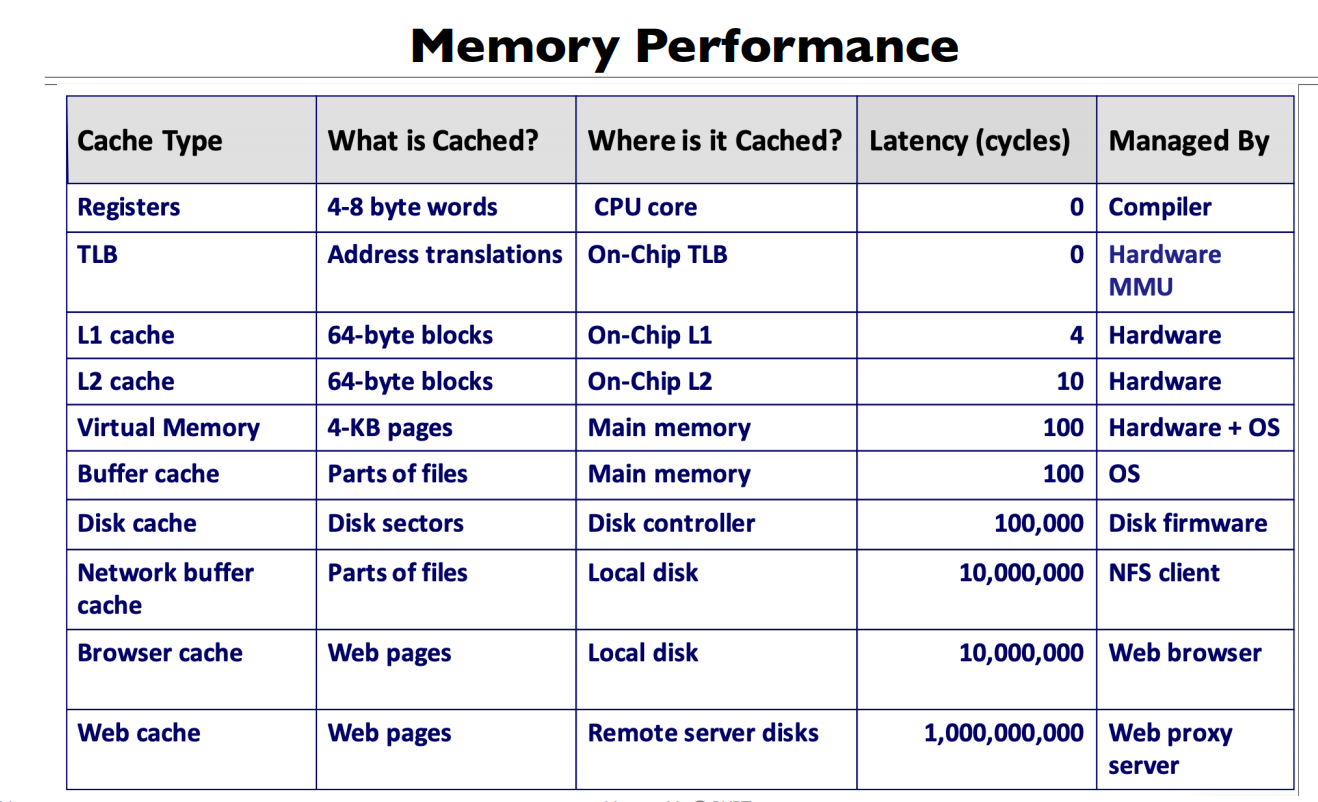
Cache Conecpts
 应该按照数据被访问的频繁度去放置数据的位置
应该按照数据被访问的频繁度去放置数据的位置
Why Cache?
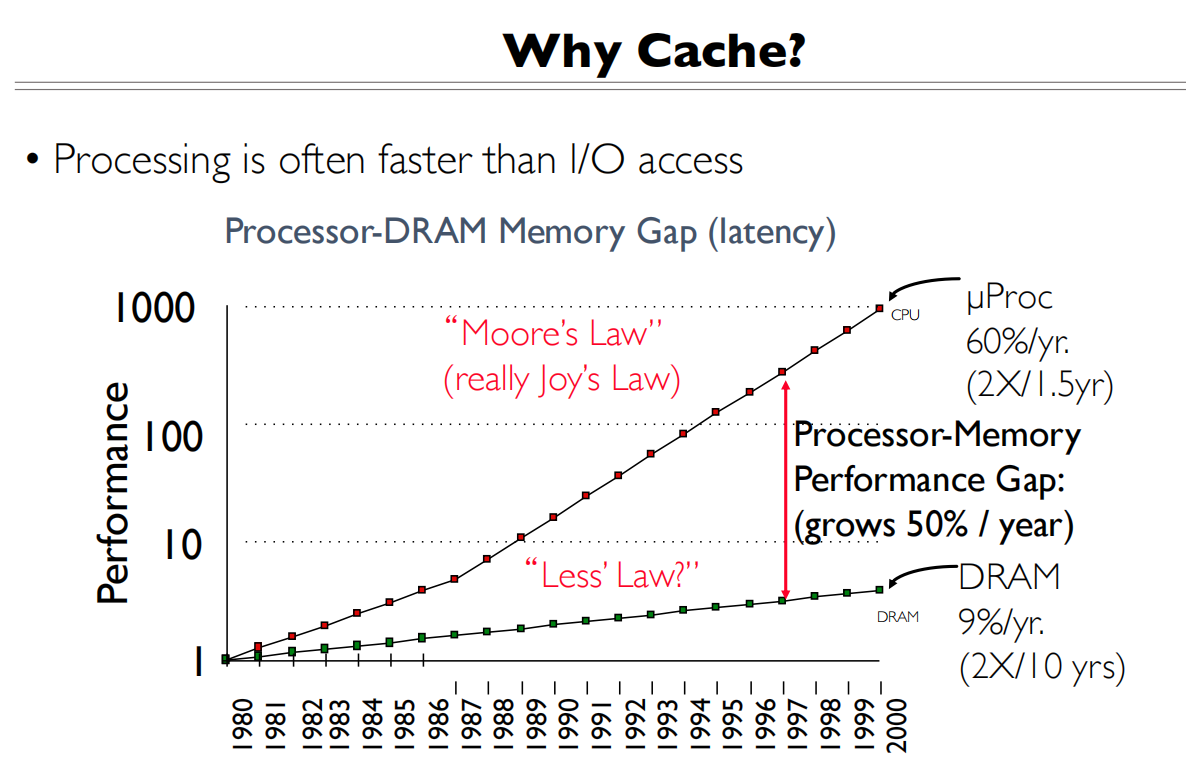 计算的提升速率比访存的提升快,所以我们需要提升访存
计算的提升速率比访存的提升快,所以我们需要提升访存
缓存能工作的假设:时空局部性
- Temporal locality(时间局部性):同一段数据在连续的时间内被多次访问
- Spatial locality(空间局部性):被访问数据附近的数据会被接着访问
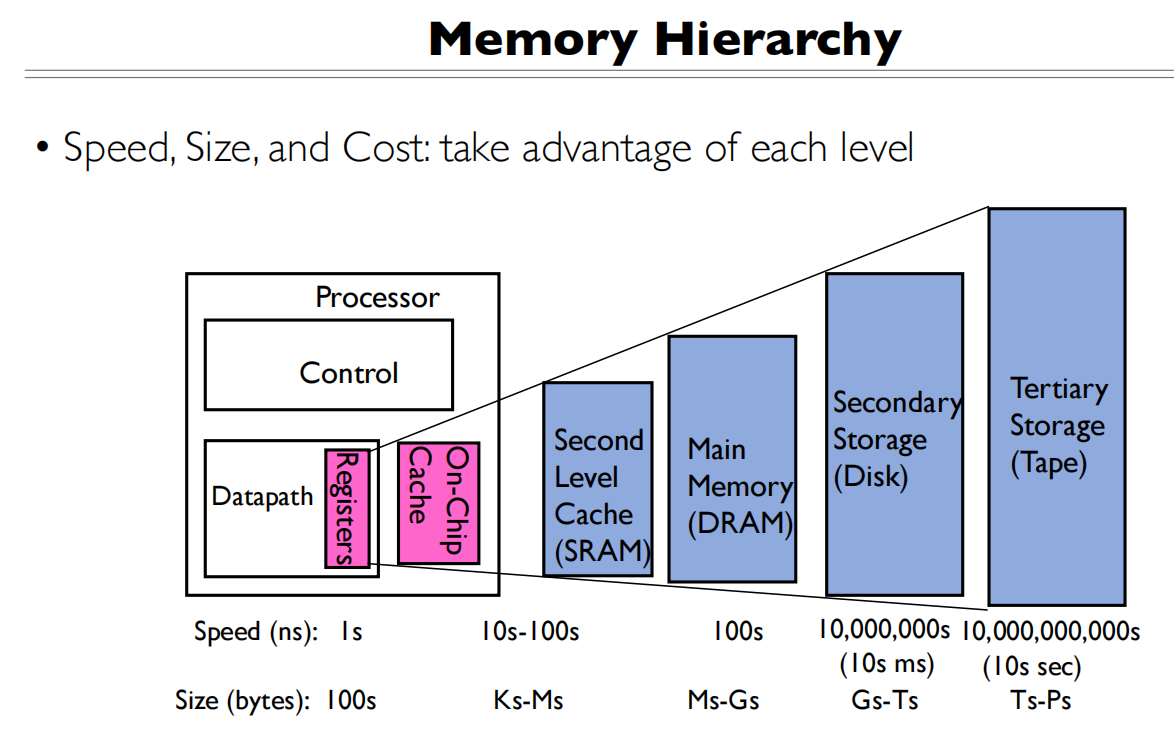 速度和数据量以及价格的衡量
速度和数据量以及价格的衡量
Direct use of caching techniques
- TLB (cache of PTEs)对虚拟地址到物理地址的关系的缓存
- Cache (cache of main memory, many levels)
- Paged virtual memory (memory as cache for disk)将内存当作对磁盘的cache
- File systems (cache disk blocks in memory)
- DNS
TLB 和 Cache都是一种cache技术 为什么suprerpage可以增加hit rate
Consistency(一致性)
Cache Lookup(关联) 如何设计这个缓存
TLB
