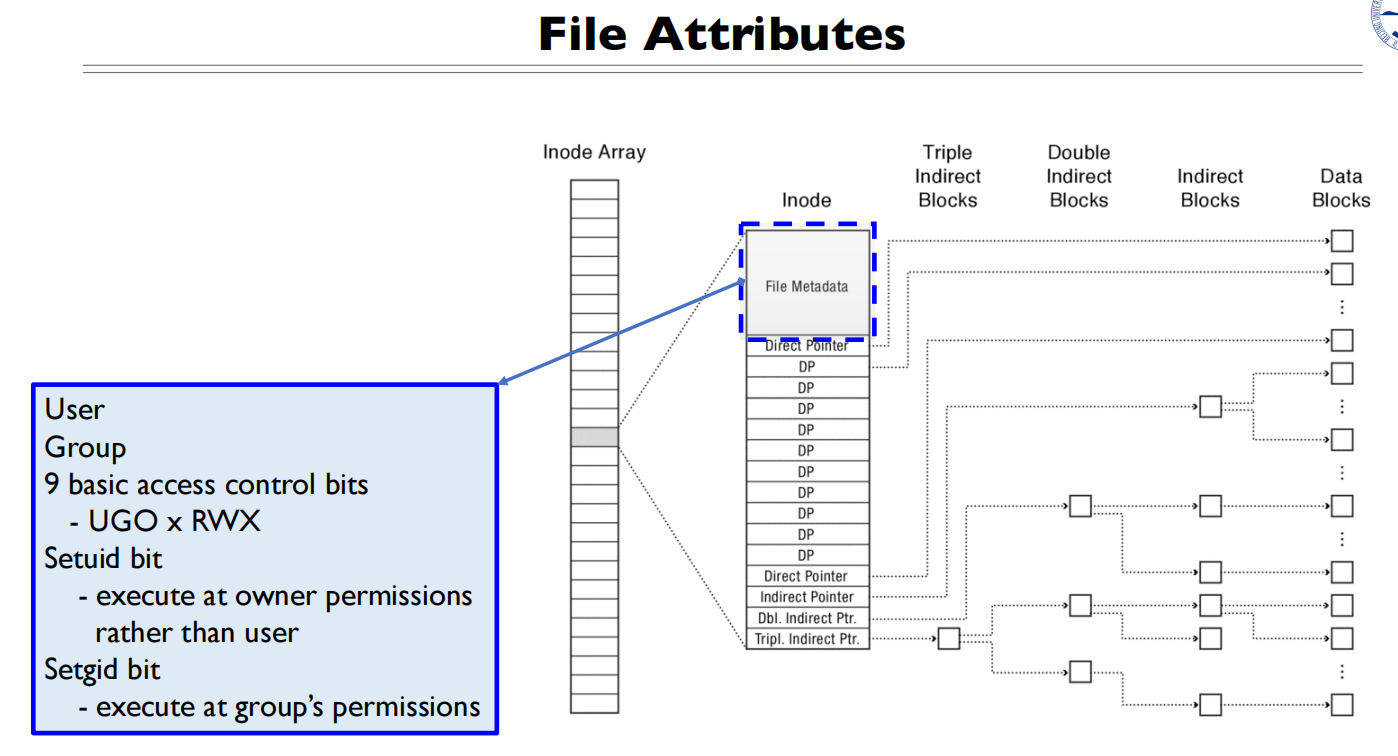 每个文件号映射到一个Inode数组
每个文件号映射到一个Inode数组
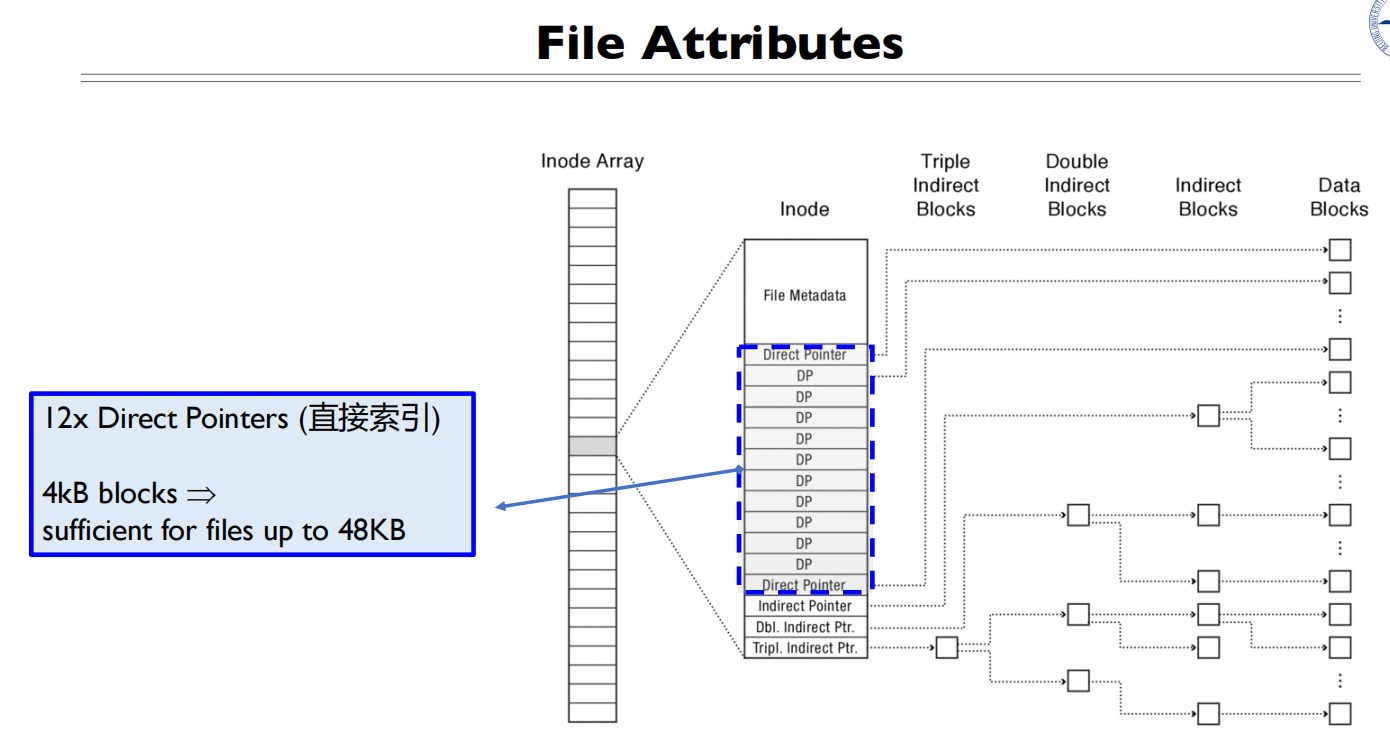
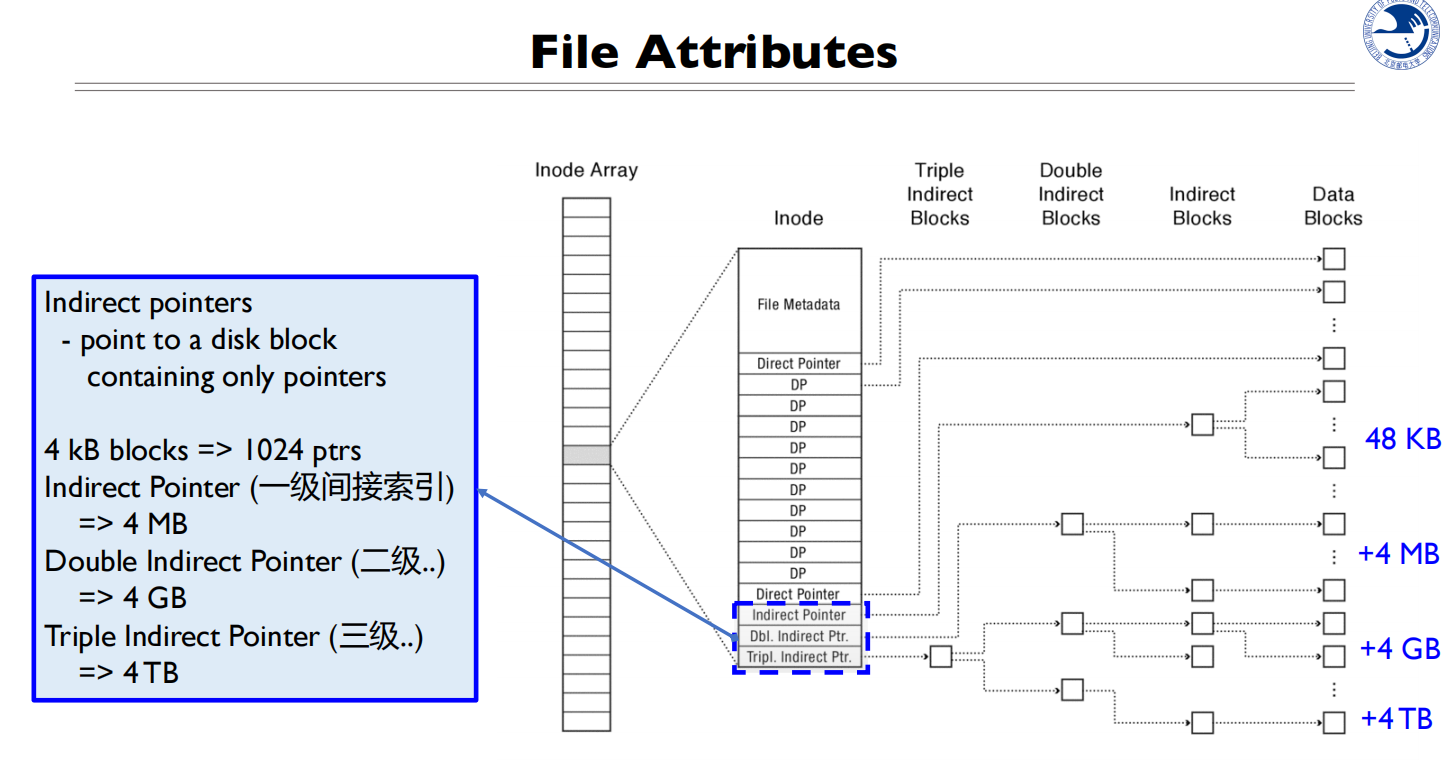
- 12个直接索引,指向12个Block,一共48KB(一个block 4KB)
- 1个一级间接索引,指向1个装满指针的block,一个指针4 byte,所以有1024个指针,所以一共是
- 1个二级间接索引
- 1个三级间接索引
一个文件最大可以有4TB+4GB+4MB=48KB
整个文件系统支持

 一个Inode:File MetaData+12个直接指针+1个一级指针+1个二级指针+1个三级指针
一个Inode:File MetaData+12个直接指针+1个一级指针+1个二级指针+1个三级指针

 用bitmap来管理
用bitmap来管理
Inode存在哪里?
