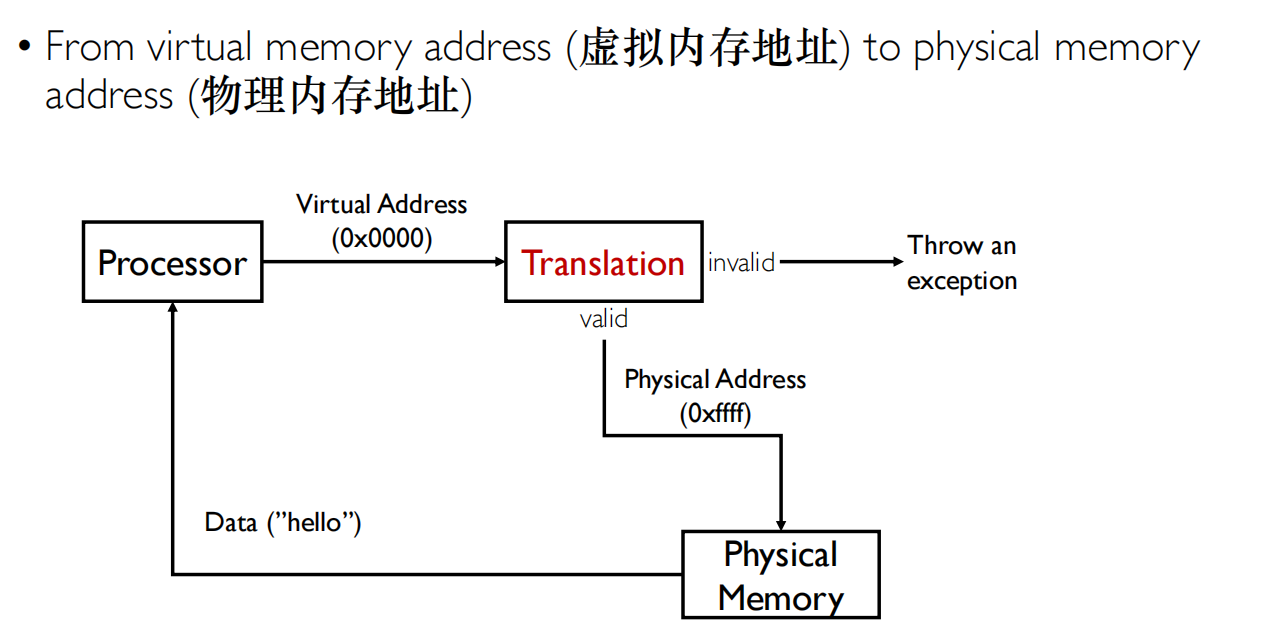
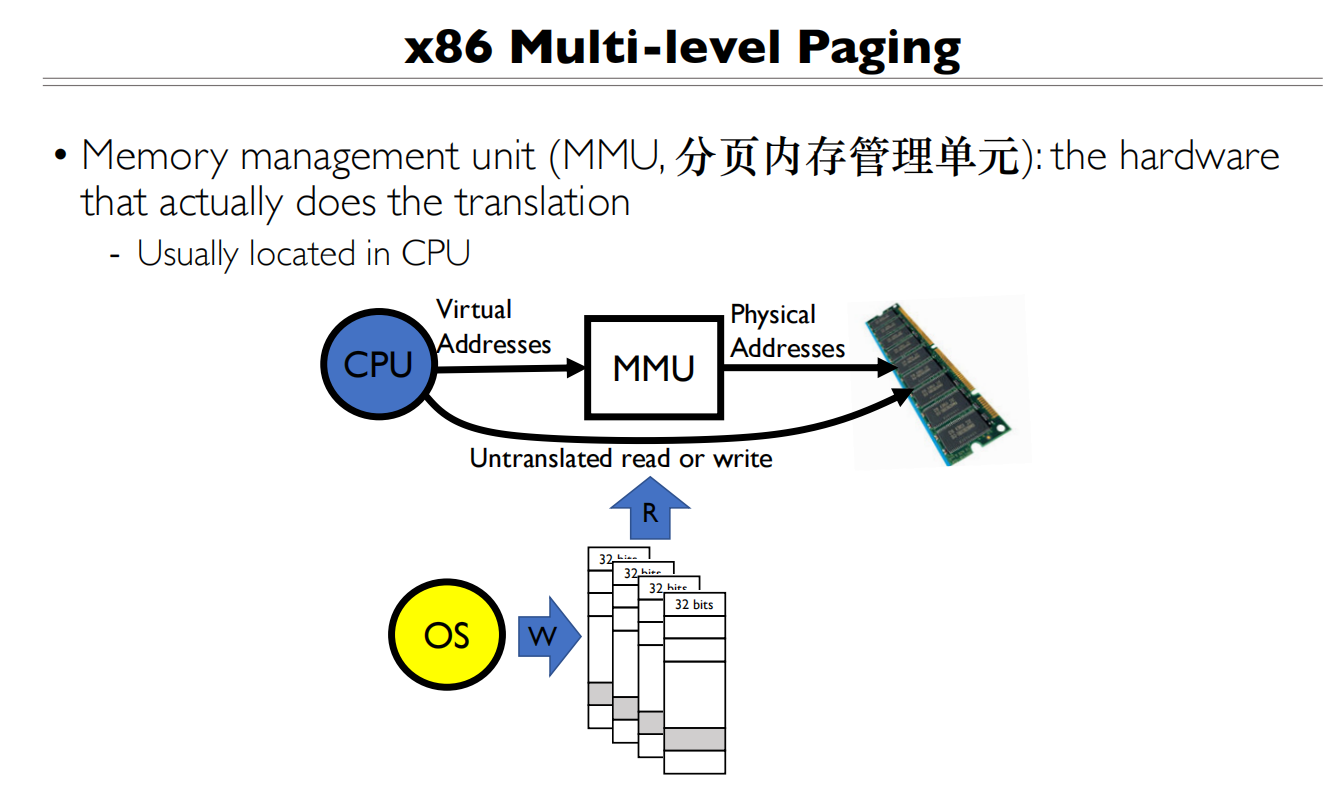
Address Translation Concept
 The goals and motivations of address translation
The goals and motivations of address translation
- Memory protection
- Memory sharing
- Flexible memory placement
- Sparse address(稀疏地址)
- Runtime lookup efficientcy