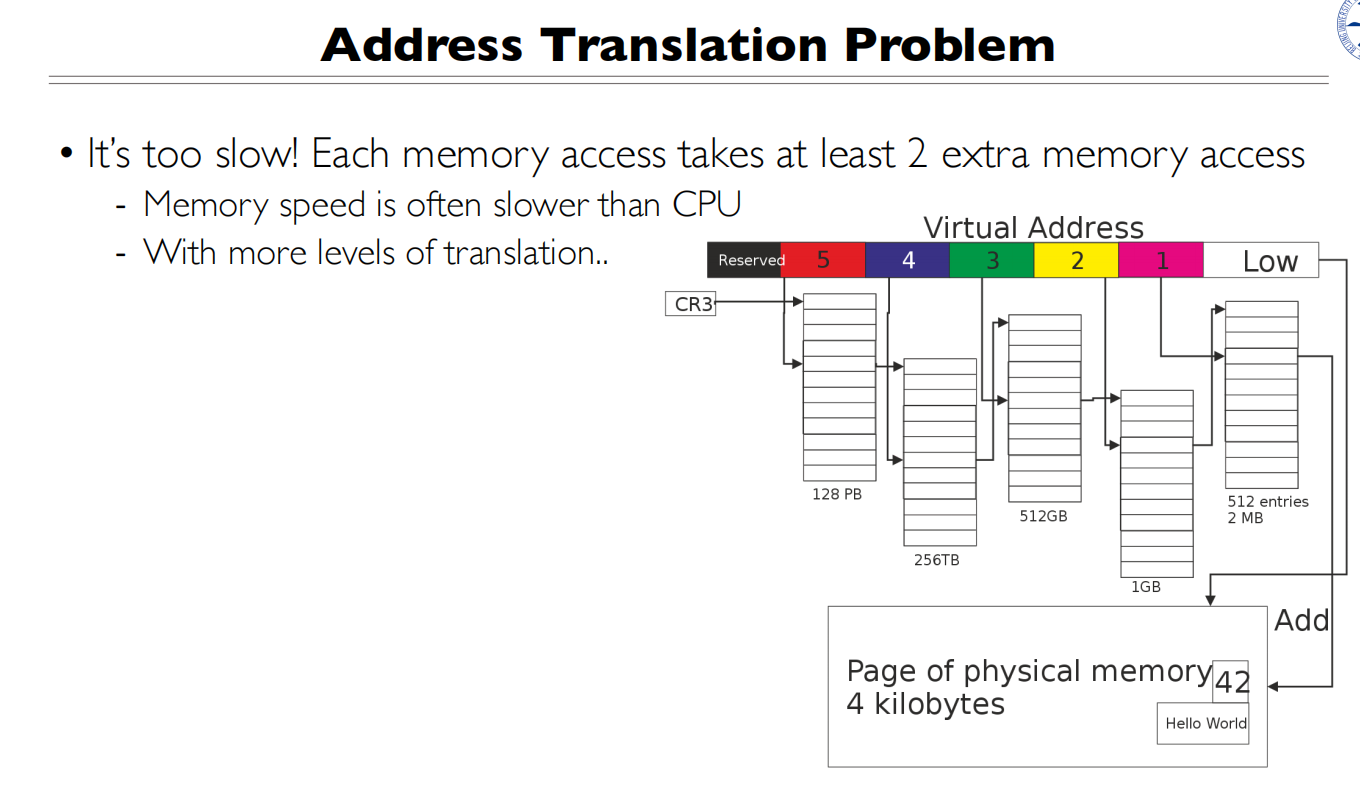 页表的最大问题就是慢
页表的最大问题就是慢
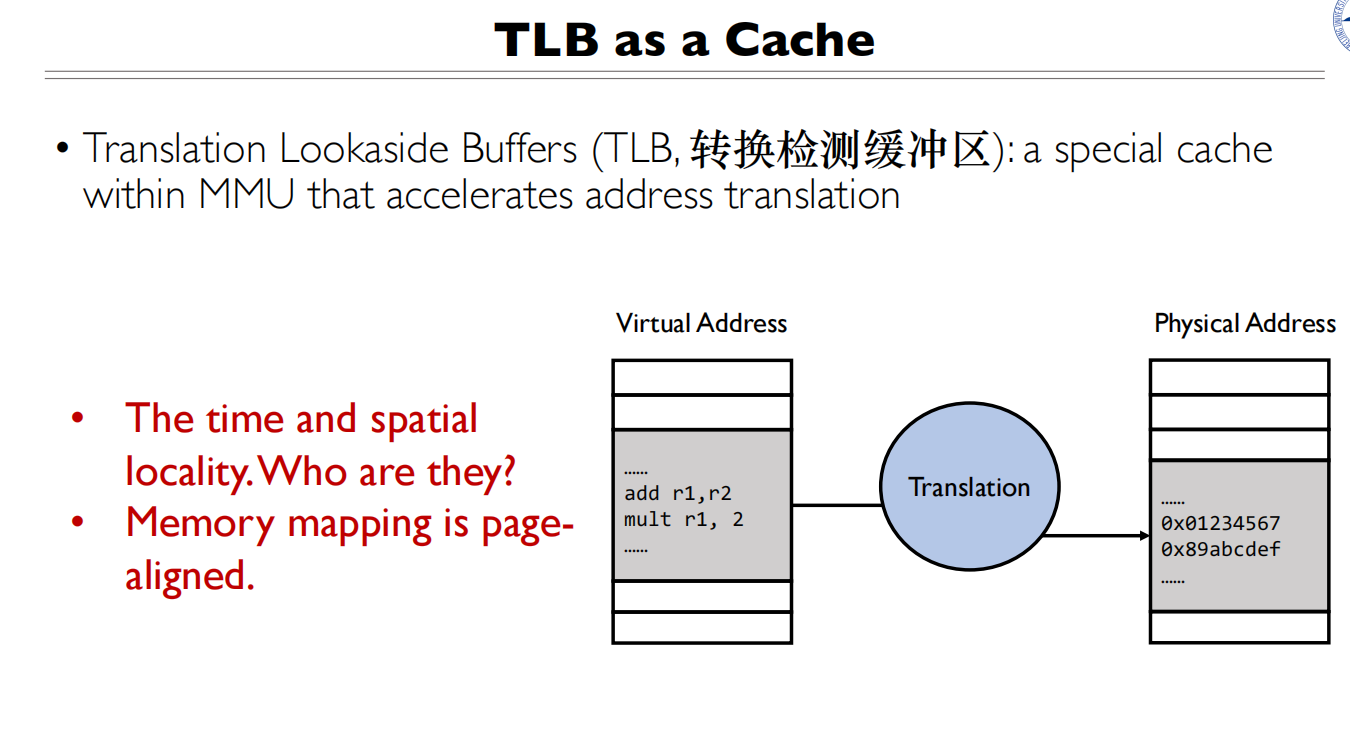 TLB缓存的是虚拟地址到物理地址的映射
TLB缓存的是虚拟地址到物理地址的映射
TLB Lookup
 所有的cache都可以理解为一个表
所有的cache都可以理解为一个表
先拿着虚拟地址去TLB找,可以直接找到物理页框号,就不用查页目录和页表了
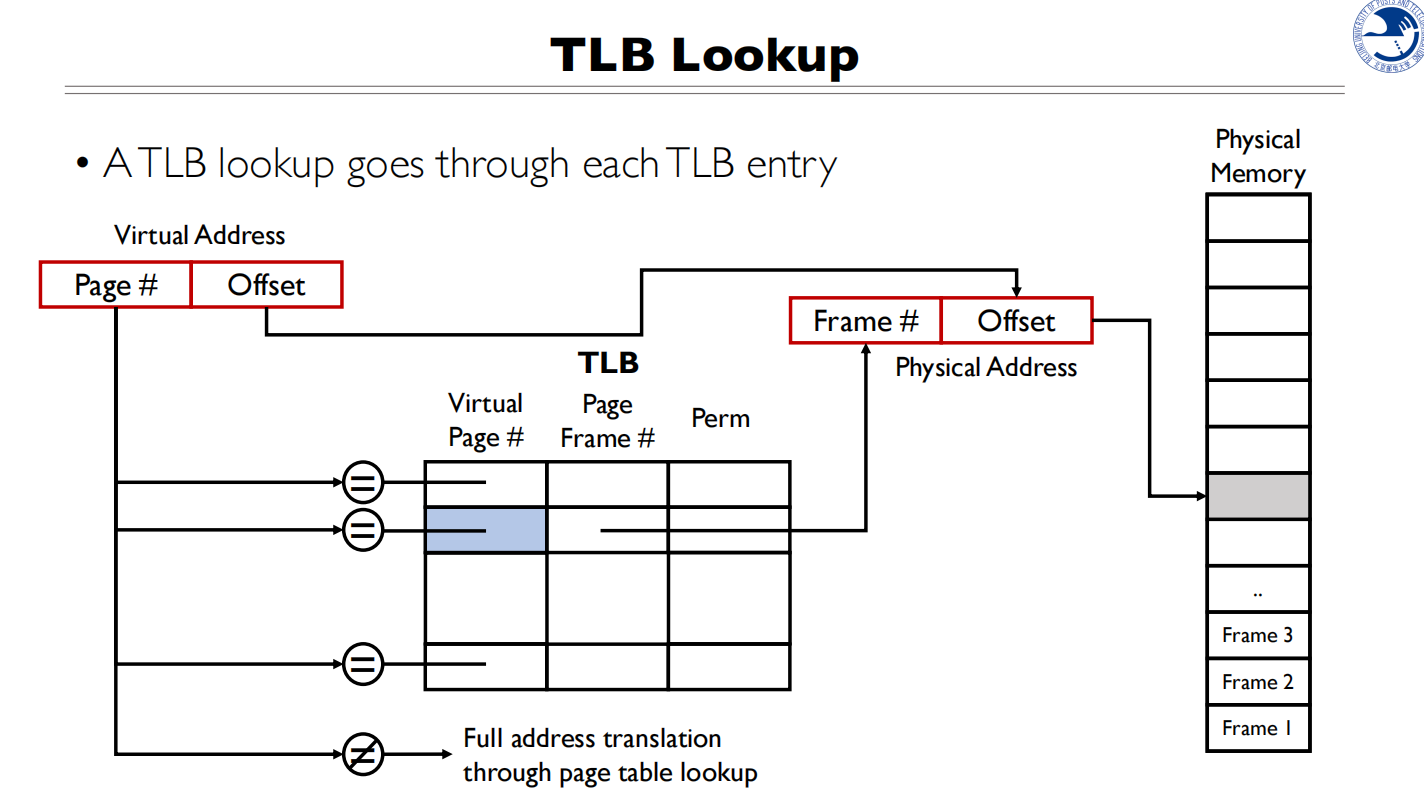
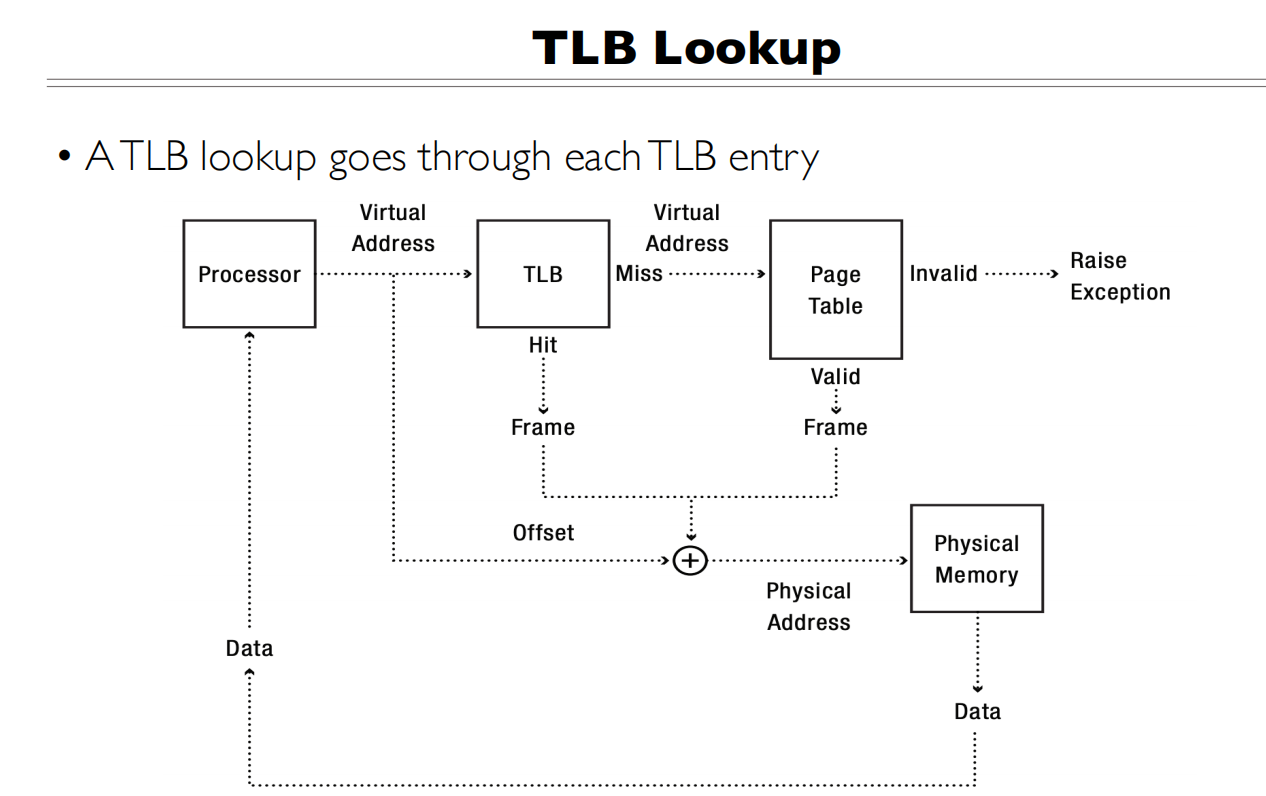

TLB Miss
- 为什么会TLB Miss
- Page not accessd before
- Page evicted due to limited TLB size(LRU调度)
- Page mapping conflict due to association
- Other processes update the page table

TLB Performance
 最重要的是提升TLB hit rate
最重要的是提升TLB hit rate
If a TLB hit take 1 clock cycle, a miss takes 30 clock cycles, a memory read takes 30 clock cycles, and the miss rate is 1%, what’s the average memory access time?
 超页能提高TLB的命中率,为什么?
超页能提高TLB的命中率,为什么?