 Inode也是存在磁盘中的
Inode也是存在磁盘中的
早期的实现破坏了Inode和data的局部性,访问Inode一般就会访问对应的数据

 尽量连续,data block的号尽量连续
尽量连续,data block的号尽量连续
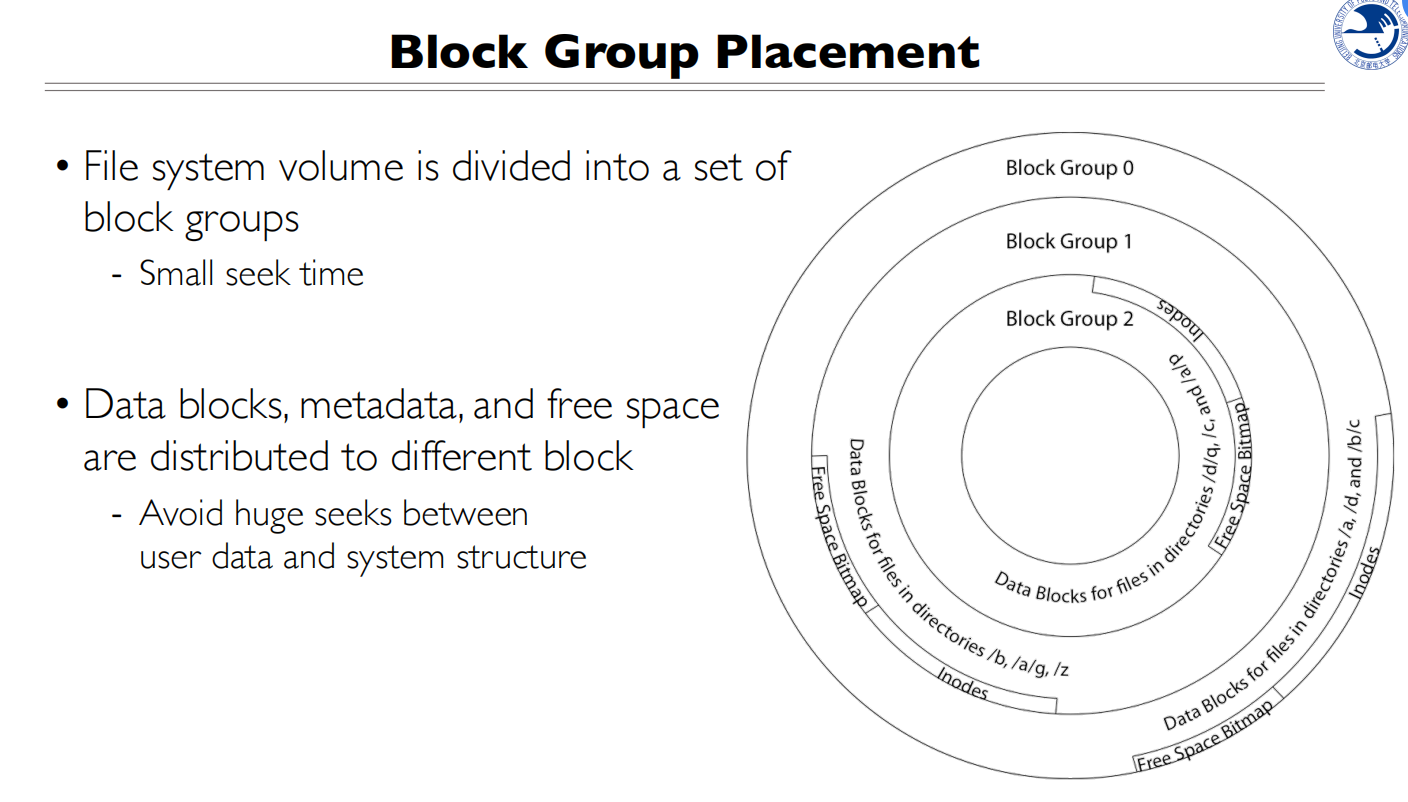 Inode和data block放在同一个group中
Inode和data block放在同一个group中
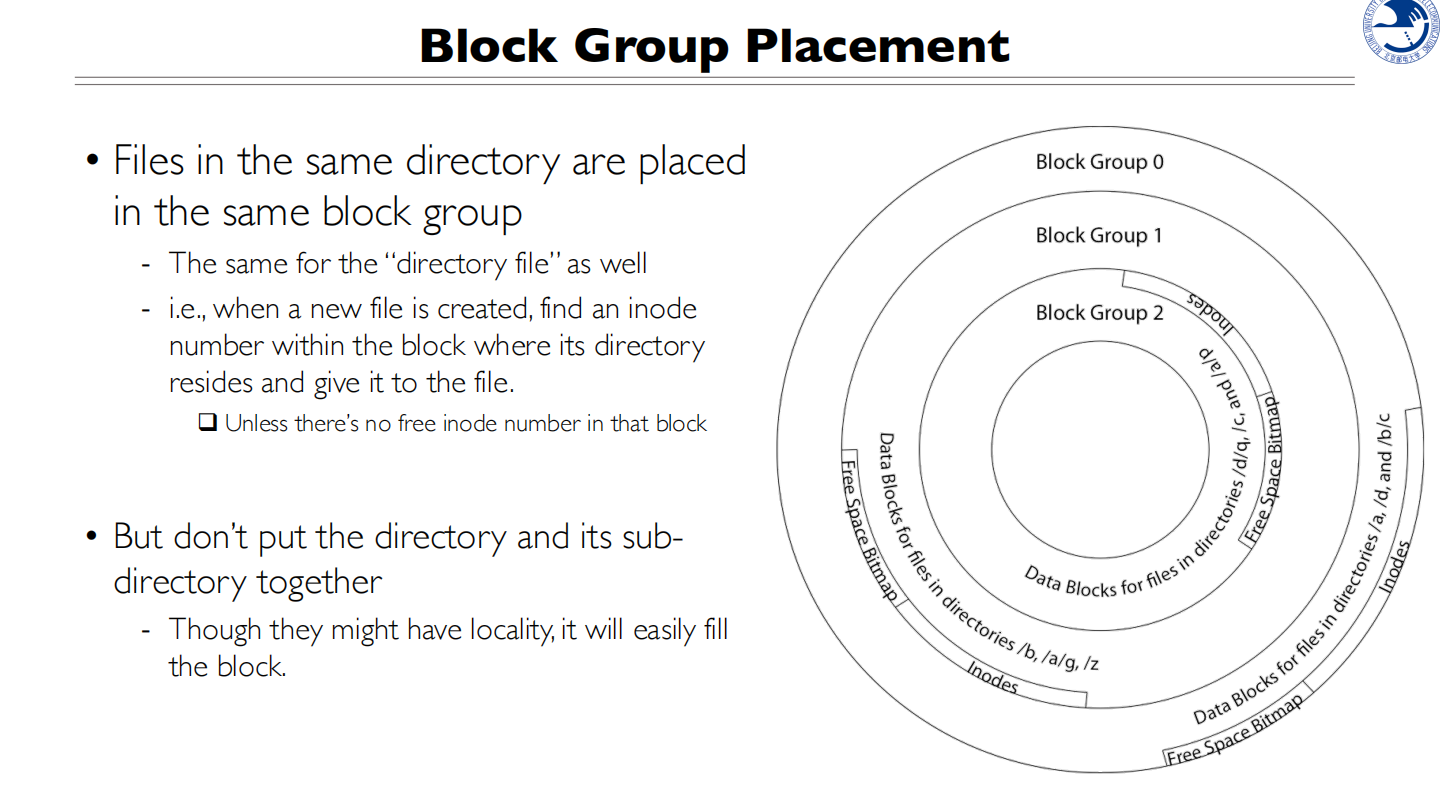 同一个目录下的文件放在同一个group 中,父目录和子目录会放在不同的group
同一个目录下的文件放在同一个group 中,父目录和子目录会放在不同的group
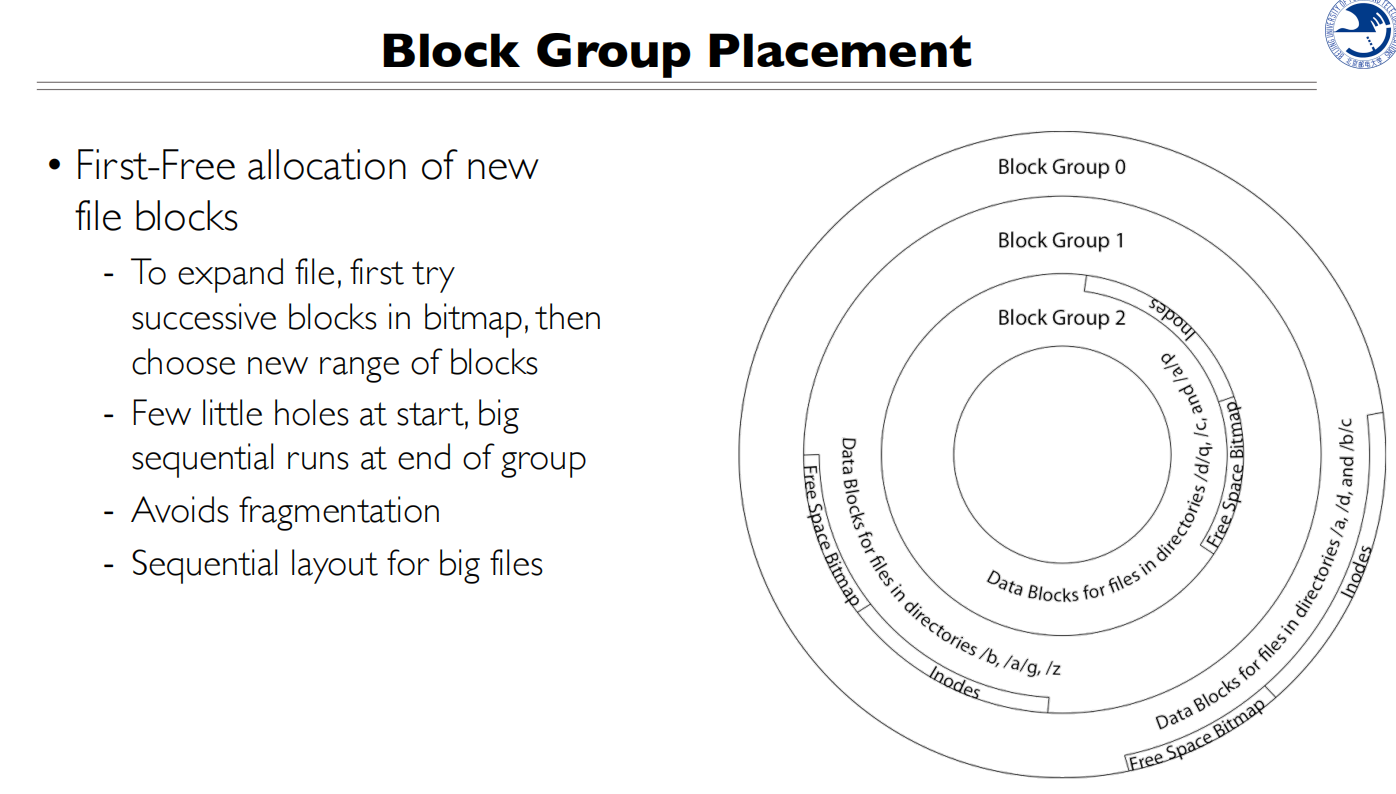