- Compact translation tables
- Portability
地址翻译的目的:
- 让程序认为自己有一段连续的、很大的地址空间。
When translation exists, processor uses virtual addresses, physical memory uses physical address.虚拟地址主要是软件和CPU内部使用
需要Hardware-OS cooperation
Address space: all the addresses and state a process can touch
- Each process and kernel has different address space
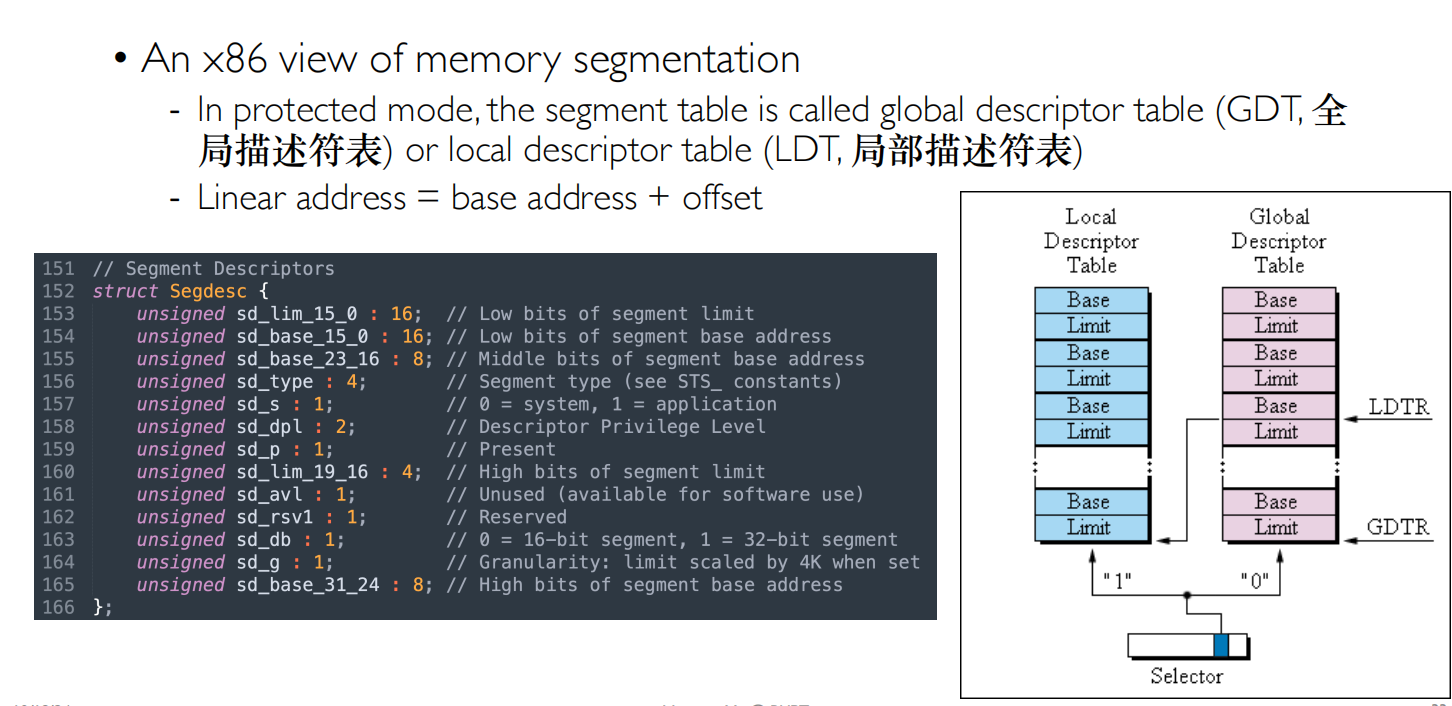
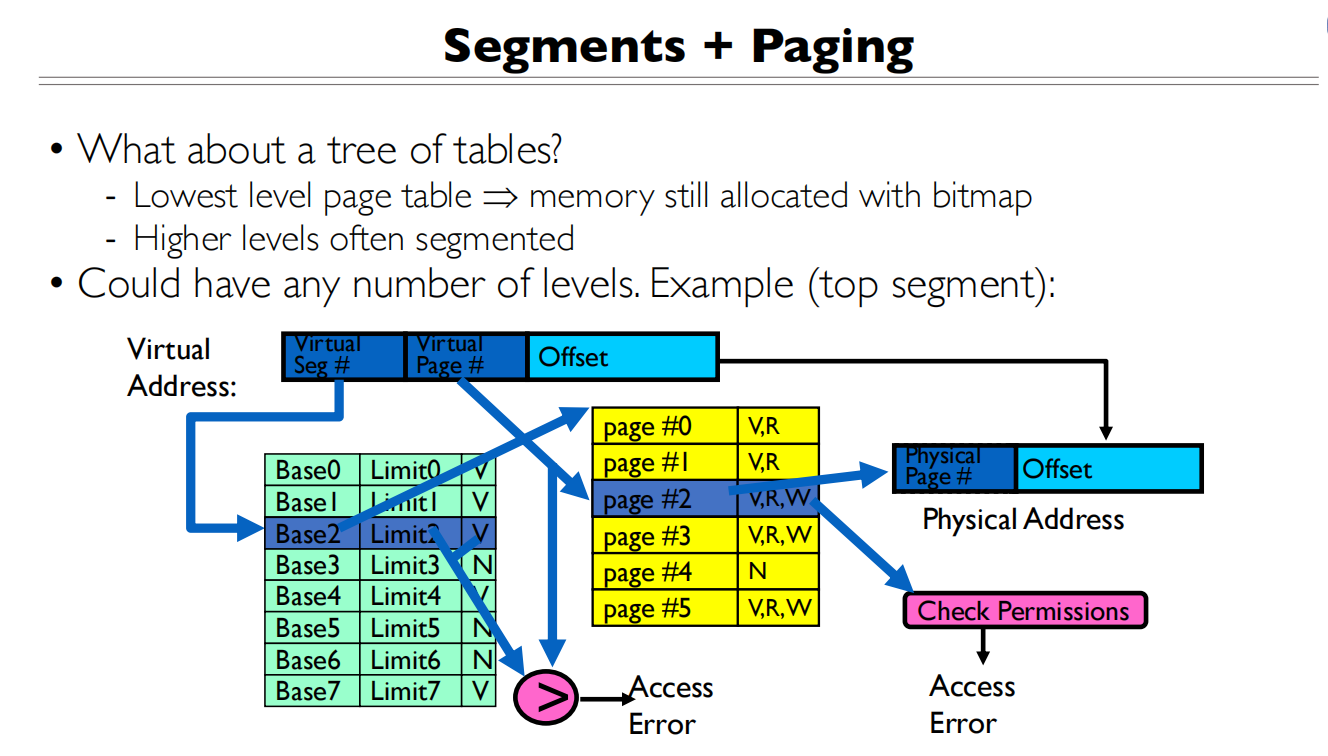
Segmentation(分段)
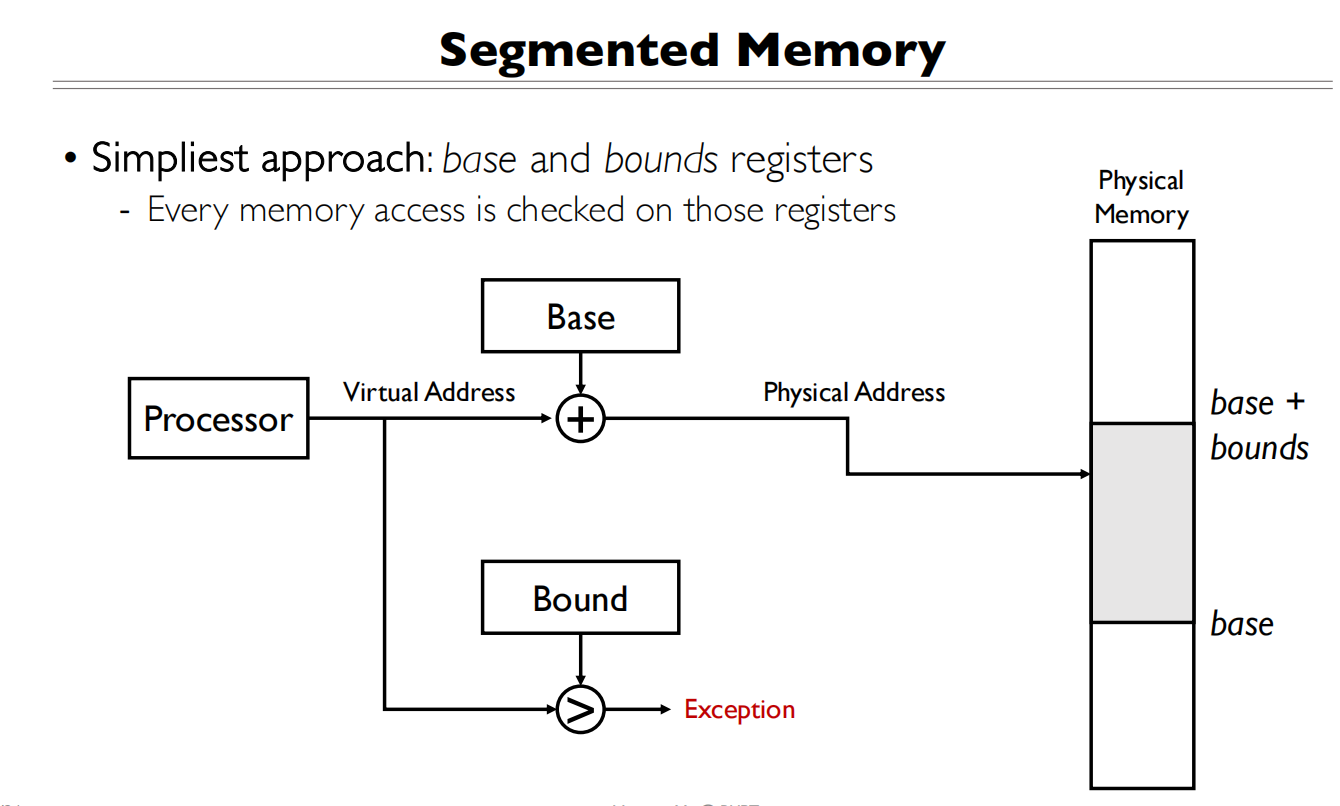 简单的分段实现在第一节课有提及过,通过base+bounds去划分内存段
简单的分段实现在第一节课有提及过,通过base+bounds去划分内存段
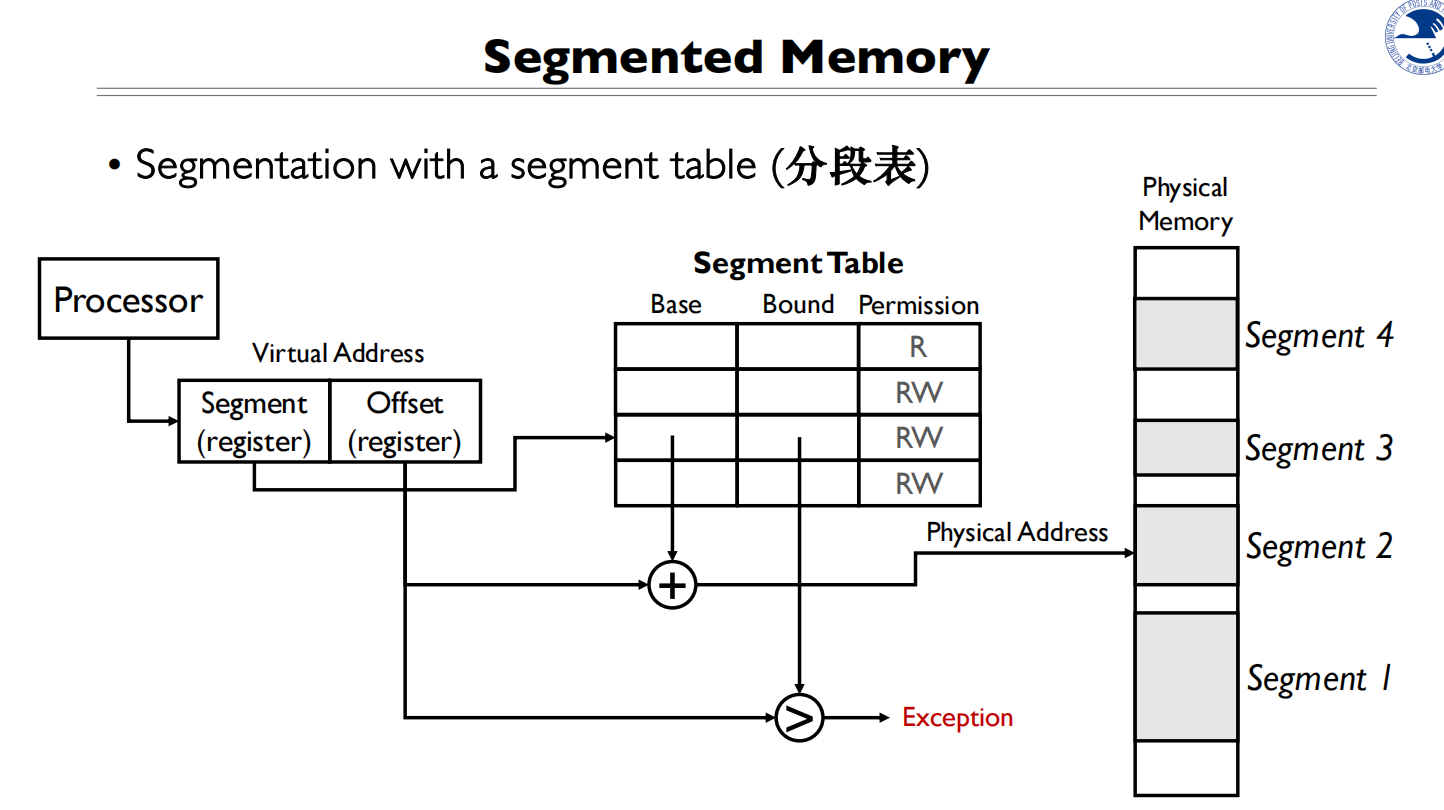
upgrade的做法就是创建了一个分段表,使用内存的时候去查表
 Why there are “holes” in the physical memory?