- TLB的工作原理:
- TLB是一个缓存,存储最近使用的虚拟地址到物理地址的映射
- 每个TLB表项对应一个页面的映射
- TLB容量是有限的,通常只能存储几十到几百个映射
- 比较普通页面(4KB)和超页(2MB)的情况:
- 假设程序需要访问8MB连续内存
- 使用4KB页面:需要2048个TLB表项
- 使用2MB超页:只需要4个TLB表项
- 相同内存区域,超页需要的TLB表项数量大大减少
- TLB命中率提升的原因:
- TLB的容量是固定的
- 超页减少了需要缓存的页表项数量
- 同样大小的TLB可以覆盖更大的内存空间
- 因此更可能在TLB中找到需要的地址映射
- 实际例子: 比如一个程序按顺序访问1GB内存:
- 4KB页面:需要262,144个TLB表项
- 2MB超页:只需要512个TLB表项
- 1GB超页:只需要1个TLB表项
100个虚拟页和100个物理页,使他们在各自页的偏移相同,变成一个大的映射
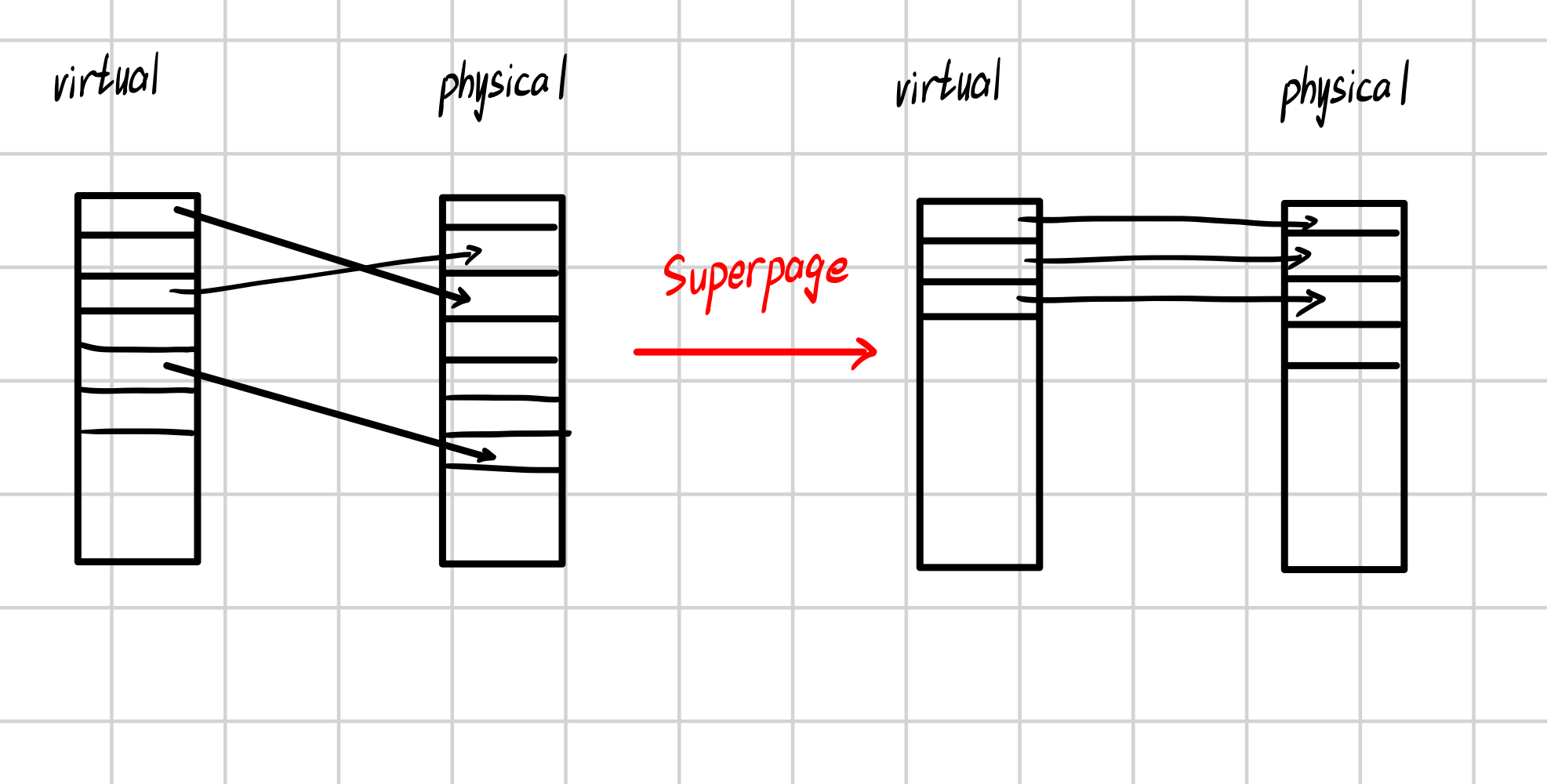 For a 2MB superpage, ,所以页内偏移Offset是21 bits,只需要比较
For a 2MB superpage, ,所以页内偏移Offset是21 bits,只需要比较
 TLB预取也能提高性能
TLB预取也能提高性能
TLB Consistency(比较难)
缓存需要和被缓存的对象一致
Consistency(一致性) is a common issue for each cache: the cache must be always the same as the original data whenever the entries are modified.
TLB的值什么时候会改变:
- Process context switch 上下文切换
- Permission reduction 权限降低(防止越权访问)
- TLB shootdown
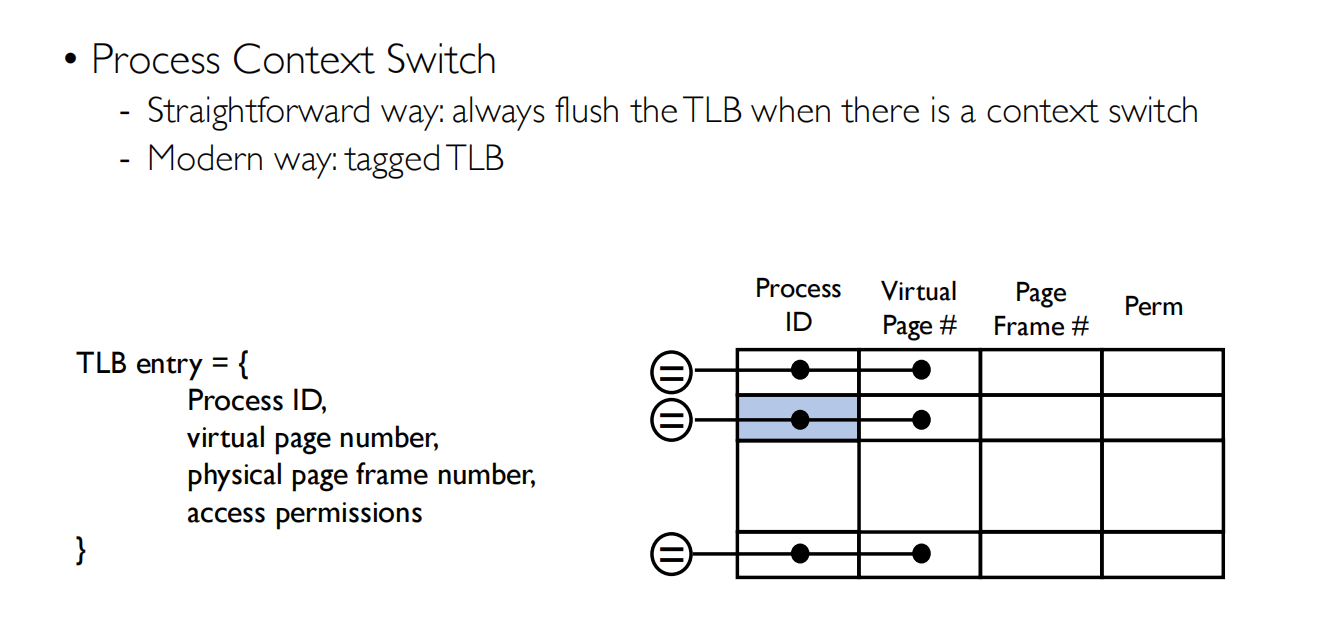 tagged TLB加入了进程ID,不需要丢弃,会去匹配进程ID,匹配上即可
tagged TLB加入了进程ID,不需要丢弃,会去匹配进程ID,匹配上即可
 权限降低不改变TLB会导致越权访问,权限的差别主要就是在访问范围
权限降低不改变TLB会导致越权访问,权限的差别主要就是在访问范围
当权限提高的时候不需要立刻修改TLB,因为当TLB存在问题就会去查页表,然后再更新TLB “lazy design”

 同一个进程中,处理器之间不共享TLB,但是共享页表
同一个进程中,处理器之间不共享TLB,但是共享页表
所以当一个处理器将自己的TLB改了之后,其他的处理器也要更改TLB
 TLB shutdown如何处理
TLB shutdown如何处理
Memory Cache
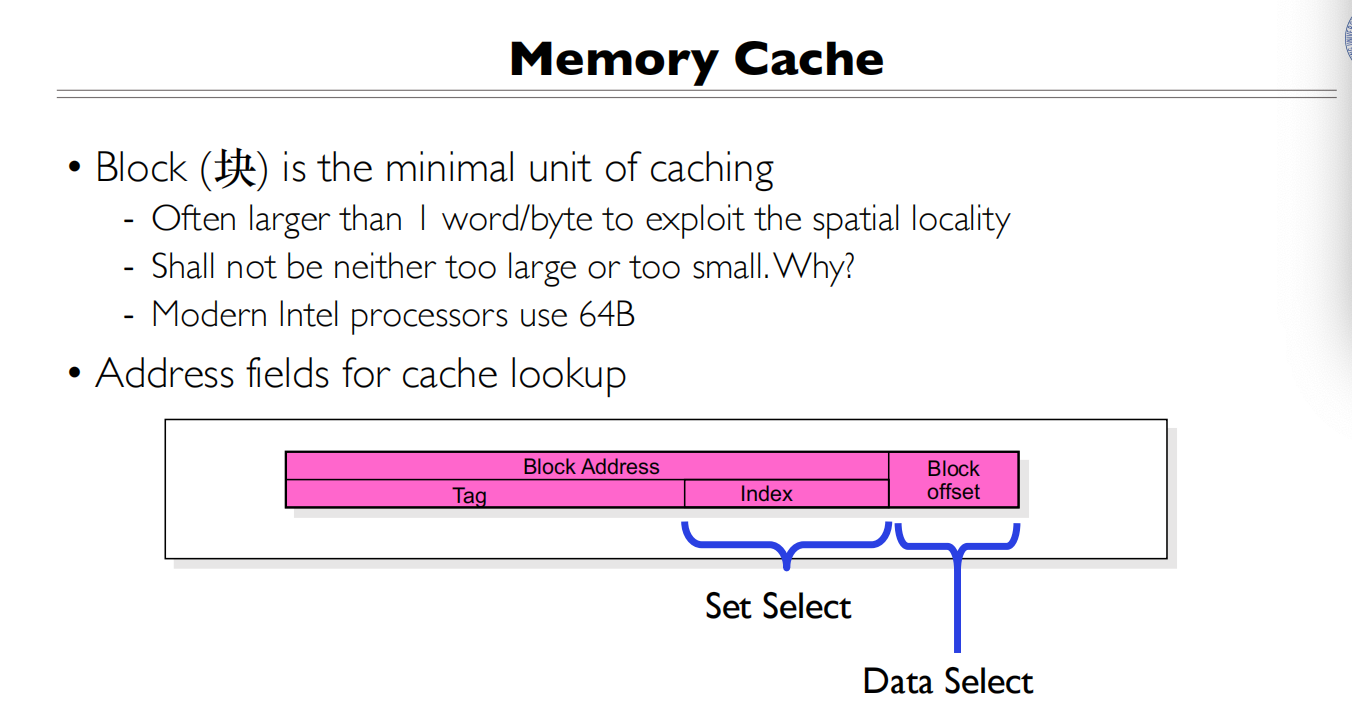 块是缓存的最小单元
块是缓存的最小单元
以块为单位做Cache查找,块不能太大,也不能太小
Cache里面存的是数据,物理地址到值的映射

全关联
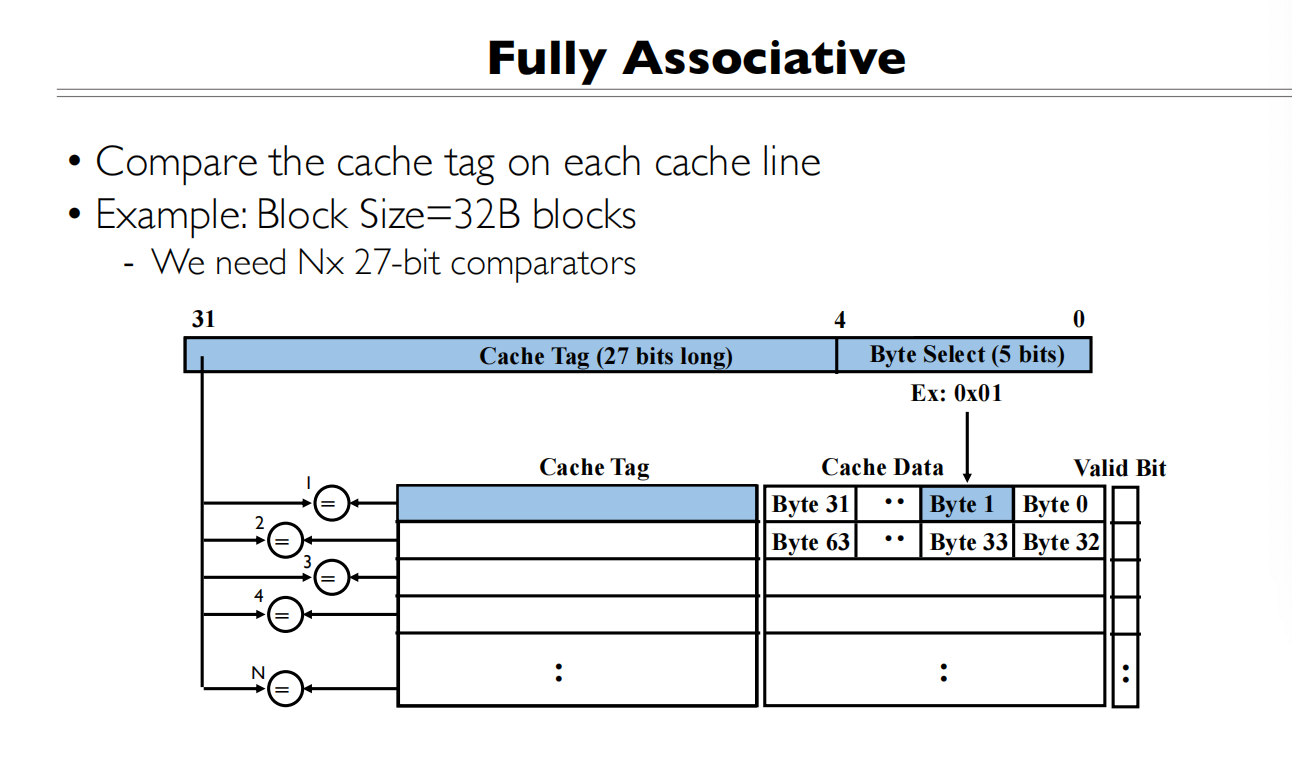 全关联是任意一个地址能存在任意一个位置
全关联是任意一个地址能存在任意一个位置
好处:缓存命中率最高 缺点:查找开销大
一个Cache block 是32bytes,将地址分为两部分Cache Tag(27 bits)+Byte Select(5 bits)
为什么Byte Select是5bit?