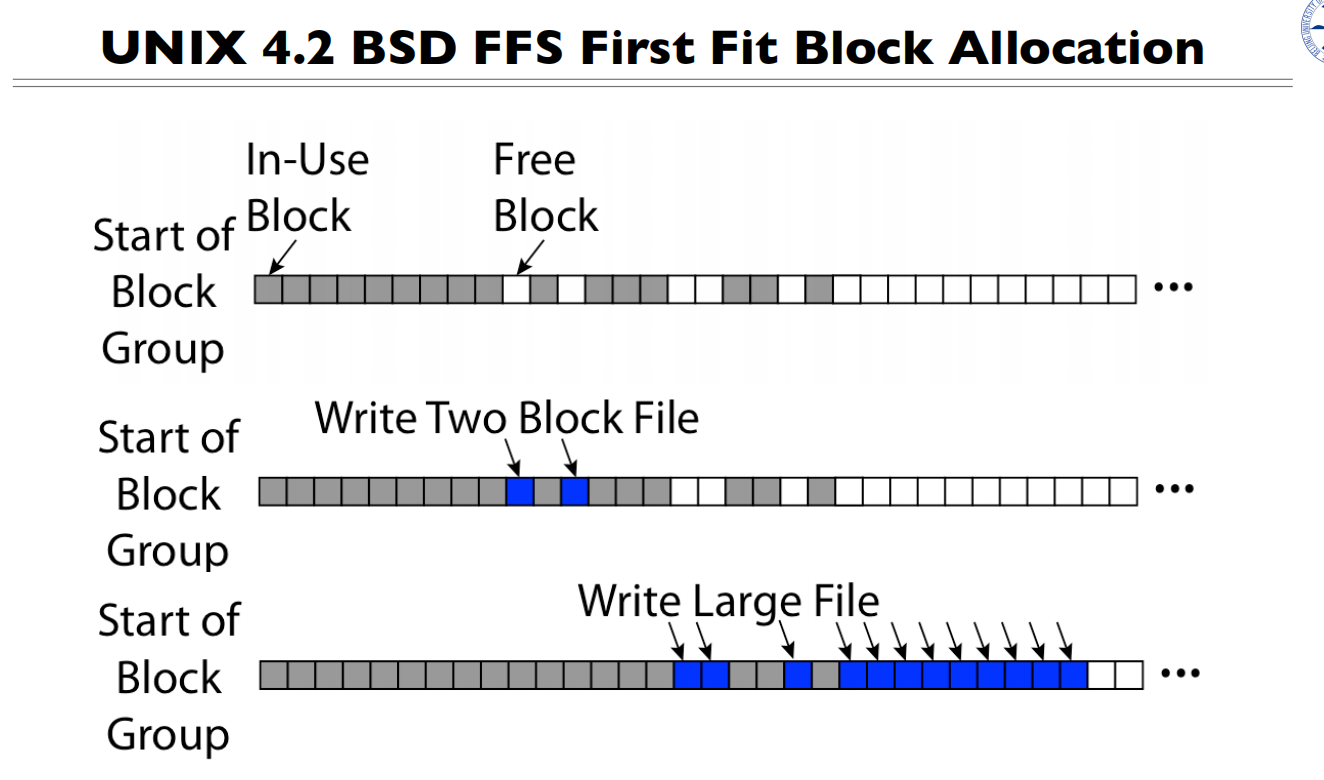 First fit,从头找到第一个空闲的块,会填掉洞,会越来越连续
First fit,从头找到第一个空闲的块,会填掉洞,会越来越连续
All
下面这个挺重要的
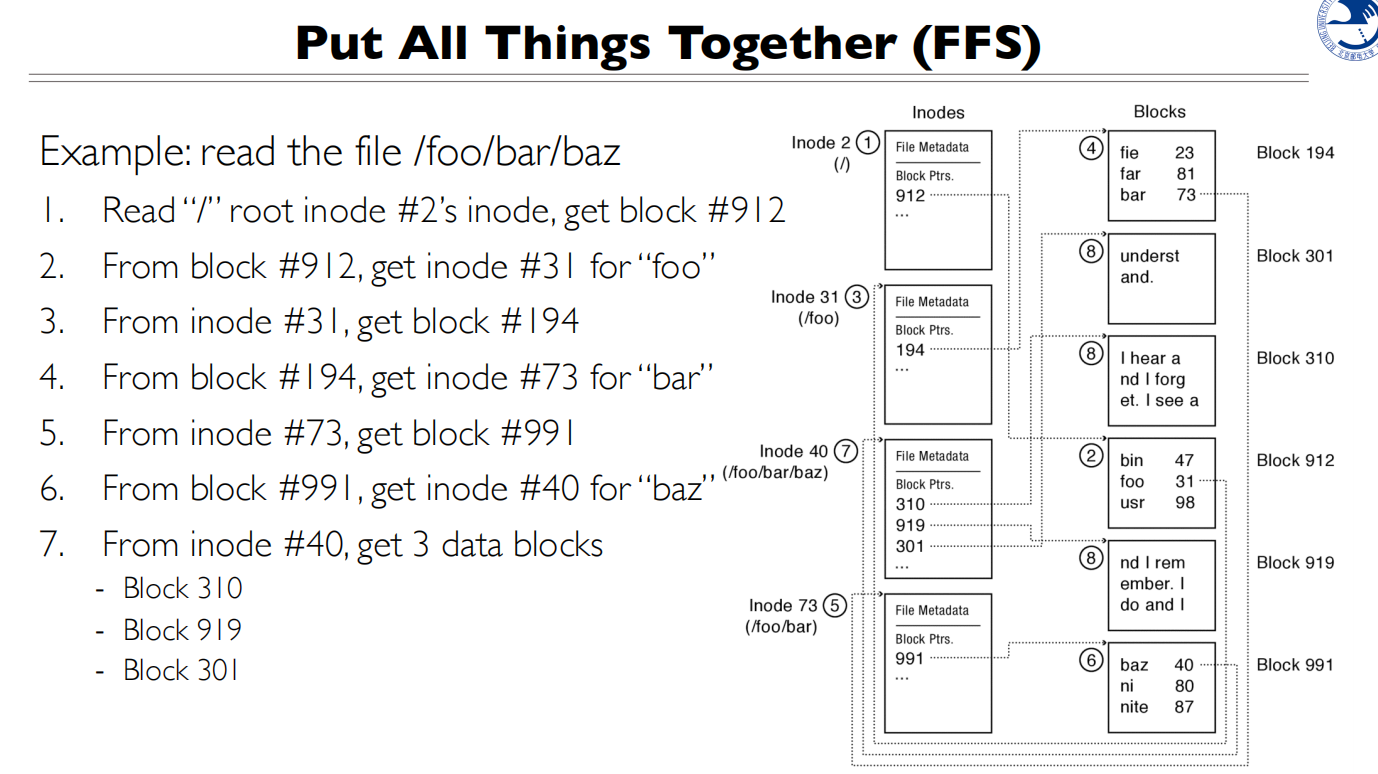 从Inode里面找到数据块,再从数据块读到文件号,根据文件号找到Inode
从Inode里面找到数据块,再从数据块读到文件号,根据文件号找到Inode
 缺点是对非常小的文件不高效,因为非常小的文件也需要Inode
缺点是对非常小的文件不高效,因为非常小的文件也需要Inode
NTFS
- New Technology File System (NTFS)
- Default on Microsoft Windows systems
- Variable length extents(变长的)
- Rather than fixed blocks