Why there are “holes” in the physical memory?
- Processes come and go
- 进程的加载和终止会造成内存碎片
- 当进程结束时,释放的内存段会在物理内存中形成空隙
- 不同大小的段被分配和释放会导致内存不连续
- 内存碎片化是分段内存管理的一个常见问题
What if a program branches into those “holes”?
- Segmentation error(异常)
- 会触发段错误(Segmentation Fault)
- 因为这些”洞”不是有效的内存区域
- 操作系统会检测到非法访问并终止程序
- 这是内存保护机制的一部分,防止程序访问未分配的内存区域
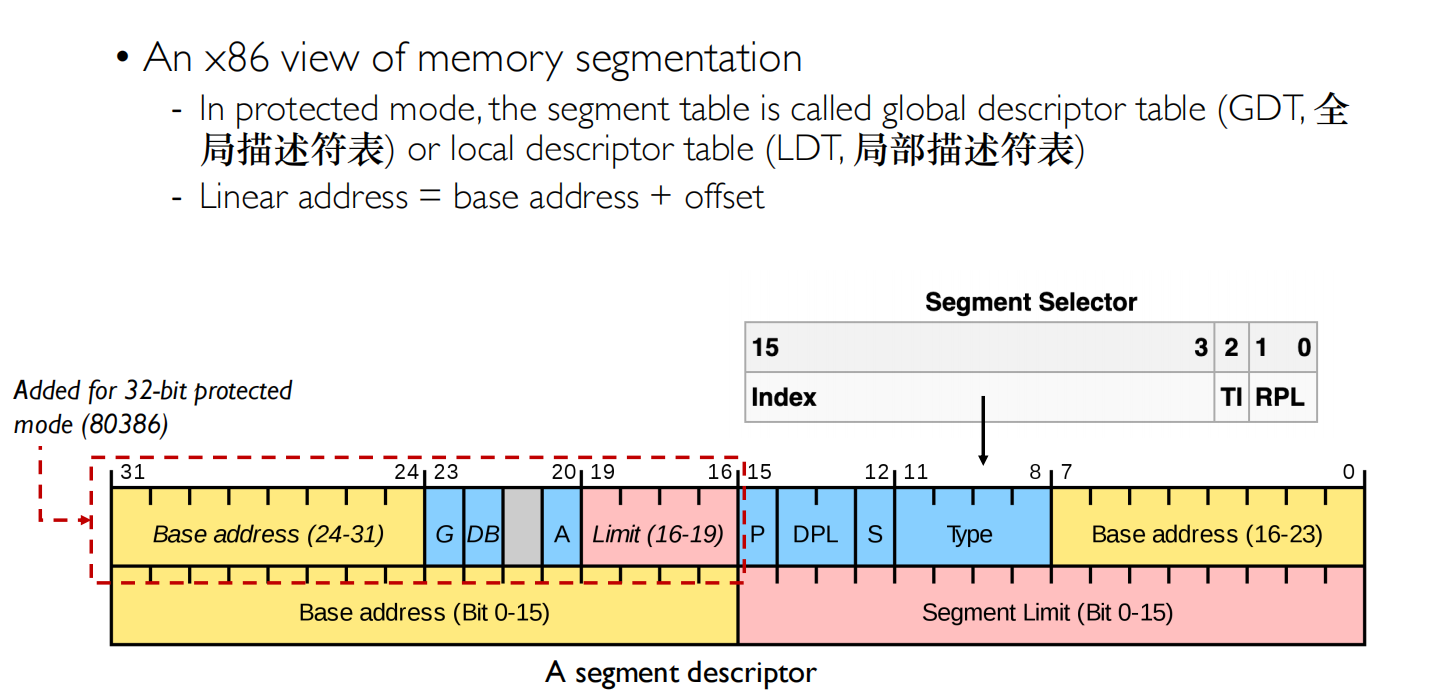
The real segmentation implementation could vary a lot
- Some OSes like Multics allocates a segment for each datastructure to allow fine-grained protection and sharing between processes
- Most modern systems use segments only for coarse-grained(粗粒度的) memory regions
维护大量的可变的内存段 is a hard thing
产生大量外部碎片,导致内存的使用率下降


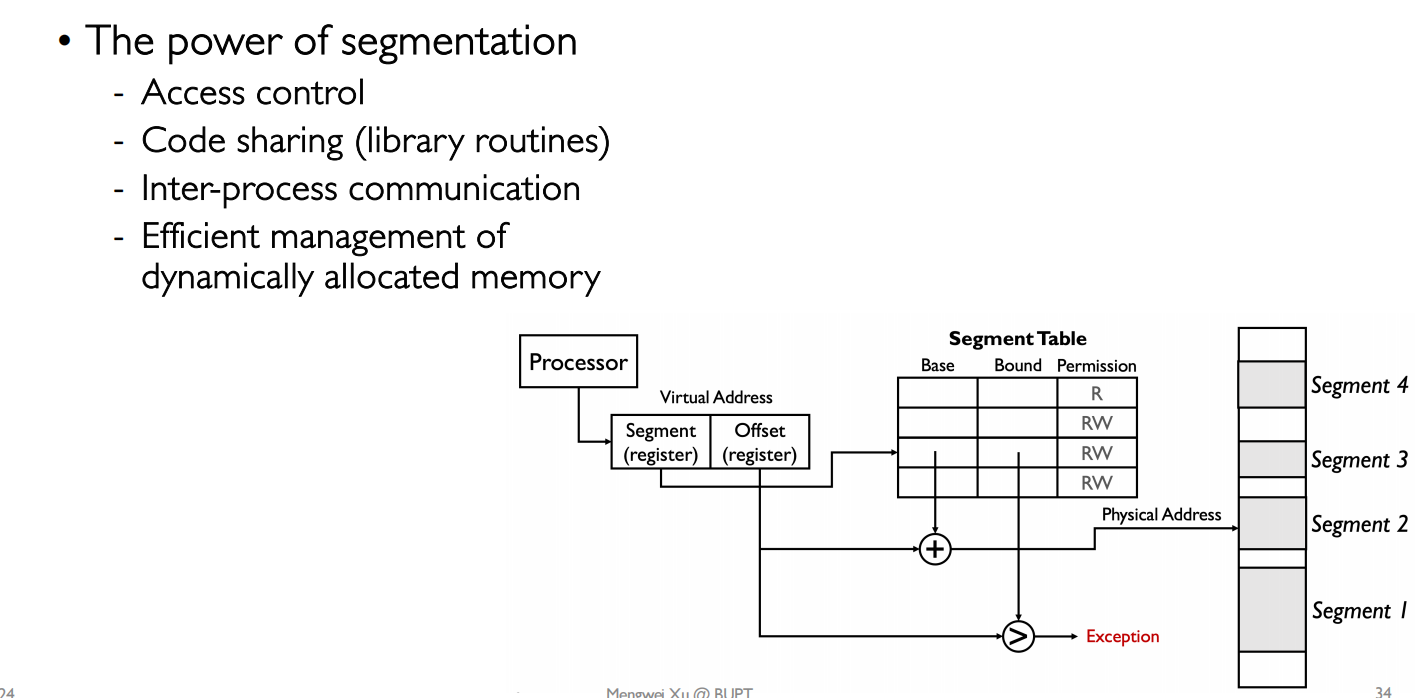 The priciple downside of segmentation: overhead of managin a large number of variable size and dynamically growing memory segments.