查找的时候一个一个比较Cache Tag,有就是缓存命中了,然后再基于块内偏移找到对应的字节
Cache Tag在全关联Cache中用于标识该Cache行存储的是哪个主存块的数据。
- Cache Tag的作用:
- 用于比较当前访问的内存地址是否在Cache中
- 存储了该Cache行对应的主存块的地址标识
- 每个Cache行都有一个Tag用于比较匹配
- 工作过程:
- CPU发出内存地址(图中显示32位地址被分为27位Tag + 5位Byte Select)
- Tag部分与所有Cache行的Tag同时比较(图中的N个比较器)
- 如果有匹配的Tag且Valid位为1,就是Cache命中
- Byte Select用于选择Cache行中的具体字节
- 为什么需要Tag:
- Cache容量小于主存
- 需要知道Cache中的数据对应主存中的哪个位置
- Tag就是用来建立这种映射关系的
所以Tag实际上就是Cache与主存之间的地址对应关系的标识,在全关联映射中,需要将输入地址的Tag与所有Cache行的Tag进行比较来确定是否命中。
直接映射
直接映射:任意一个地址只能存在其中某一个行
优缺点和全关联正好相反
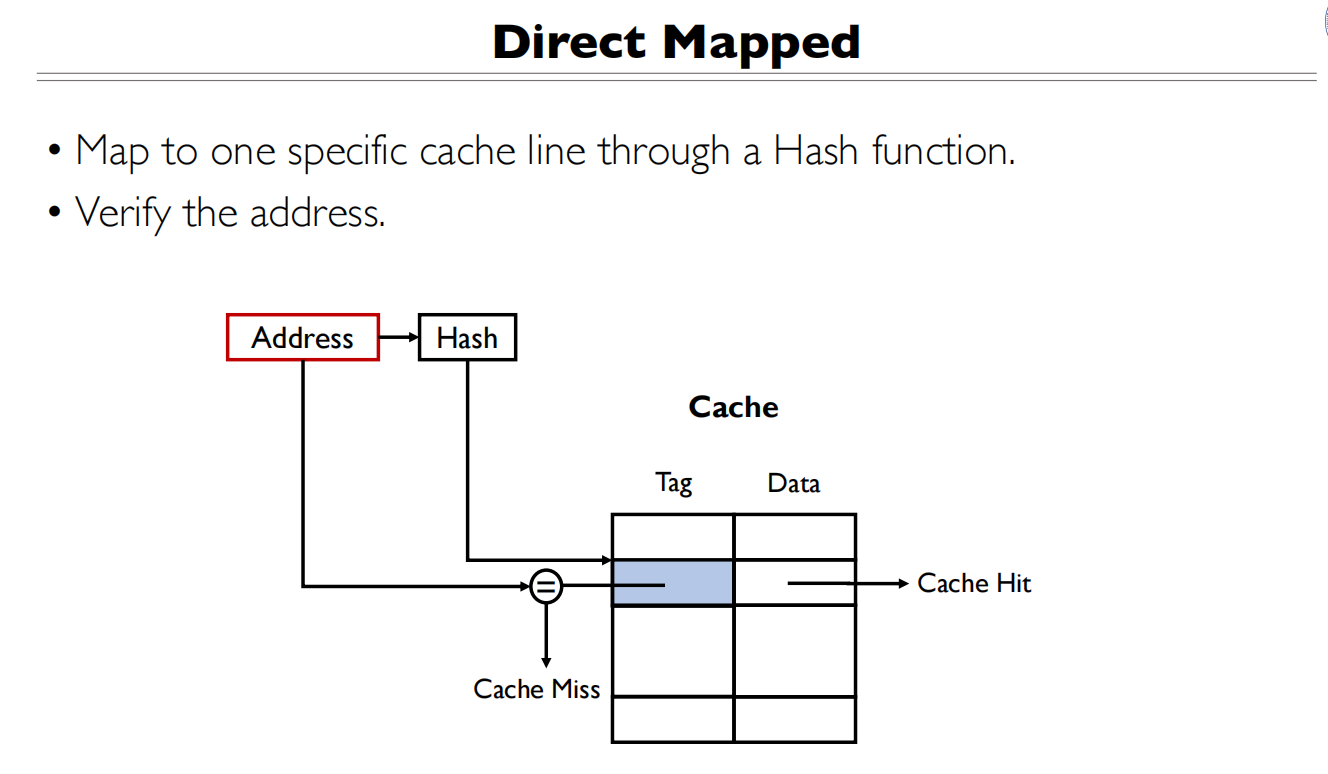
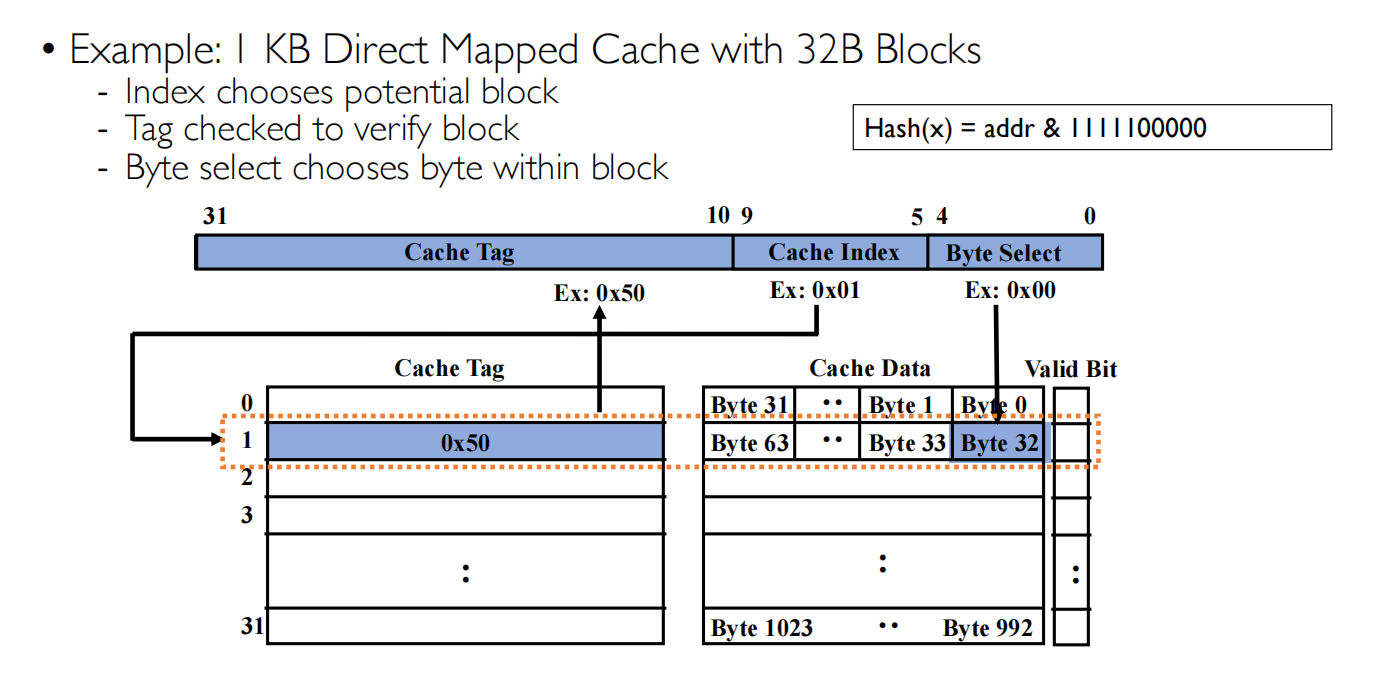
 Cache Index是通过Hash(x)取得的
Cache Index是通过Hash(x)取得的
Cache Index 取决于Cache Line 的数量,所以需要5 bit 来确定存在哪一个Cache Block
仍然需要Cache Tag 来唯一标识
- 比如在这个例子中,Cache Index只有5位
- 这意味着所有内存地址中第5-9位相同的地址都会映射到同一个缓存行
- 但它们可能来自完全不同的内存区域
- 所以需要Cache Tag来比较,但只需要一个比较器即可,相比全关联的N个比较器好许多
举个🌰:
- 地址A:0x10050 和 地址B:0x20050
- 它们的Cache Index相同(都是0x01)
- 但它们的Tag不同(0x100 vs 0x200)
- 通过Tag的比较,可以知道缓存中的数据是属于哪个内存地址的
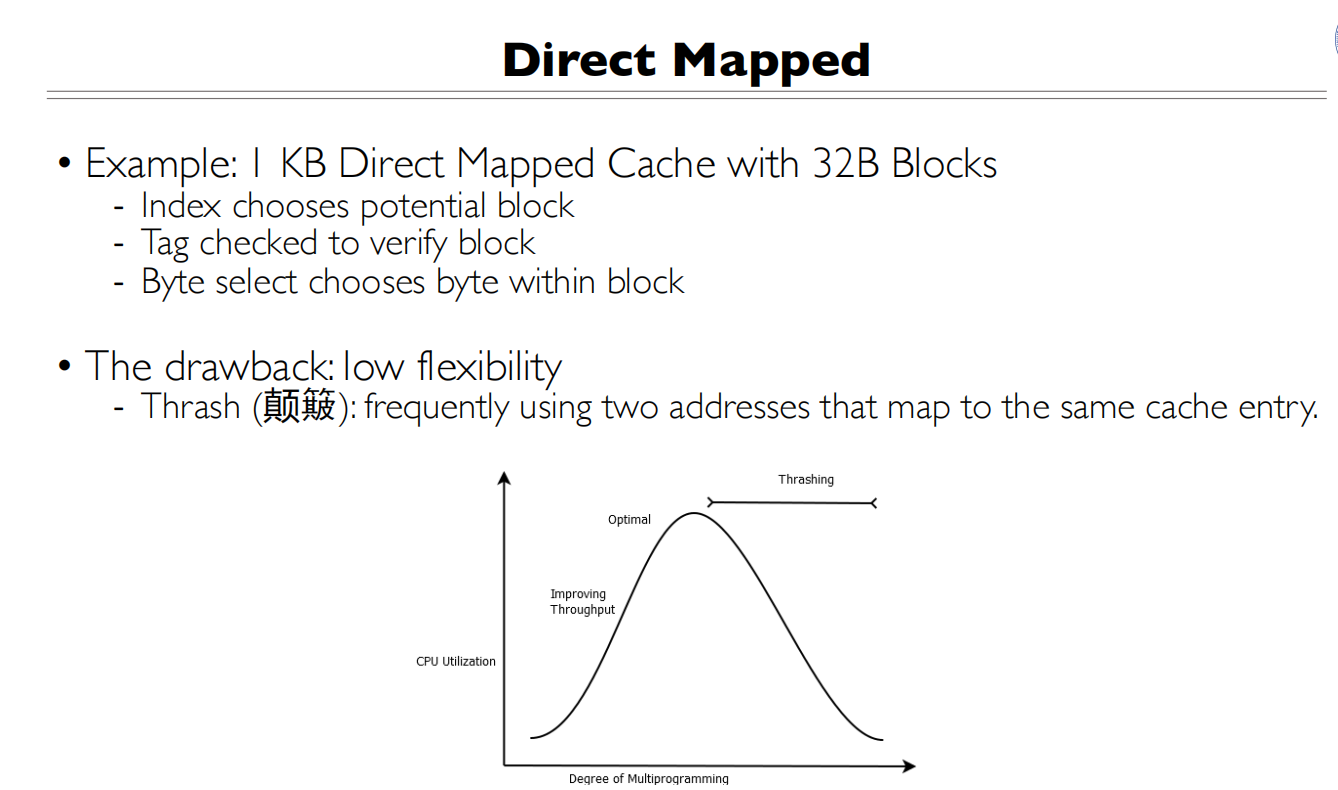
- 什么是缓存颠簸:
- 当程序频繁访问两个不同的内存地址,而这两个地址被映射到同一个缓存行时
- 会导致缓存反复失效和重新加载
- 每次访问都会引起缓存缺失(Cache Miss)
- 发生原因:
- 直接映射缓存中,每个内存地址只能映射到一个固定的缓存行