- Everything (almost) is a sequence of <attribute (属性):value> pairs
- Meta-data and data
- Mix direct and indirect freely
- Directories organized in B-tree structure by default
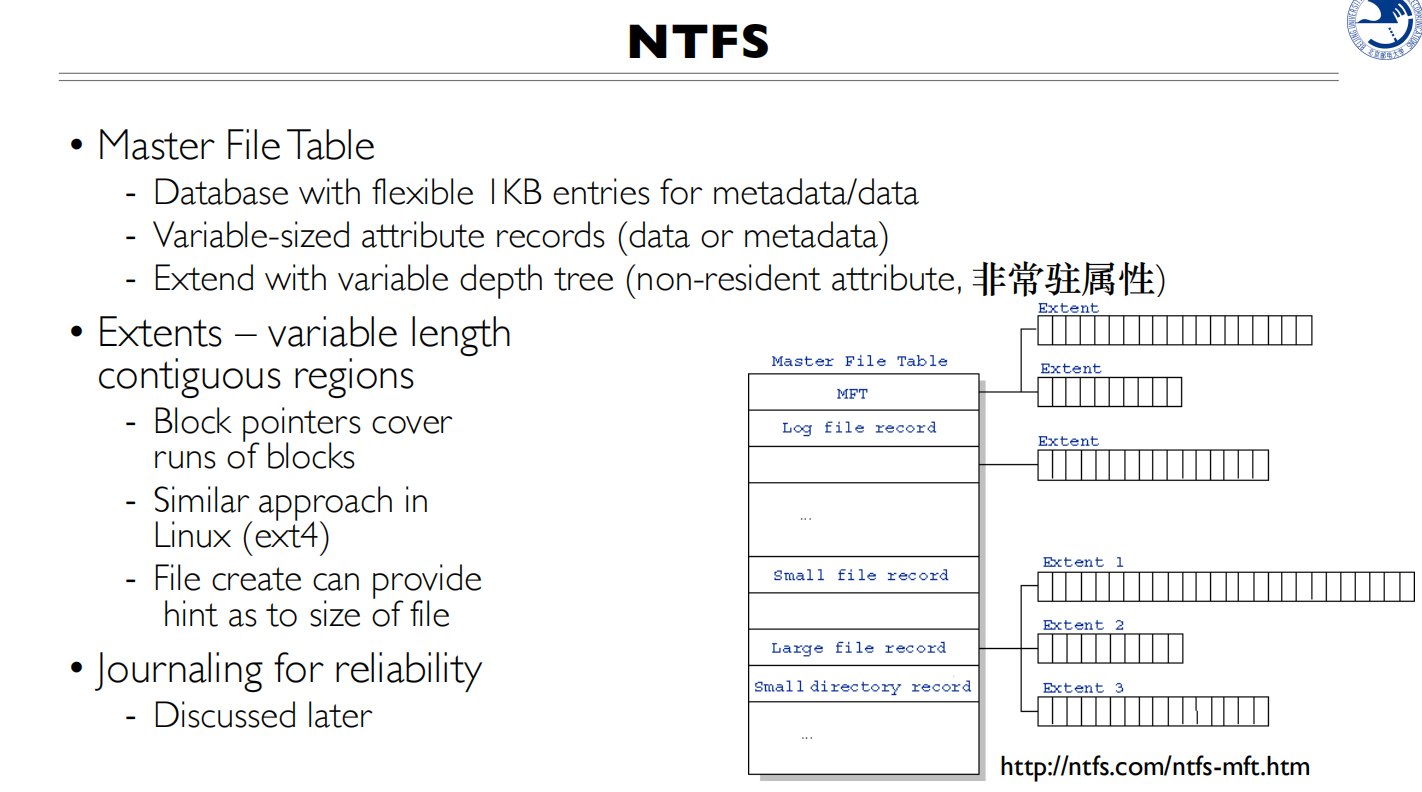 主文件表,每一项有1KB,不仅存储meta 信息,还会存储文件信息
主文件表,每一项有1KB,不仅存储meta 信息,还会存储文件信息
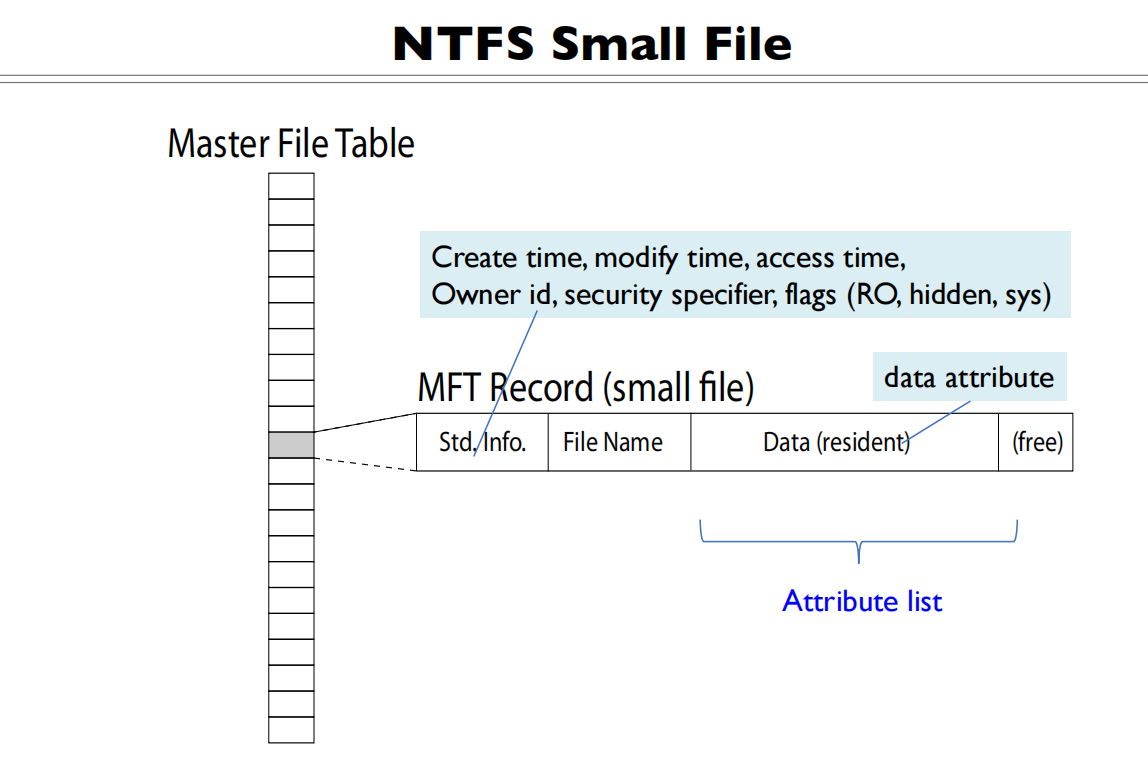 如果是小文件,直接存储到MFT的项里面
如果是小文件,直接存储到MFT的项里面
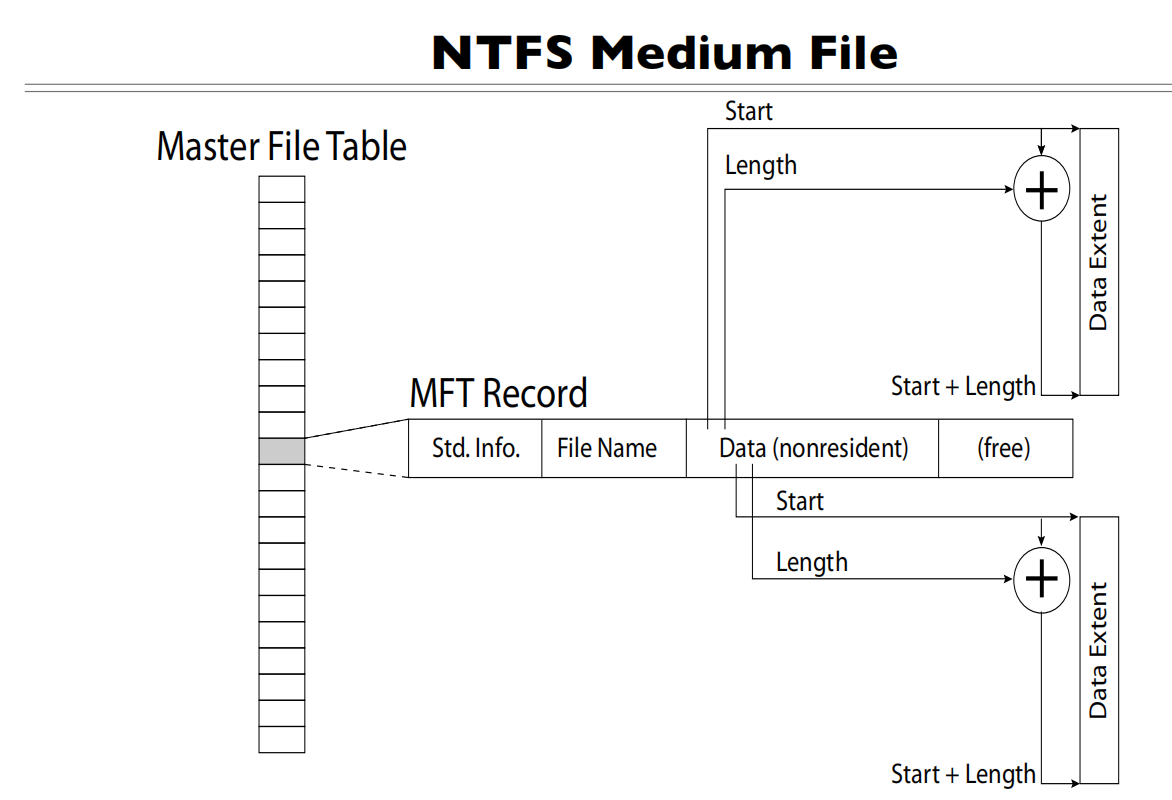 会分配多个段,在MFT表项的data里面