The priciple downside of segmentation: overhead of managin a large number of variable size and dynamically growing memory segments.
- External fragmentation: free space becomes noncontiguous
- Compacting the memory is very slow
- It becomes even more complex if the segments can grow (like heap)
Paging(分页)
与分段的区别:Fixed-sized chunks 固定大小 allocating memory in fixed-sized chunks called page frames(页框)
What’s cool:the pages are scattered(散落) across physical memory regions
- Yet within a page, the memory access is contiguous
- For instance, a large matrix might span many pages
Memory allocation becomes very simple:find a page frame
一级页表
每一个进程都有自己的页表,管理不同的映射
下面是一级页表
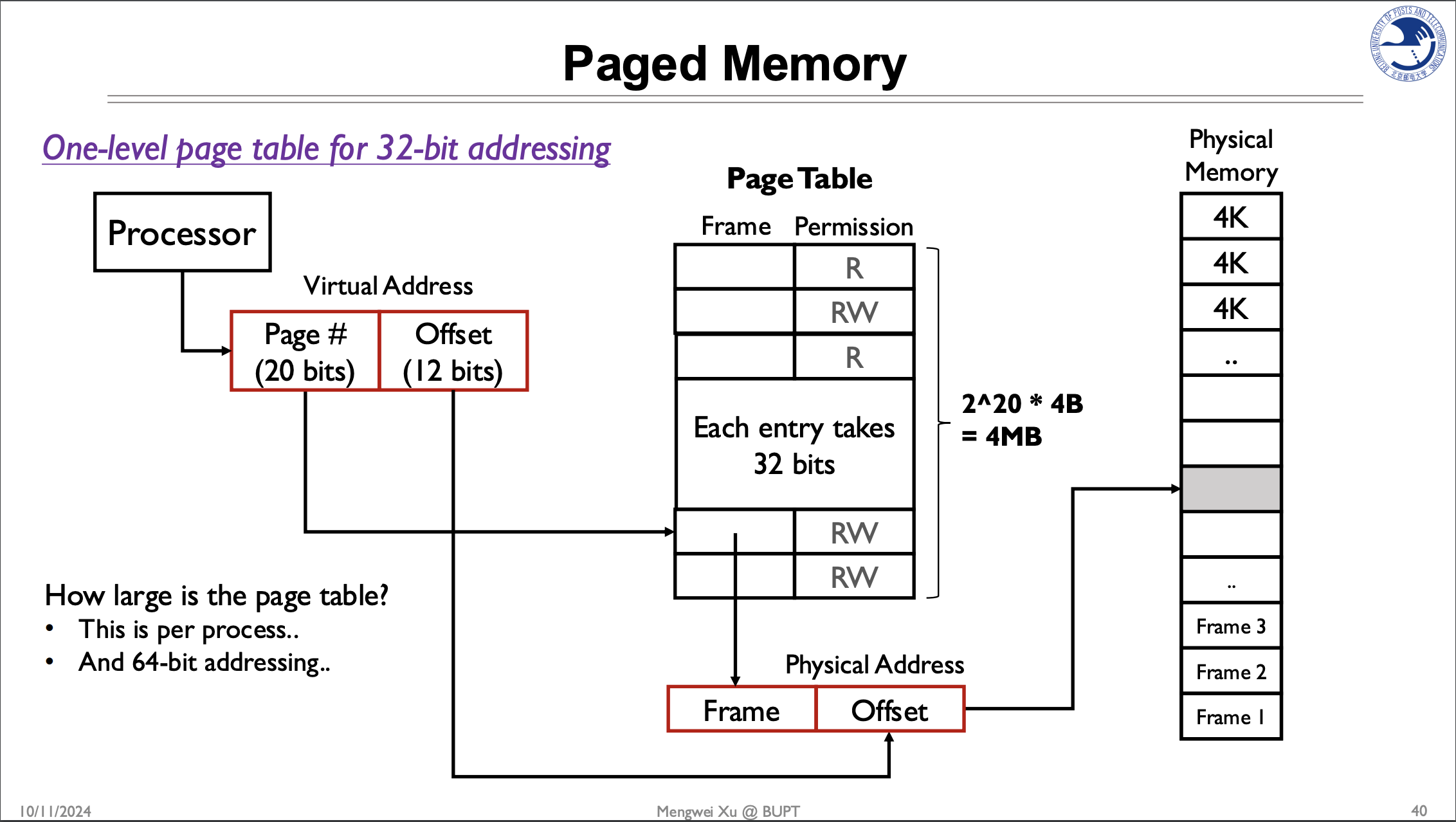 Offset(页内偏移)是由页的大小决定的,这里是4KB,所以偏移量就是
Offset(页内偏移)是由页的大小决定的,这里是4KB,所以偏移量就是
Question
为什么是bytes?
- 在大多数计算机体系结构中,内存是以字节(byte)为最小单位进行寻址的
- 也就是说,每个唯一的内存地址指向一个字节的空间
- 这是一个硬件设计决策,成为了标准
所以12位能表示的不同地址数 = 2^12 = 4096个地址,每个地址对应一个字节(byte),因此12位偏移量可以寻址4096个字节,也就是4KB大小的
页表的大小:
每个进程都有一个页表,当进程多了会使得页表占用的空间过大。
- 同一进程下的doge线程共享页表
一个页表并非每一个页表项都有用,一个进程一般用不完一个页表,用的是哪一个也是无法决定的。空开的页表项实际上是浪费了
为什么不用链表?