- 如果程序交替访问映射到同一缓存行的不同地址
- 每次访问都会使对方的数据失效,需要重新从内存加载
N路组关联
N路组关联:每个地址可以存在其中的n行
介于全关联和直接映射之间,可以将地址映射到n个位置
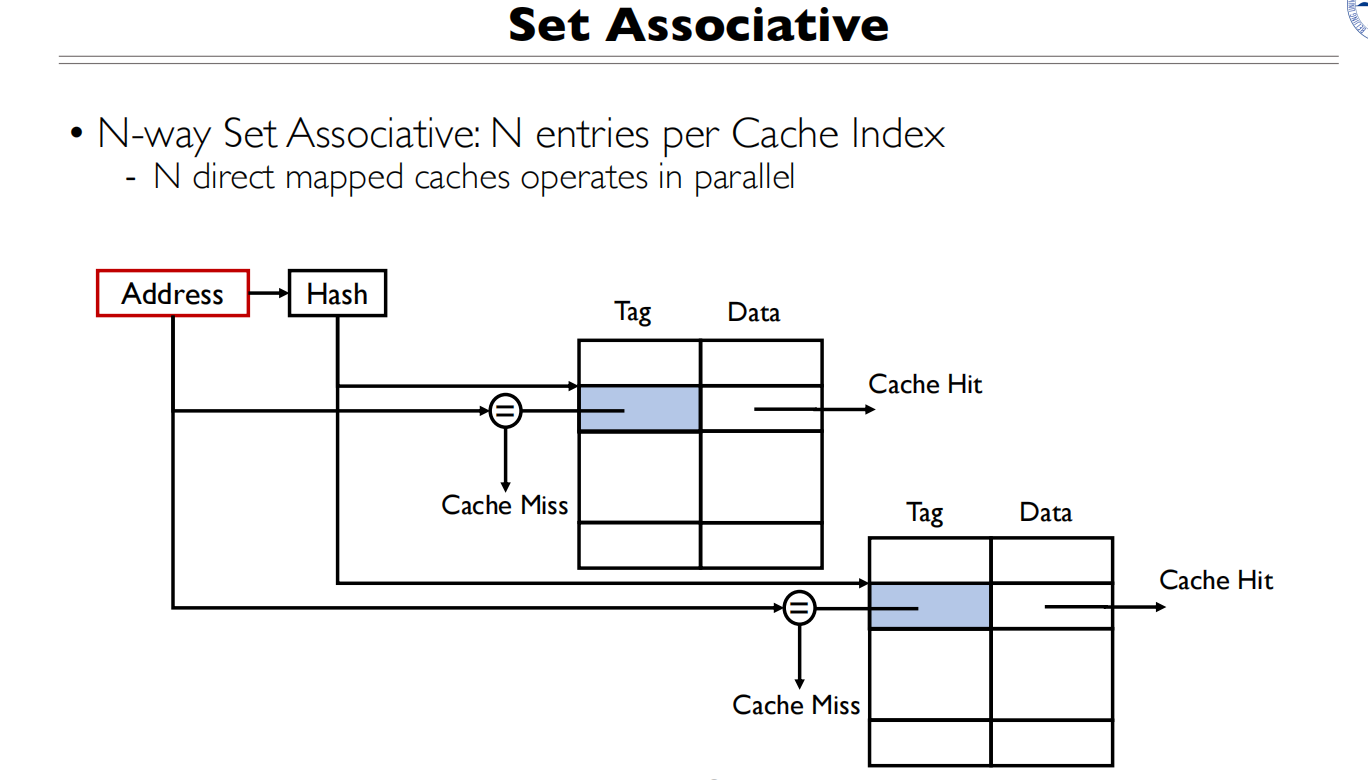
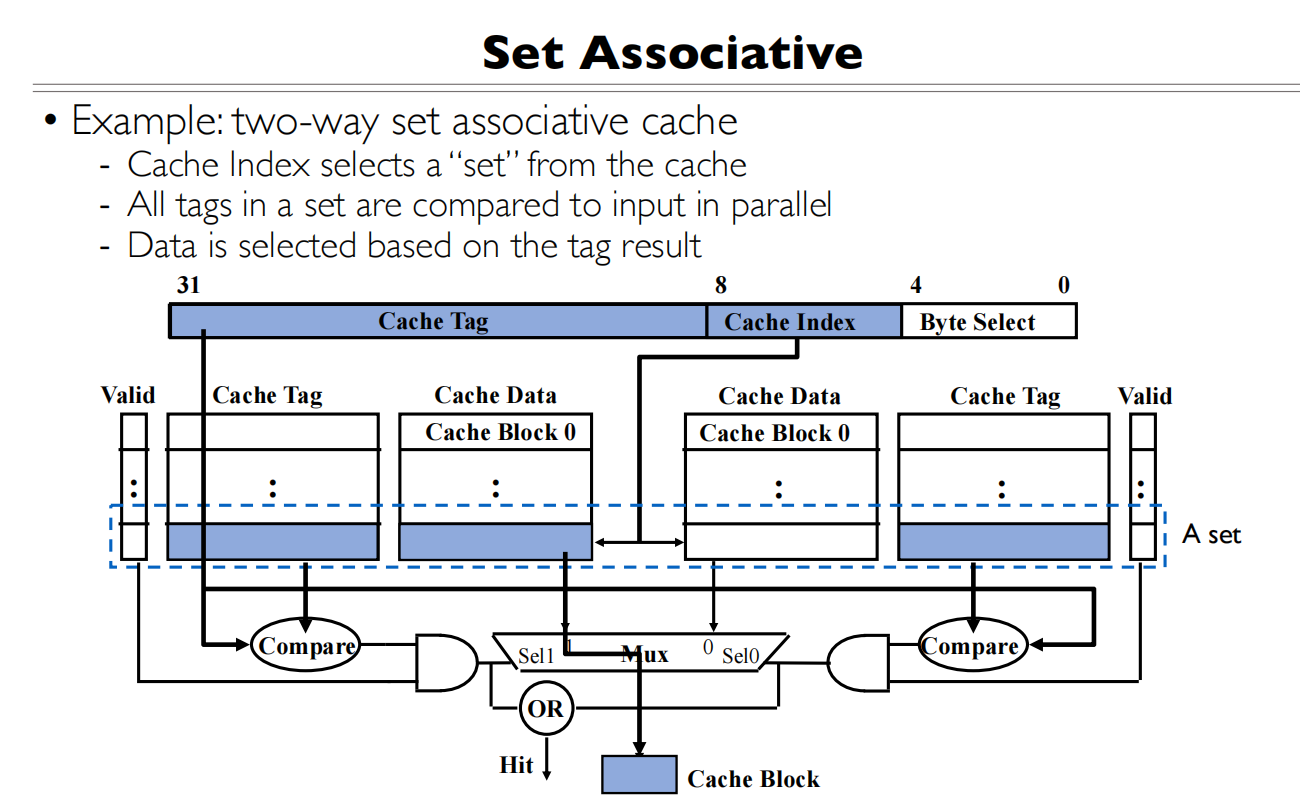
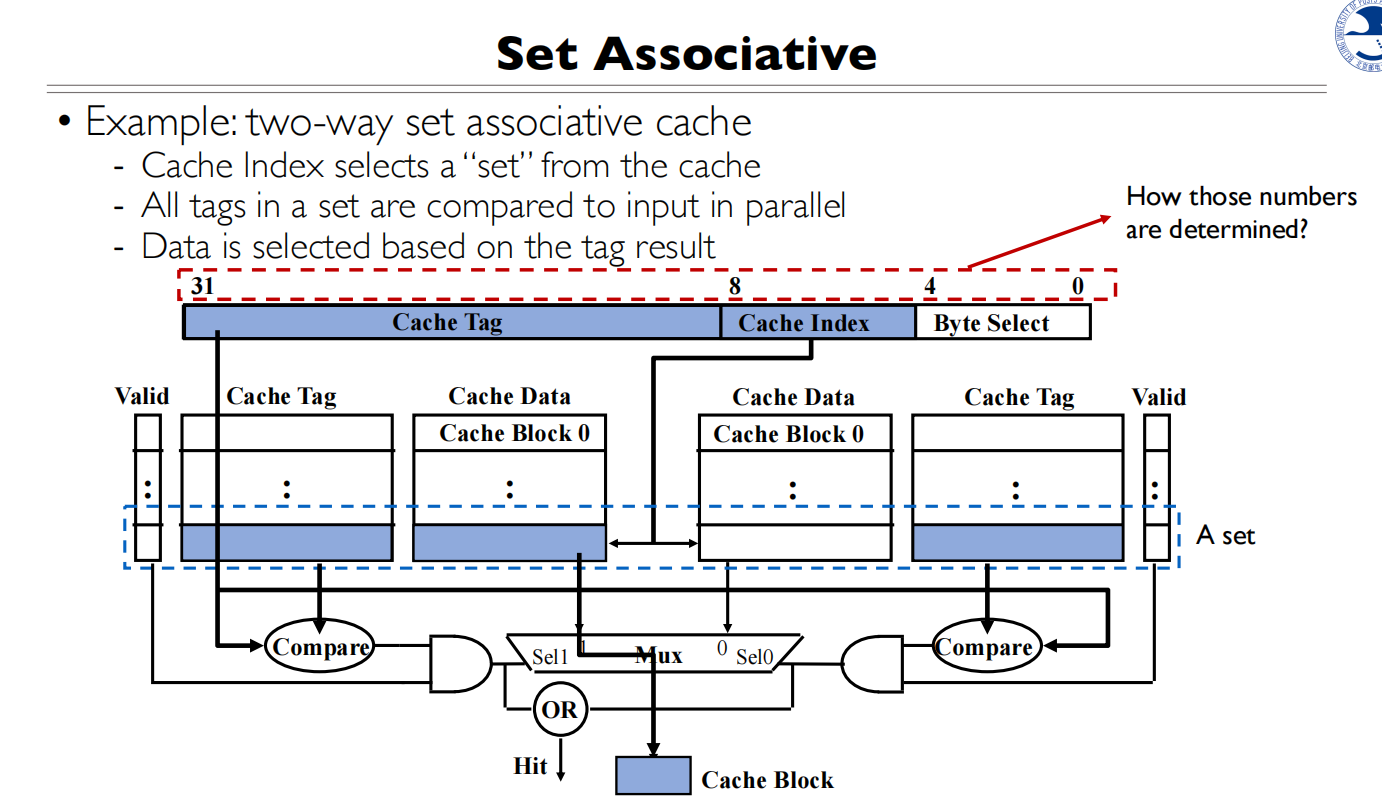 Byte Select块内偏移还是由Block大小确定,看Block内有多少个byte
Byte Select块内偏移还是由Block大小确定,看Block内有多少个byte
Cache Index是由每一路有多少Cache Line的数量确定,每个Cache Index可以指到两个Cache Line(2路组相联)
Cache Tag是剩下的bit
 N=1的时候变成直接映射,N=32(Cache Line的数量)的时候变成全关联
N=1的时候变成直接映射,N=32(Cache Line的数量)的时候变成全关联
如果将Cache Tag和Cache Index的位置调换
- 相邻的内存地址会映射到相同的缓存行(因为高位相同)
- 只能缓存间隔很远的数据块
- 违背了局部性原理
- 会导致大量的缓存冲突
现有设计(低位index,高位tag)的好处:
- 相邻的内存地址会映射到不同的缓存行(因为低位不同)
- 可以同时缓存相邻的数据块
- 充分利用了空间局部性
不要将连着的内存地址存在相同的缓存行
TLB也是N路组相联的
例题
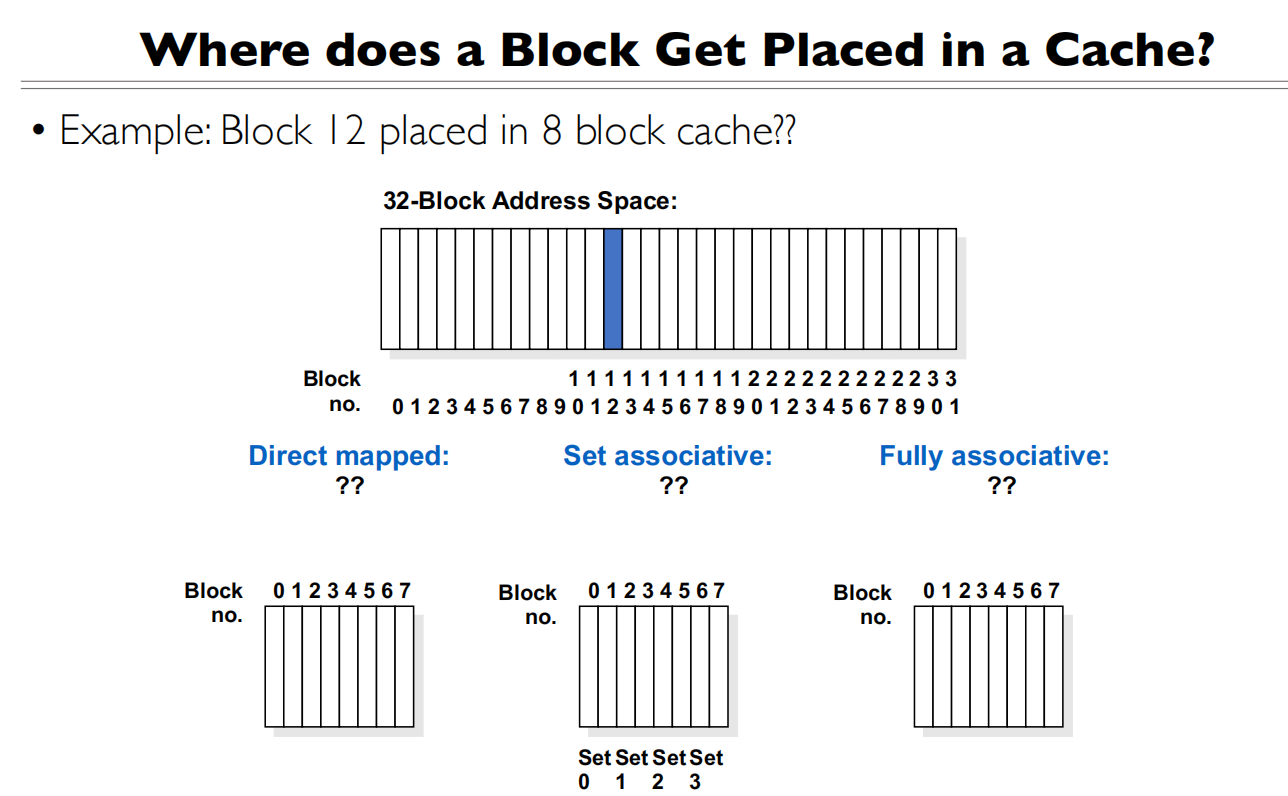 直接映射是到了13%8=4
直接映射是到了13%8=4
2路组相连,8个Block分为了4个Set,13%4=1,所以会到Set0的两个Block(Block0/Block1)中的1个
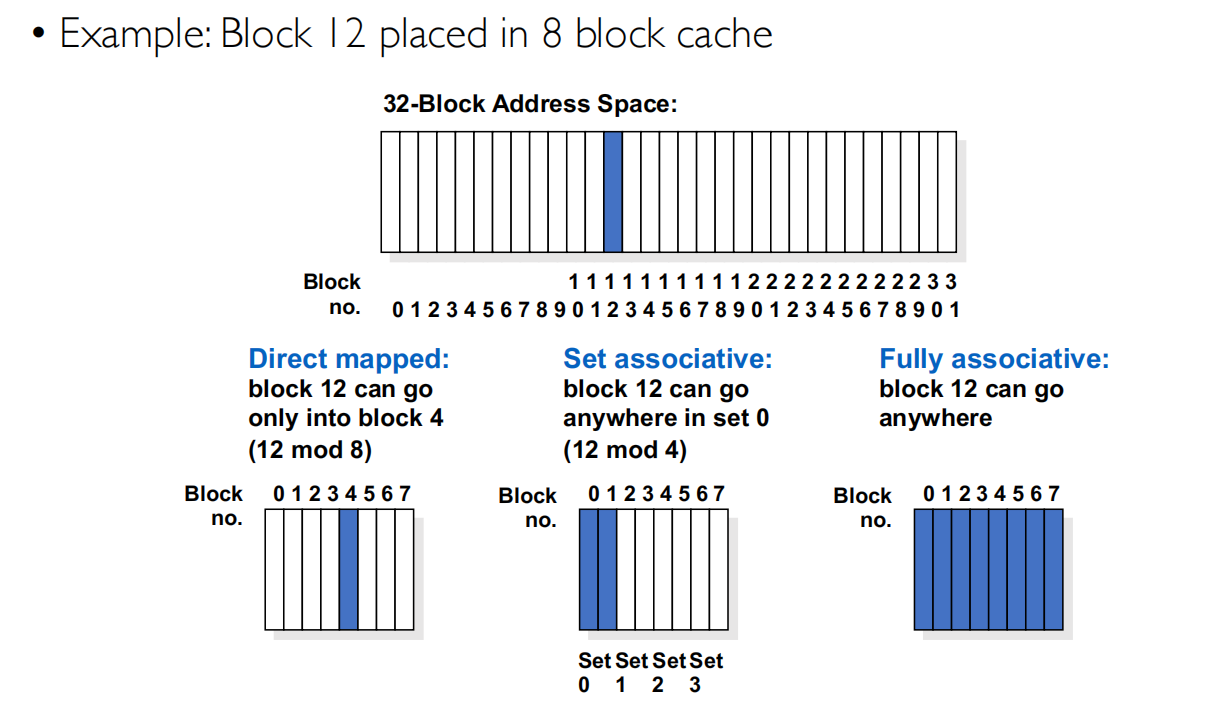
Cache Replacement

Cache的写入策略
 dirty bit来标记这个block是否改动过
dirty bit来标记这个block是否改动过
Overlapping TLB and Cache
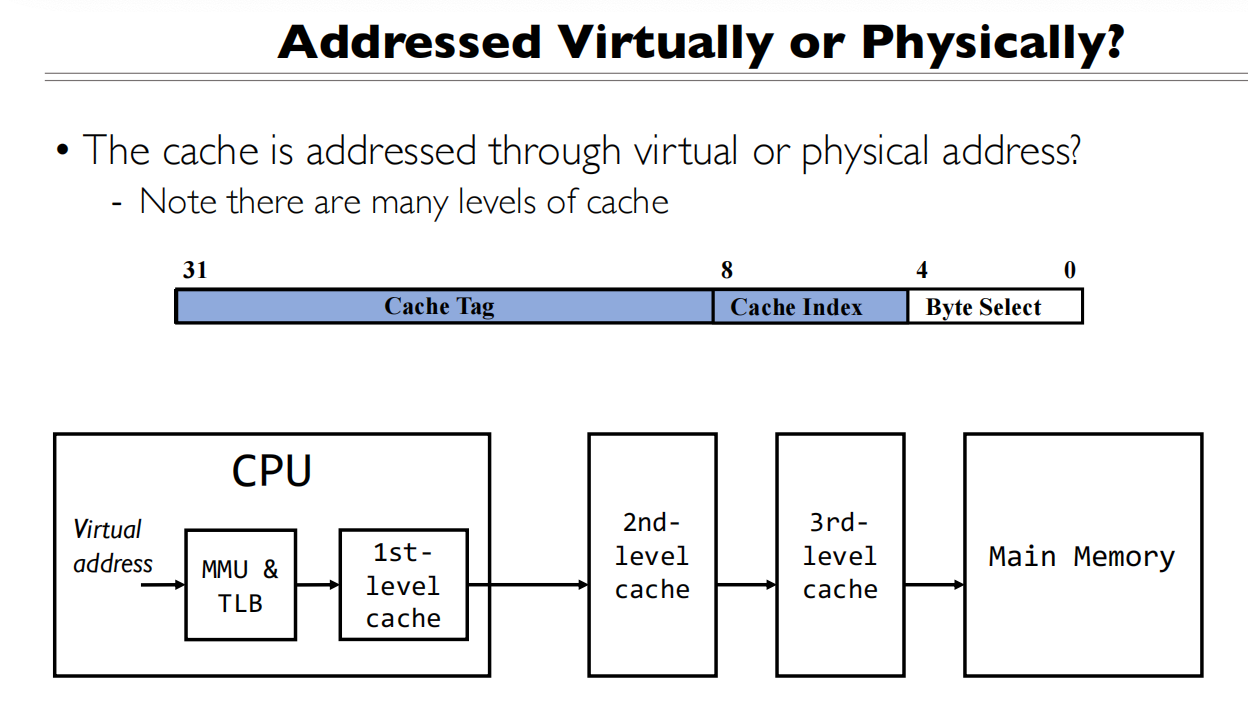
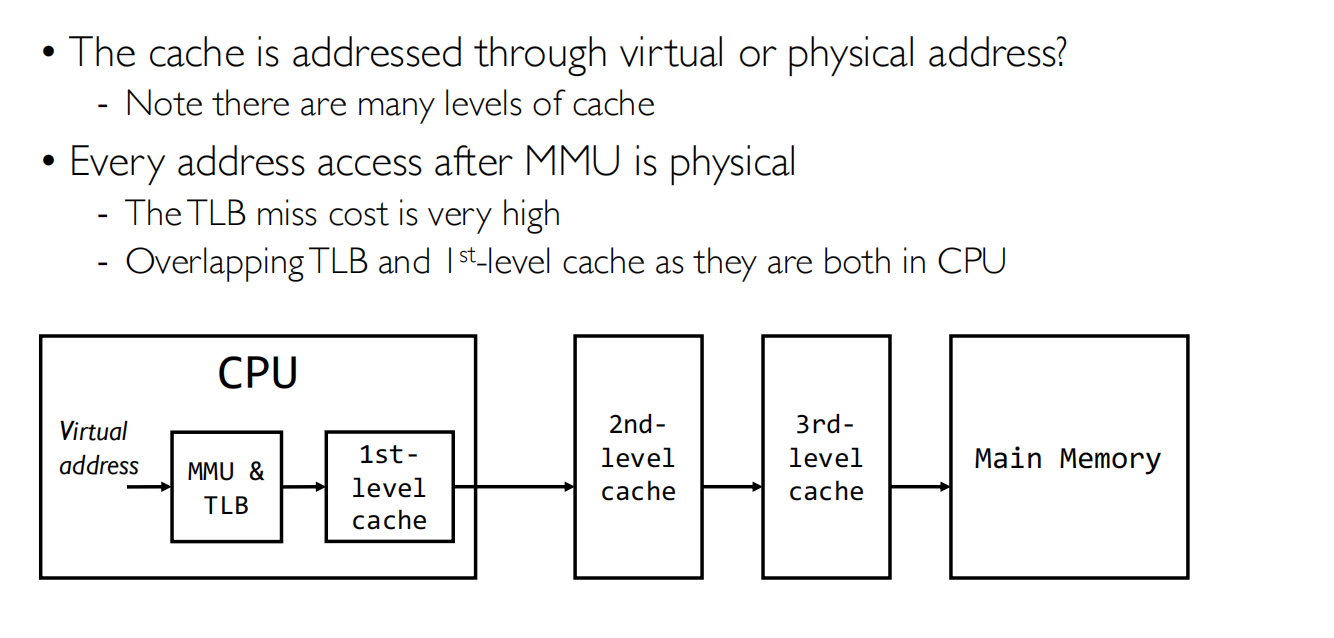
 Offset覆盖到index+byte 可以将页的翻译和Cache的查找并行起来
Offset覆盖到index+byte 可以将页的翻译和Cache的查找并行起来