会分配多个段,在MFT表项的data里面
Important
在 NTFS 中,数据(Data)的分配采用称为”数据运行”(Data Runs)或”数据范围”(Data Extents)的机制。从图中可以看到,每个数据部分包含两个关键信息:
- Start(起始位置)
- Length(长度)
具体的分配机制如下:
- 非常驻属性(Nonresident Data):
当文件较大时,数据内容不会直接存储在 MFT 记录中
而是存储在磁盘的其他位置,通过数据运行来记录位置信息
- 数据运行的结构:
每个数据运行记录了一个连续的磁盘区域
Start 表示这段数据的起始簇号
Length 表示这段数据占用多少个簇
Start + Length 指向数据结束位置
- 多个数据运行:
一个文件可能会被分散存储在多个不连续的区域
每个区域都用一个数据运行来描述
这些数据运行形成一个列表,串联起整个文件的内容
- 优化策略:
- NTFS 会尽量将数据分配在连续的区域,以减少碎片
- 但当空间不足时,会使用多个不连续的数据运行
- 系统会通过碎片整理来优化这些数据的分布
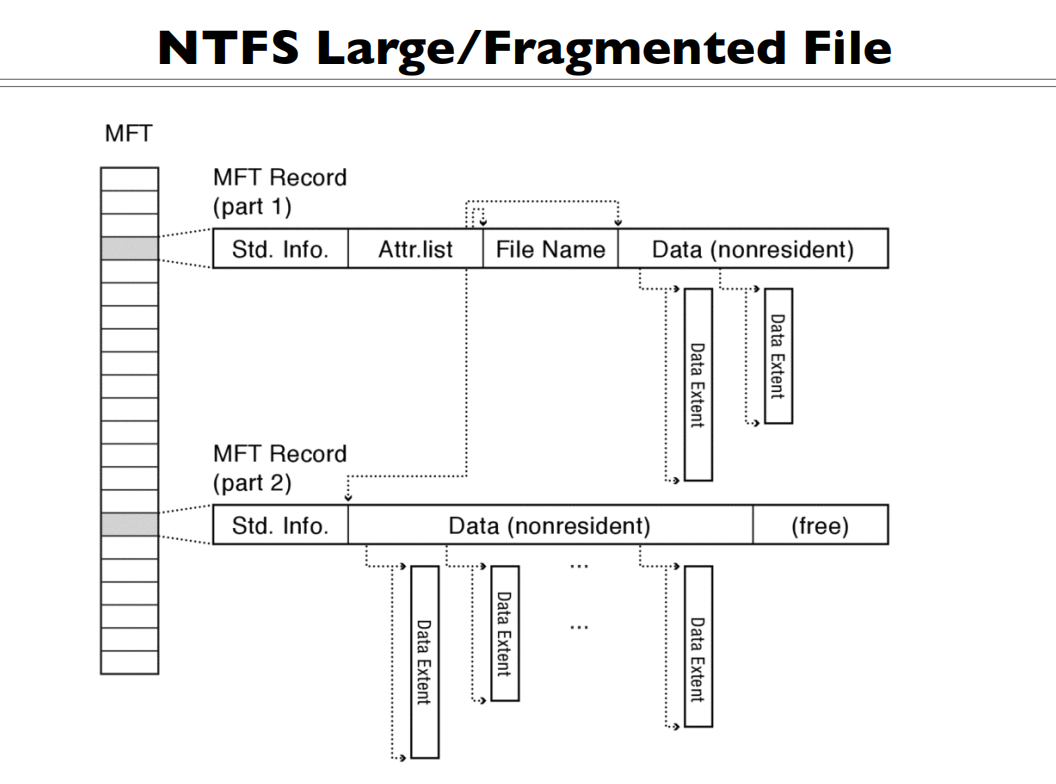 长度可变的话,什么时候会不够呢?碎片化的时候,大小动态变化
长度可变的话,什么时候会不够呢?碎片化的时候,大小动态变化
会新分配一个MFT的项
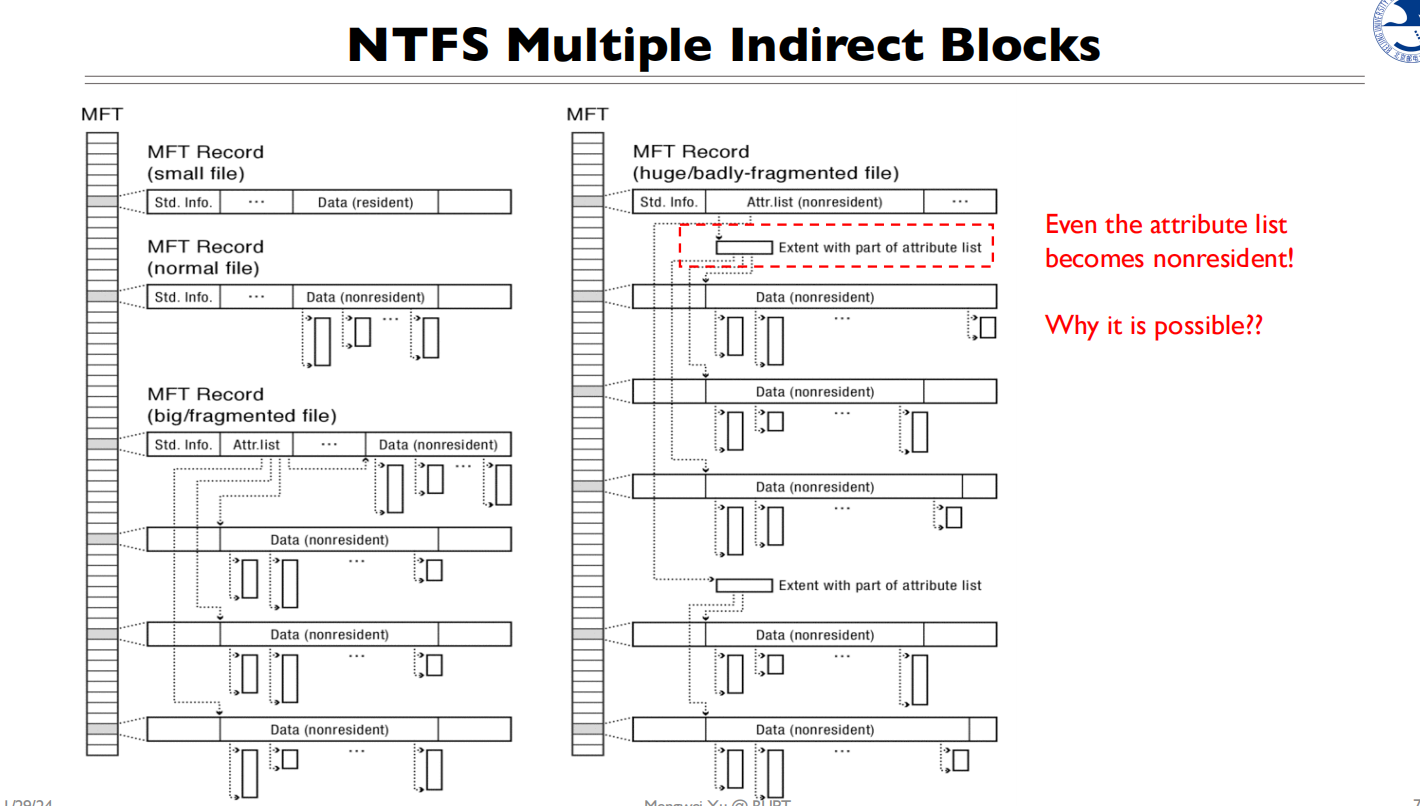
 Why?为什么要在NTFS卷的第一个扇区放一个指向MFT第一个条目的指针?
Why?为什么要在NTFS卷的第一个扇区放一个指向MFT第一个条目的指针?
这是因为MFT本身也是一个文件,我们称之为 $MFT。为了避免”鸡生蛋、蛋生鸡”的悖论:
- 如果想要读取MFT,就需要通过MFT找到它的位置
- 但要找到MFT的位置,又需要先读取MFT
所以NTFS的设计者在卷的第一个扇区(引导扇区)放置了一个指向MFT第一个条目的指针,这样:
- 系统启动时首先能找到并读取这个指针
- 通过这个指针找到MFT的第一个条目
- 然后就可以读取整个MFT文件了
这打破了循环依赖,提供了一个固定的、已知的起点来访问文件系统的核心数据结构。
 如何分配新的空间?
如何分配新的空间?
- 选一个比需求大的最小的空间(防止碎片化问题)
但是OS一般不知道需求,可以有buffer,NTFS会给用户一个函数,写的大小
MMap
 操作文件的时候不需要去读写文件,只需要去操作内存;
操作文件的时候不需要去读写文件,只需要去操作内存;
经典应用是执行一个程序,OS会将程序映射进内存
Summary
 文件系统:从文件名映射到文件号,从文件号映射到数据块
文件系统:从文件名映射到文件号,从文件号映射到数据块