- 翻译由硬件进行(TLB),数组做起来很快
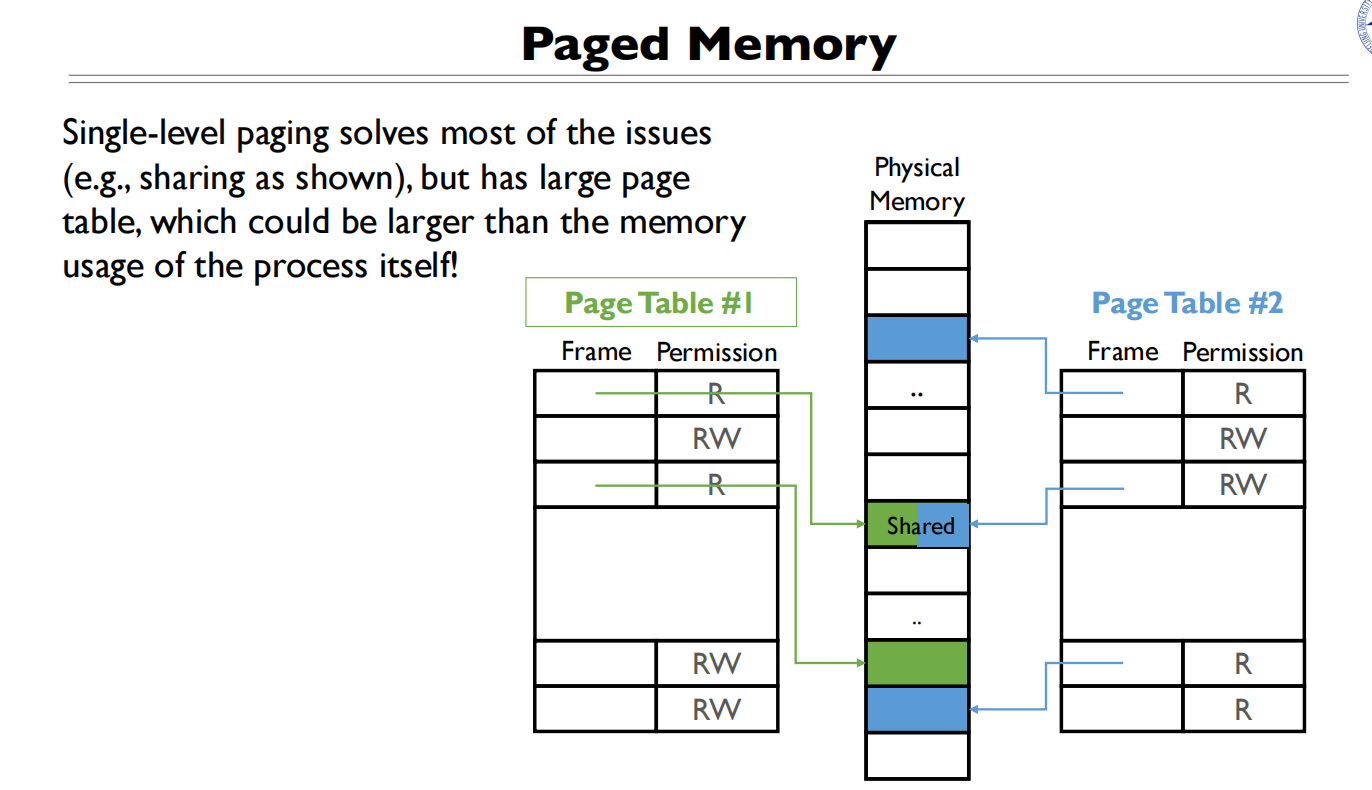
多级页表
页表太大⇒多级分页
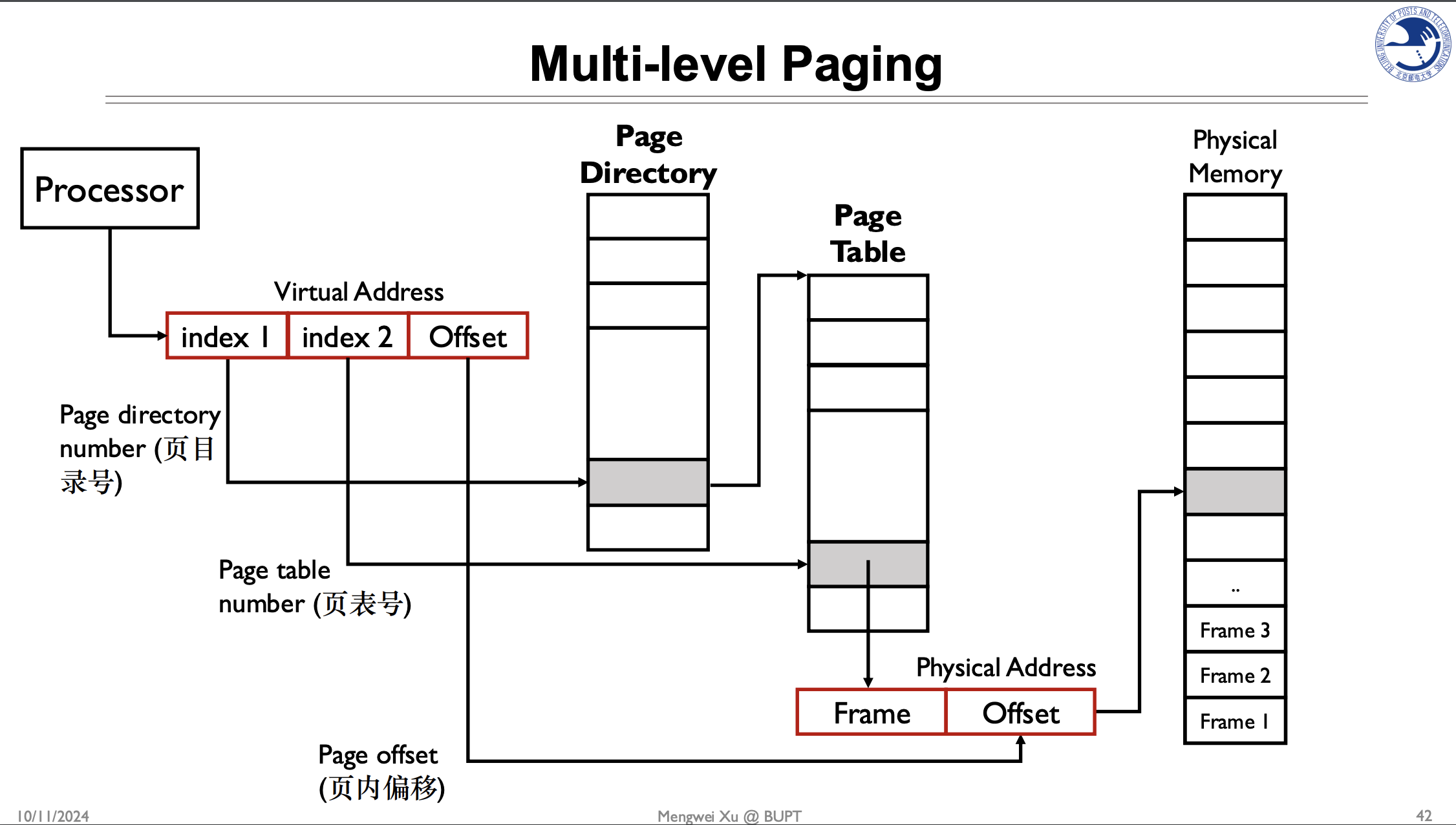
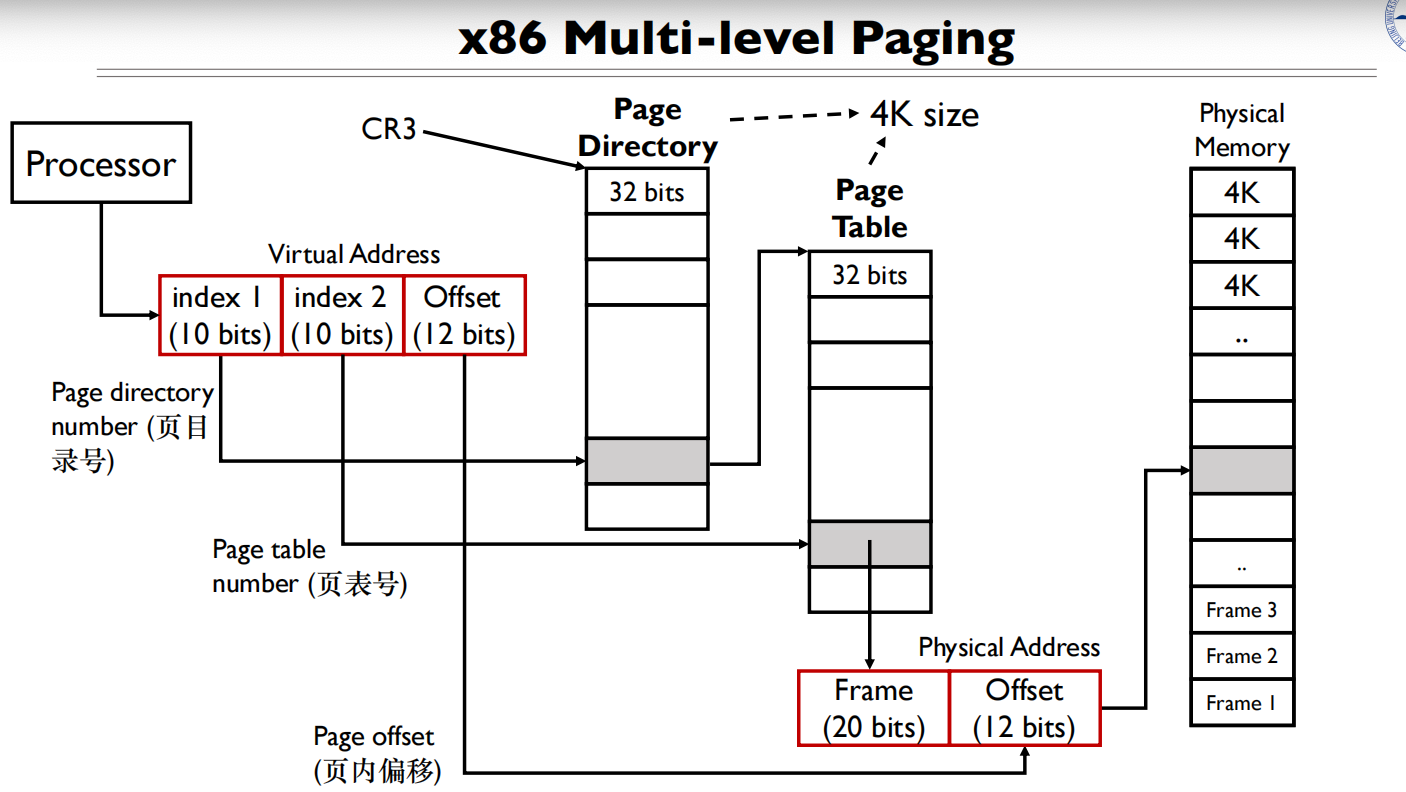 页目录→页表→页表项,每个进程都有自己独立的页表结构(独立的页目录基址)
页目录→页表→页表项,每个进程都有自己独立的页表结构(独立的页目录基址)
- 每个进程都有一个独立的页目录,包含了该进程的二级页表的地址映射信息。
- 当进程切换时,操作系统会将 CR3 寄存器(页目录基址寄存器)更新为新进程的页目录的基地址。这确保了每个进程只能访问自己的地址空间。
寻址过程是需要重点记忆的
在二级页表中,一个页的大小是,将原本的4MB拆为了4KB
如果一个进程将所有的页表全都用完会,他的页表会占用,和一级页表占满所使用的内存大小相同。但是一般占不满,假如只用了一个页表,那么就使用了大小的页表空间,能寻址大小的内存。
为什么二级页表能将页表的内存省下来?
- 数组,不用也需要分配,所以一级页表需要完全分配4MB的页表