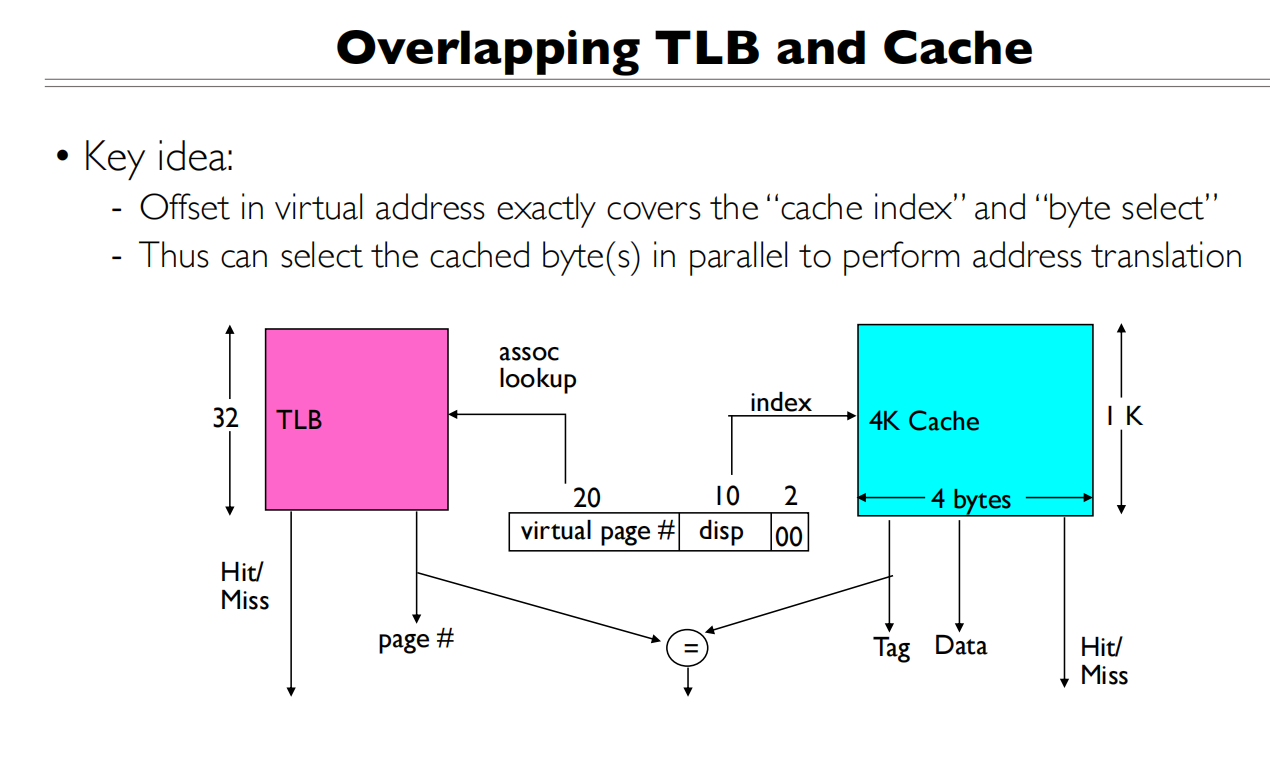 TLB和Cache并行查找的过程:
TLB和Cache并行查找的过程:
- 虚拟地址的划分
- 20位虚拟页号:用于TLB查找
- 10位displacement(disp):用于cache索引
- 2位byte select:用于选择具体字节
- 这种划分方式是关键,因为它允许并行操作
- 并行查找过程: 当CPU发出一个虚拟地址访问请求时,会同时进行两个操作:
TLB查找:
- 使用20位虚拟页号查找TLB
- TLB会返回对应的物理页号
- 同时给出TLB hit/miss信号
Cache查找:
- 使用10位disp作为索引直接访问cache
- Cache会返回对应的数据和tag
- 同时给出Cache hit/miss信号
- 验证过程:
- 当TLB返回物理页号后
- 将其与cache中的tag进行比较(图中的”=“符号)
- 如果相匹配且都是hit,说明找到了正确的数据
这种设计的优势是:
- 不需要等待地址翻译完成才开始查找cache
- TLB查找和cache查找可以并行进行
- 显著减少了访存延迟
这就是为什么图中的offset(disp+byte select)要正好覆盖cache index和byte select的原因 - 这保证了我们可以在不知道物理地址的情况下就开始cache查找。
 VIVT,不同的虚拟地址可能映射到相同的物理地址
VIVT,不同的虚拟地址可能映射到相同的物理地址
Offset要和Index+byte对应是实现TLB和Cache并行访问的关键。
- 性能需求:
- CPU访问内存时,我们希望尽可能快地找到数据
- 如果必须等TLB翻译完成才能开始查找Cache,会增加延迟
- 理想情况是TLB查询和Cache查询能够并行进行
- 并行访问的条件:
- Cache需要知道数据在哪个Cache行(需要index)
- Cache需要知道具体是哪个字节(需要byte offset)
- 如果这些信息需要等待地址翻译才能获得,就无法并行
- 关键设计:
- 虚拟地址中的Offset部分在地址翻译前后保持不变
- 这意味着虚拟地址的Offset和物理地址的(index + byte)完全相同
- 因此可以直接用虚拟地址的Offset部分来访问Cache,无需等待地址翻译
- 实际好处:
- Cache可以在TLB还在查询的同时,就开始定位可能的数据
- 等TLB返回物理地址后,只需要验证tag是否匹配
- 大大减少了访存延迟
这就像是在图书馆找书:
- 虚拟页号相当于书的分类号(需要查目录转换)
- Offset相当于书架上的位置(无需转换,直接用)
- 你可以在查找分类号的同时,就走到对应的书架位置,提高效率
Summary
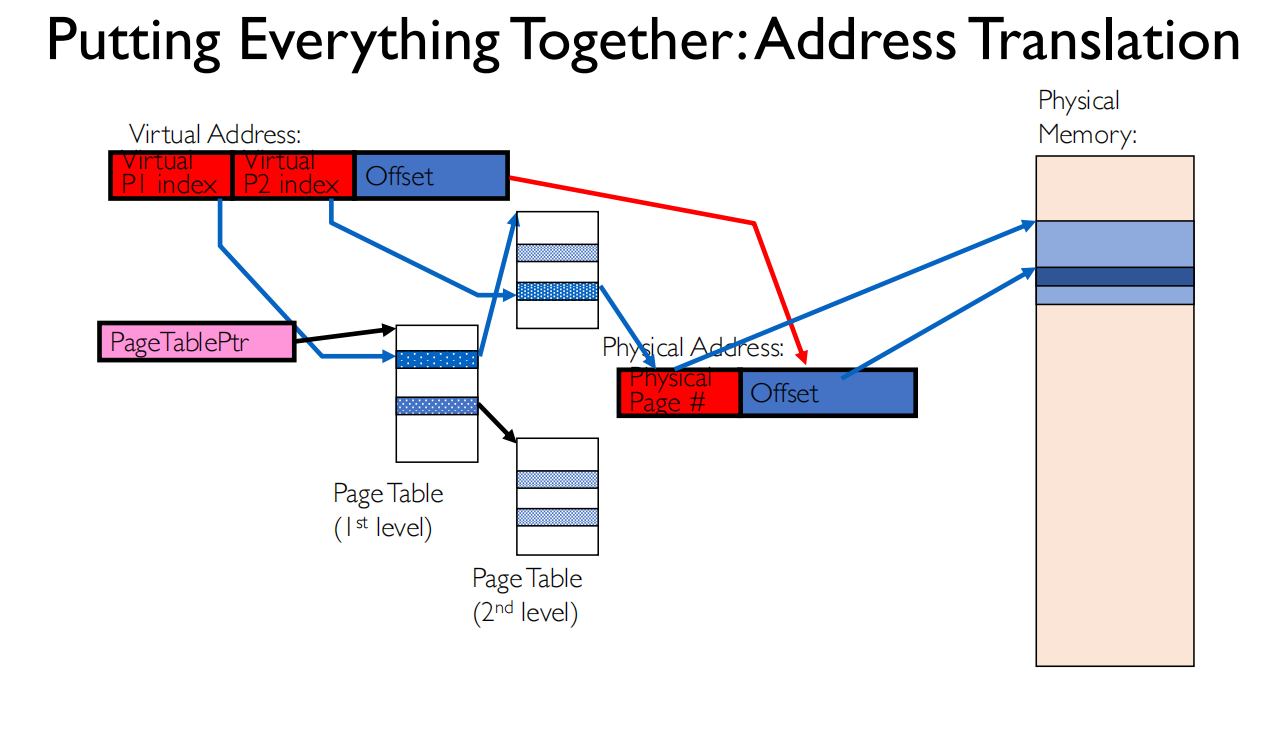
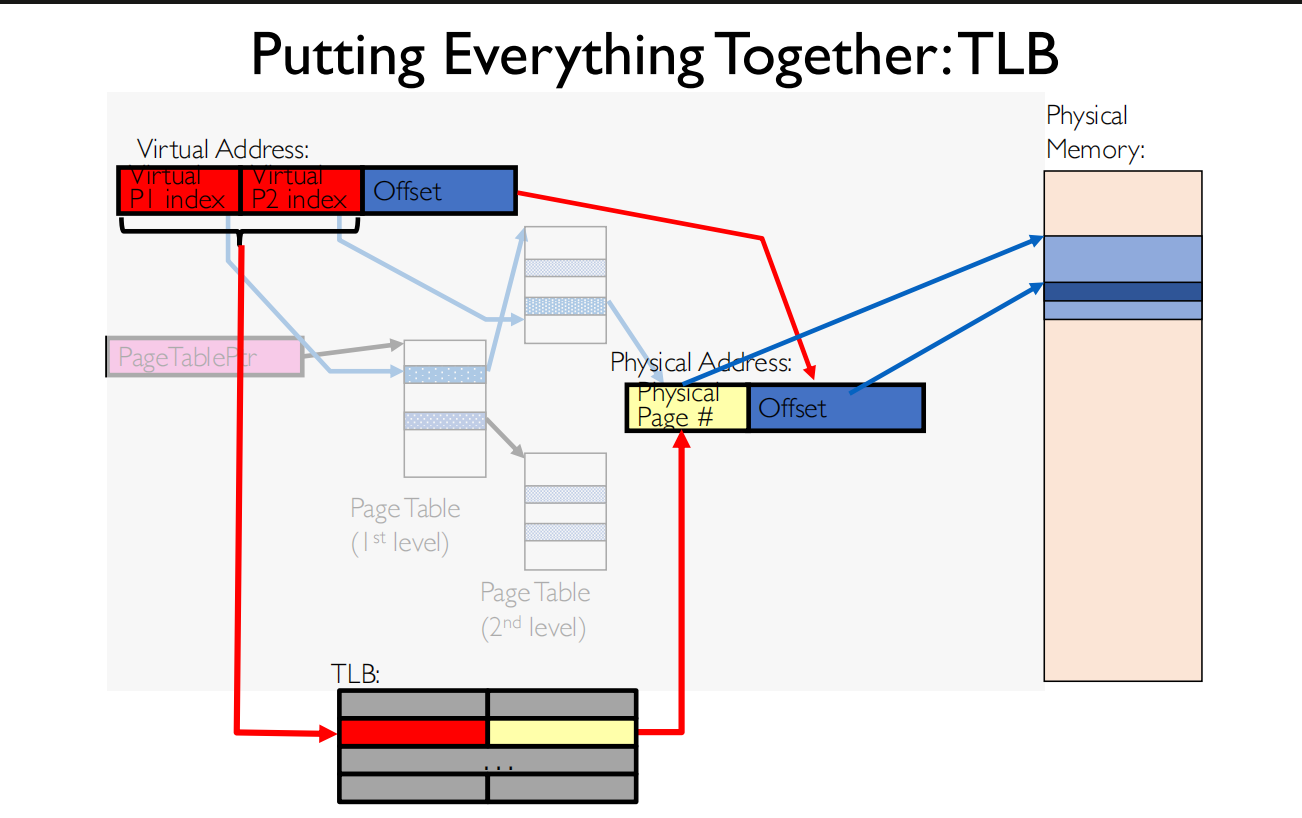
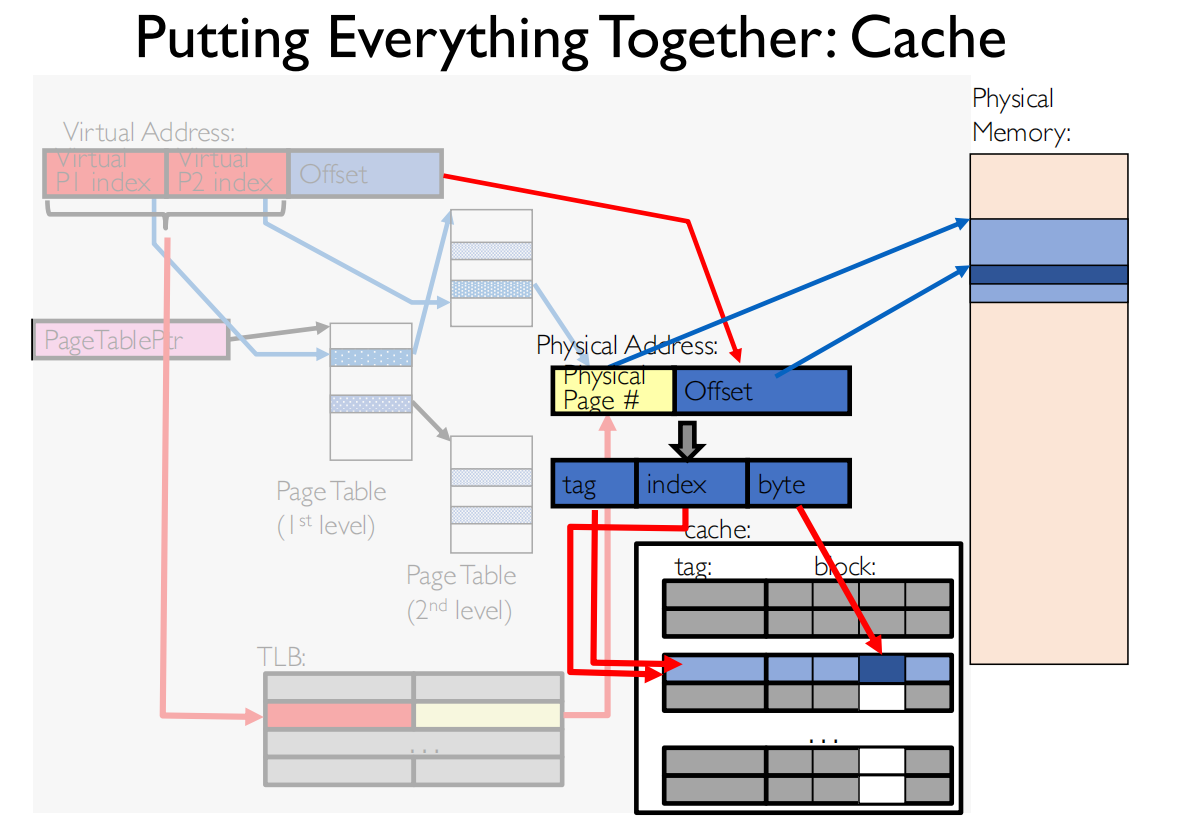 最优情况,假设TLB hit , cache hit,访问0次内存
最优情况,假设TLB hit , cache hit,访问0次内存
- TLB是MMU的一部分,在CPU内,L1 cache在CPU中
如果TLB命中了,缓存没命中,需要访问1次内存
如果TLB和缓存都没命中,需要访问3次内存
Page Coloring
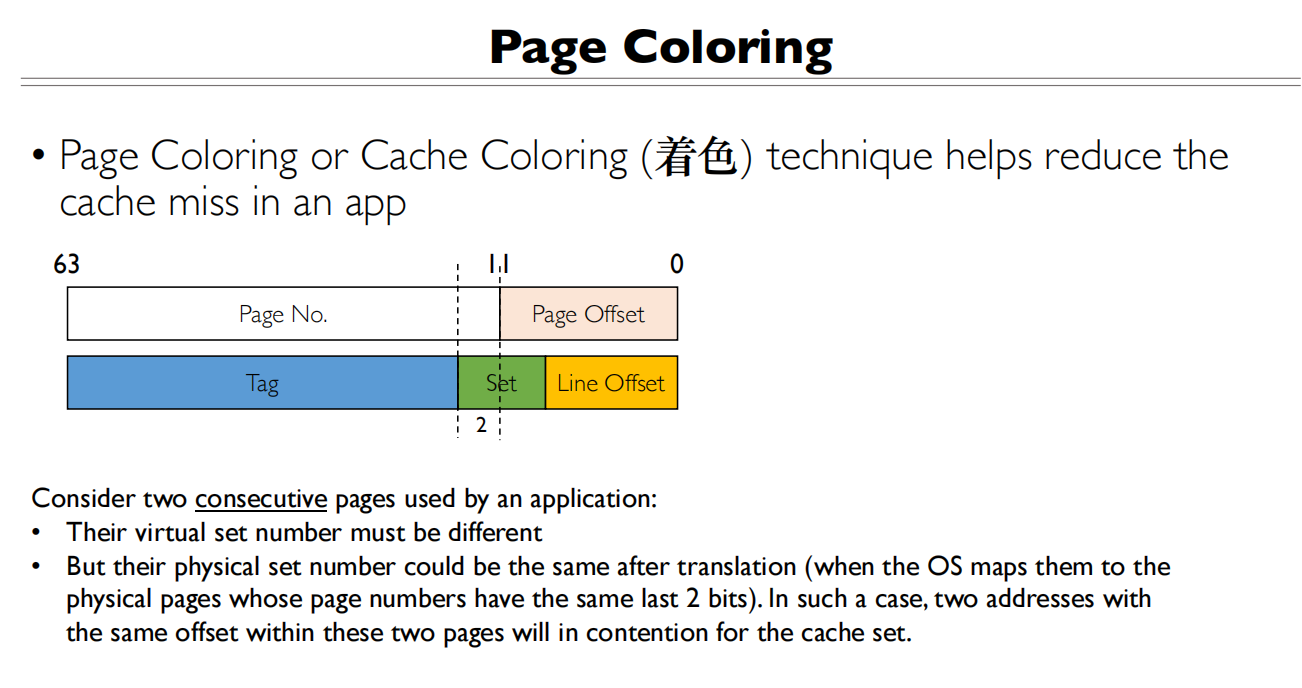 两个连续的页会映射到不同的Index,这是好事,在cache中没有竞争
两个连续的页会映射到不同的Index,这是好事,在cache中没有竞争
但是虚拟地址翻译完后,物理地址可能会相同
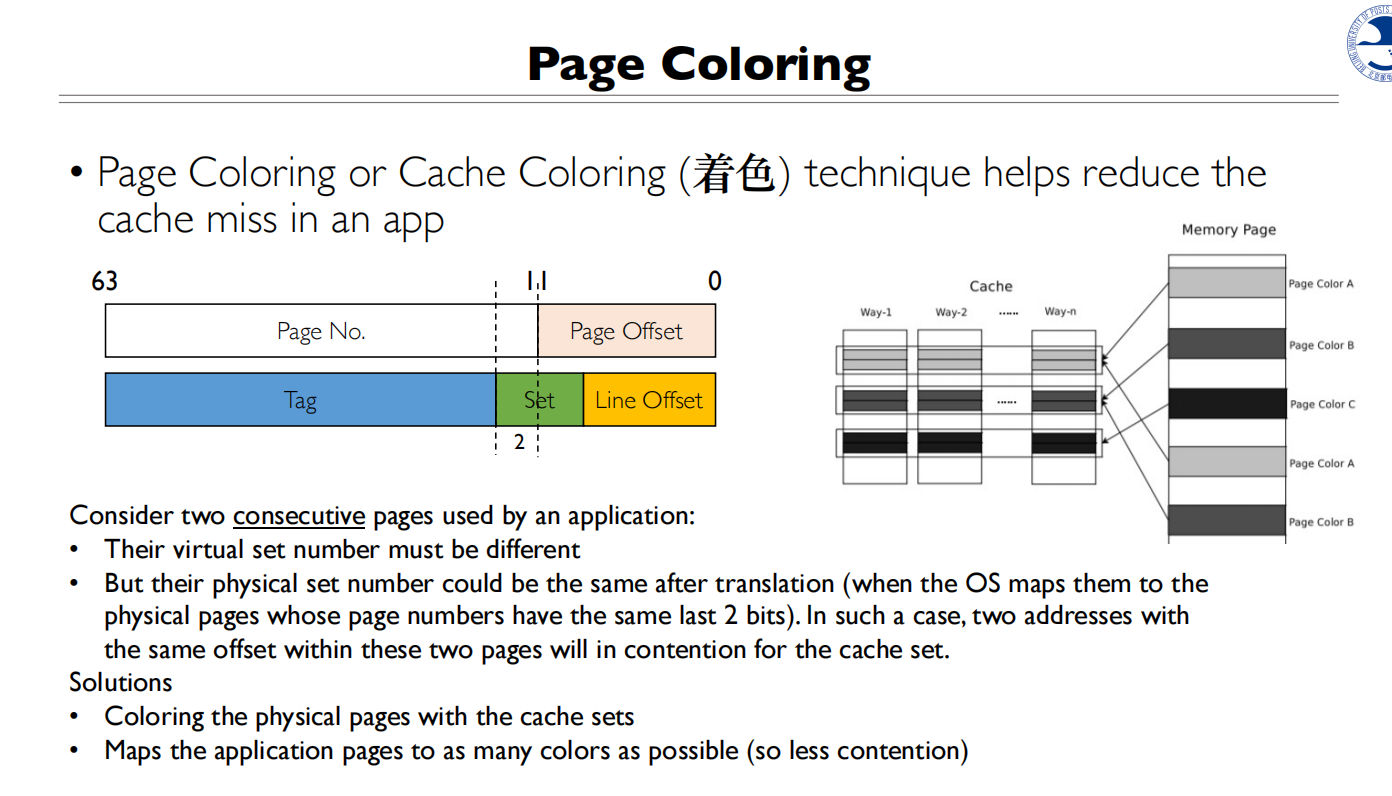

- 为什么页面着色只适用于L2/L3缓存而不适用于L1缓存?
- L1缓存使用VIPT(虚拟索引物理标记)结构,它已经通过硬件实现了对缓存访问的优化
- L1缓存的访问延迟要求极低,通常需要在1-2个CPU周期内完成
- 页面着色需要额外的地址映射操作,这会增加L1缓存的访问延迟
- L1缓存容量较小,着色带来的收益相对有限
- 为什么页面着色不适用于全相连缓存?
- 全相连缓存中,任何数据块可以被放置在任何缓存行中
- 页面着色的主要目的是通过控制页面到缓存组的映射来减少缓存冲突
- 在全相连缓存中,由于没有固定的组映射关系(所有位置都可以存放任何数据),着色技术就失去了意义
- 全相连缓存本身就能避免组冲突问题,因为它可以将数据放在任何位置,不需要额外的着色机制来优化映射关系
L1 Cache
 L1 Cache会区分指令和数据的Cache,因为L1 Cache是在CPU内的
L1 Cache会区分指令和数据的Cache,因为L1 Cache是在CPU内的

Exercise

- TLB shotdown是指在多处理器中,一个处理器修改了TLB,需要通知其他的处理器也要对应修改他们的TLB,目的是保持TLB的一致性。
- 延迟批处理(Lazy TLB shootdown):
- 不是每次页表修改都立即进行shootdown
- 收集一批需要失效的TLB条目,一次性处理
- 减少处理器间通信开销
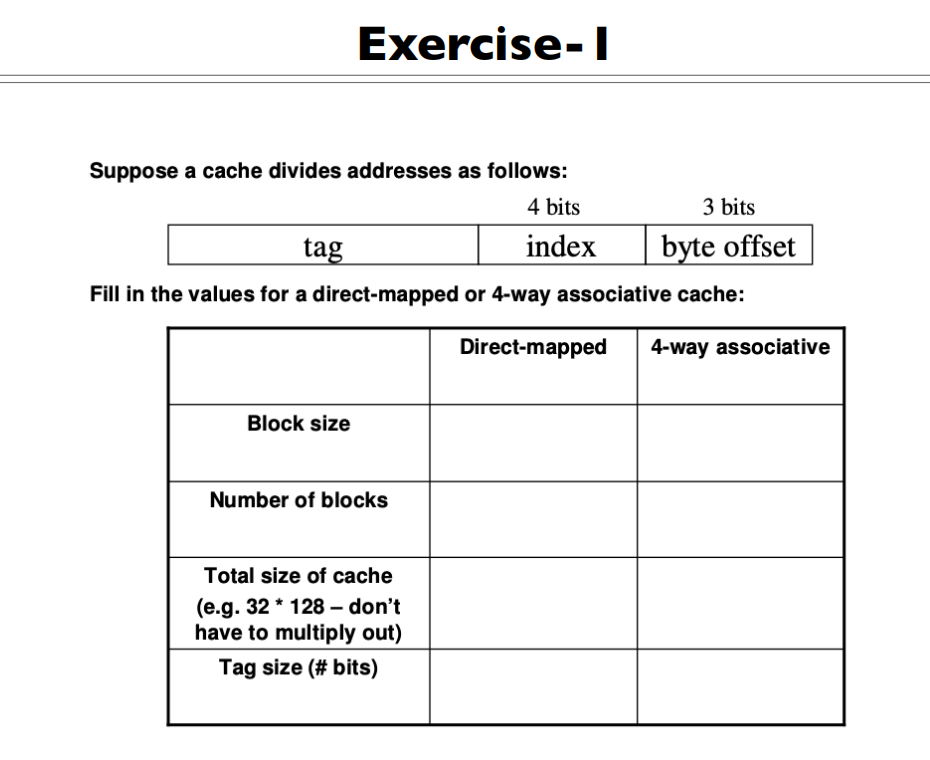 对于Direct-mapped