- 但是二级页表可以不分配页目录没使用到的第二级页表
相当于树结构,页目录下有1024个页表,页表下有1024个页表项
缺点:
- 寻址速度会变慢
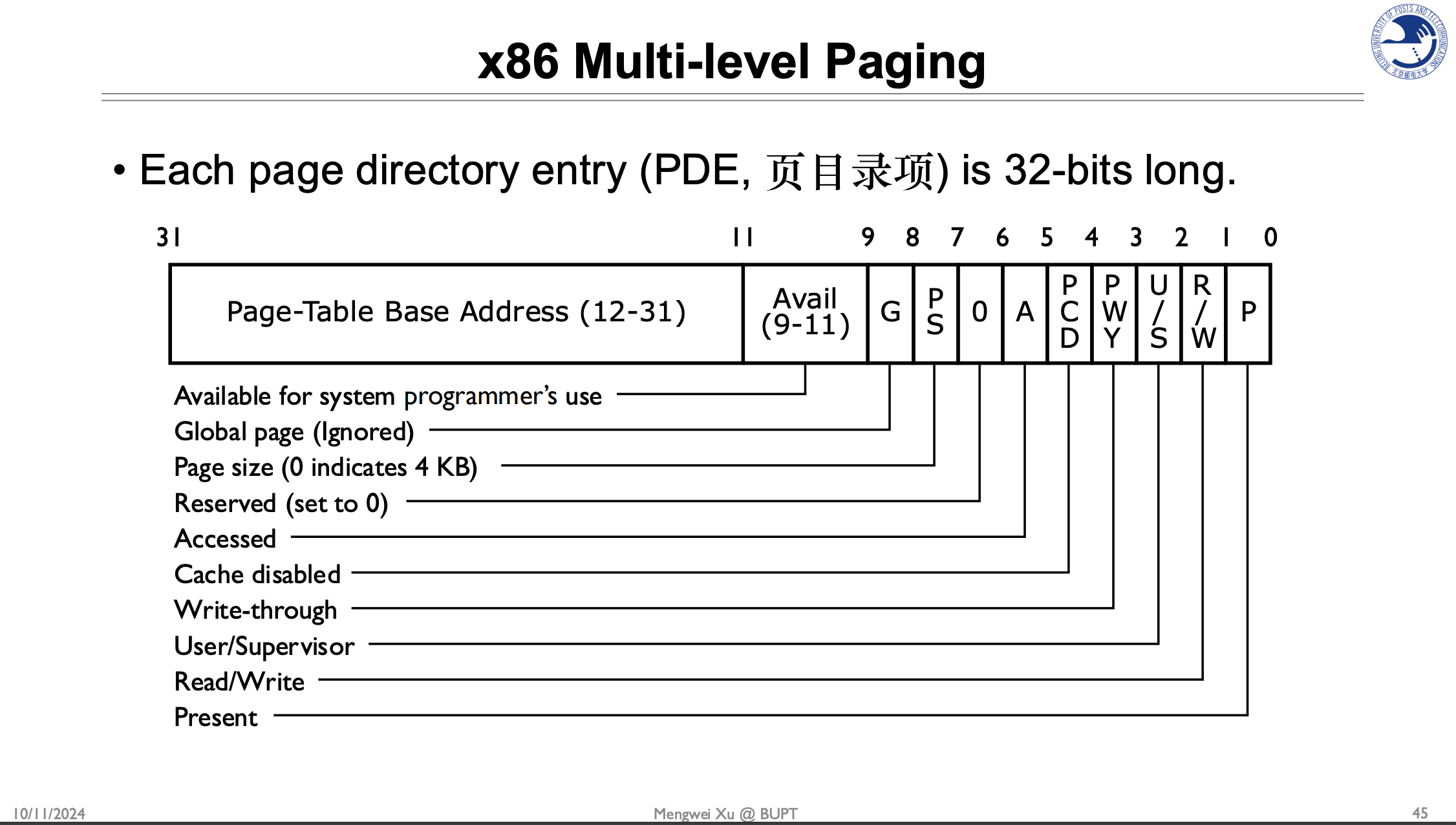 Present:映射关系是否存在
Read/Write:是否可读/可写
Present:映射关系是否存在
Read/Write:是否可读/可写
Question
为什么页表基地址是20位?
由页表的大小决定的,每个页表大小为4KB,所以offset要与4KB对齐,就是个位置
4KB对齐要求:
每个页表必须在4KB边界上对齐
4KB = 4096 = 2^12 字节
这意味着页表的物理地址的低12位总是0
地址位的计算:
- 32位物理地址系统中,完整地址是32位
- 由于4KB对齐,低12位都是0
- 所以只需要存储高20位 (32 - 12 = 20)
- 这就是为什么页表基地址字段是20位(位12-31)
 OS来管理页表,来做页面分配之类的策略
OS来管理页表,来做页面分配之类的策略
翻译的过程是由硬件MMU完成的,但是还是要读页表页目录