对于Direct-mapped
- Block size:
- Number of blocks:
- Total size of cache =
- Tag Size:
对于4-way associative
- Block size:
- Number of blocks:,一路有个Cache Line,共有4路
- Total size of cache =
| Direct-mapped | 4-way associative | |
|---|---|---|
| Block size | 8 bytes | 8 bytes |
| Number of blocks | 16 | 64 |
| Total size of cache | 16 * 8 bytes | 64 * 8 bytes |
| Tag size(#bits) | 地址长度-7 | 地址长度-7 |
 对于直接映射的情况
对于直接映射的情况
- 4 byte blocks ,所以Byte Select 是2 bit
- 128 blocks,所以Index是7 bit
- 综上,所以Tag 是32-10=22 bit
0000 1000 0101 1100 0001 000//1 0111 10//01
如果是8路组相联,那么Index 会变为,所以是4bit 0000 1000 0101 1100 0001 0001 01//11 10//01
 Byte Select:4 bit
Cache Index:3 bit
Cache Tag: 32-7=25 bit
Byte Select:4 bit
Cache Index:3 bit
Cache Tag: 32-7=25 bit
第一个 0x3ab12395 = 0010 1011 1100 0001 0010 0011 1//001 //0101
第二个 0x70ff1213 = 0111 0000 1111 1111 0001 0010 0//001 //0011
这两个块的Index相同,但是由于是4路组相联,所以不会在cache发生冲突
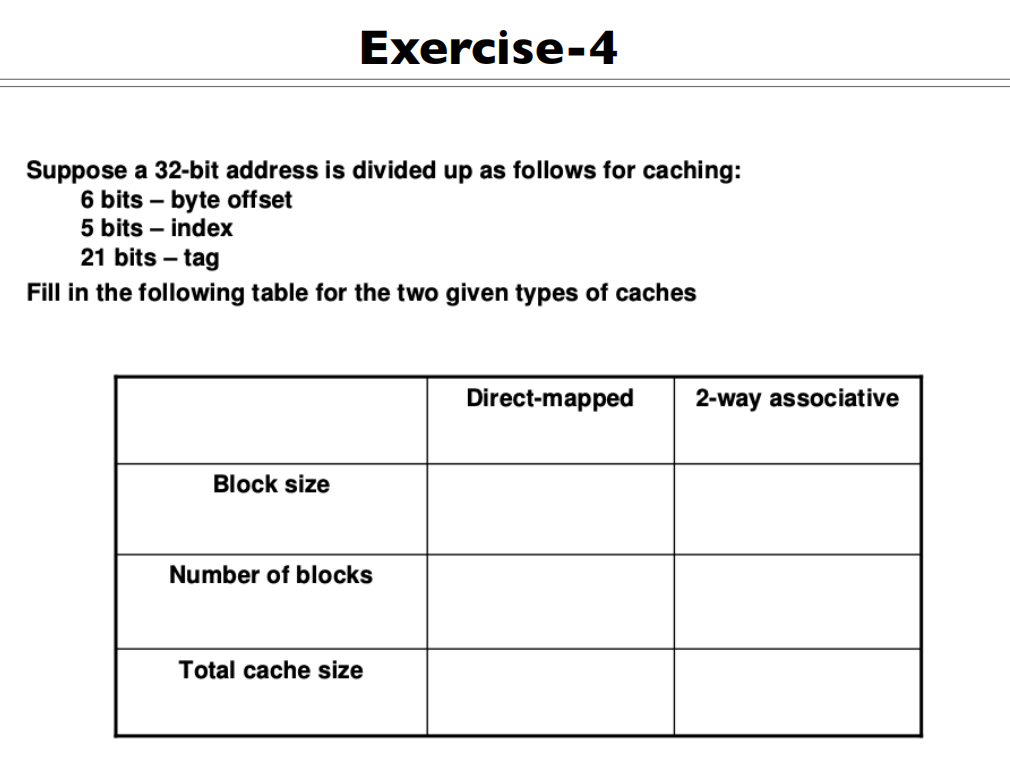
| DIrect-mapped | 2-way associative | |
|---|---|---|
| Block size | ||
| Number of blocks | ||
| Total cache size |
 Direct-mapped
Direct-mapped
- 4
- 7
- 53
4-way associate
- 4
- 5
- 55