Page size shall be neither too small or too large
- Too small: large page table sizes;low cache hit ratio
- Too large: memory waste
- Typical range: 512B to 8192B; default 4KB on Linux
Each process has their own page table
- Not threads
- The same address of different processes translate to different physical locations, unless the page is shared
- A process can only access/modify its own page table!
- In Linux, there is only one kernel space for all process

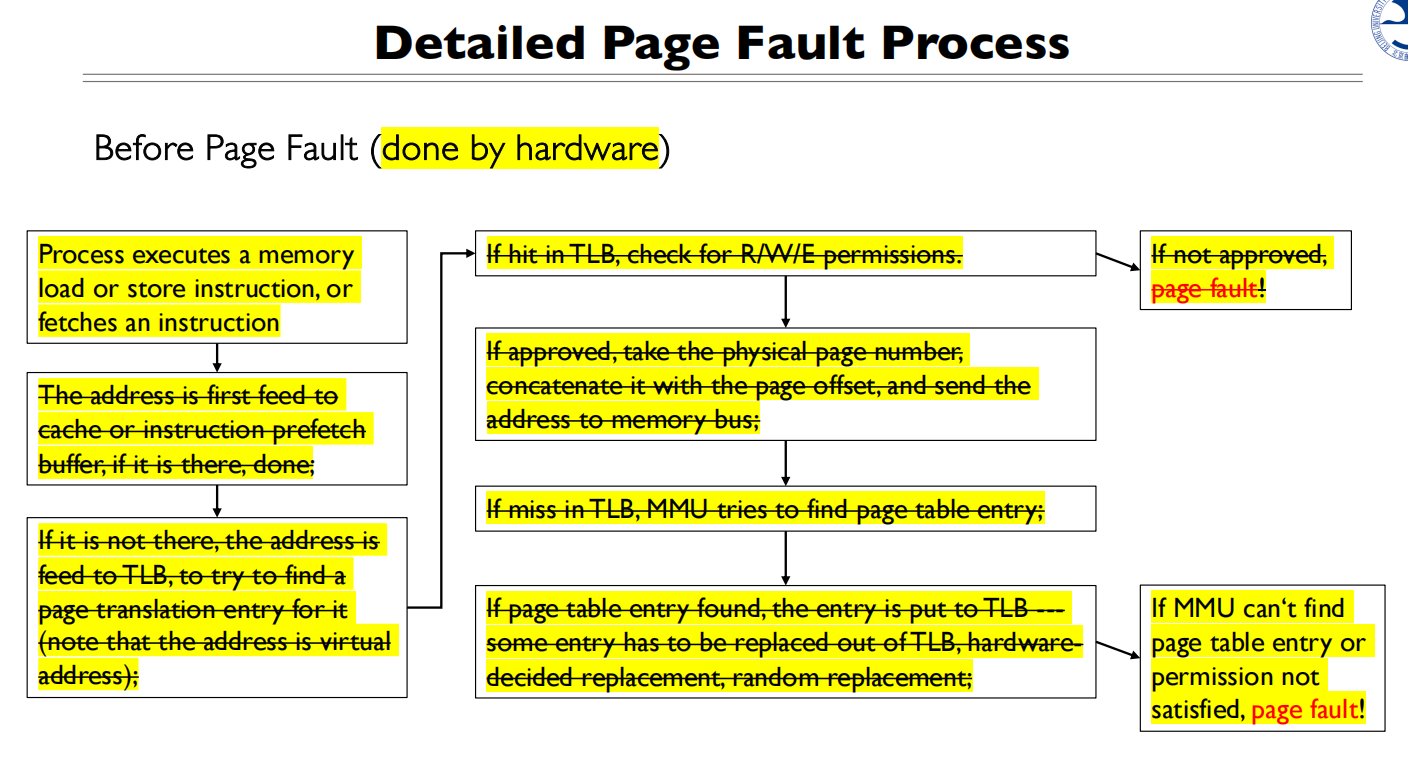
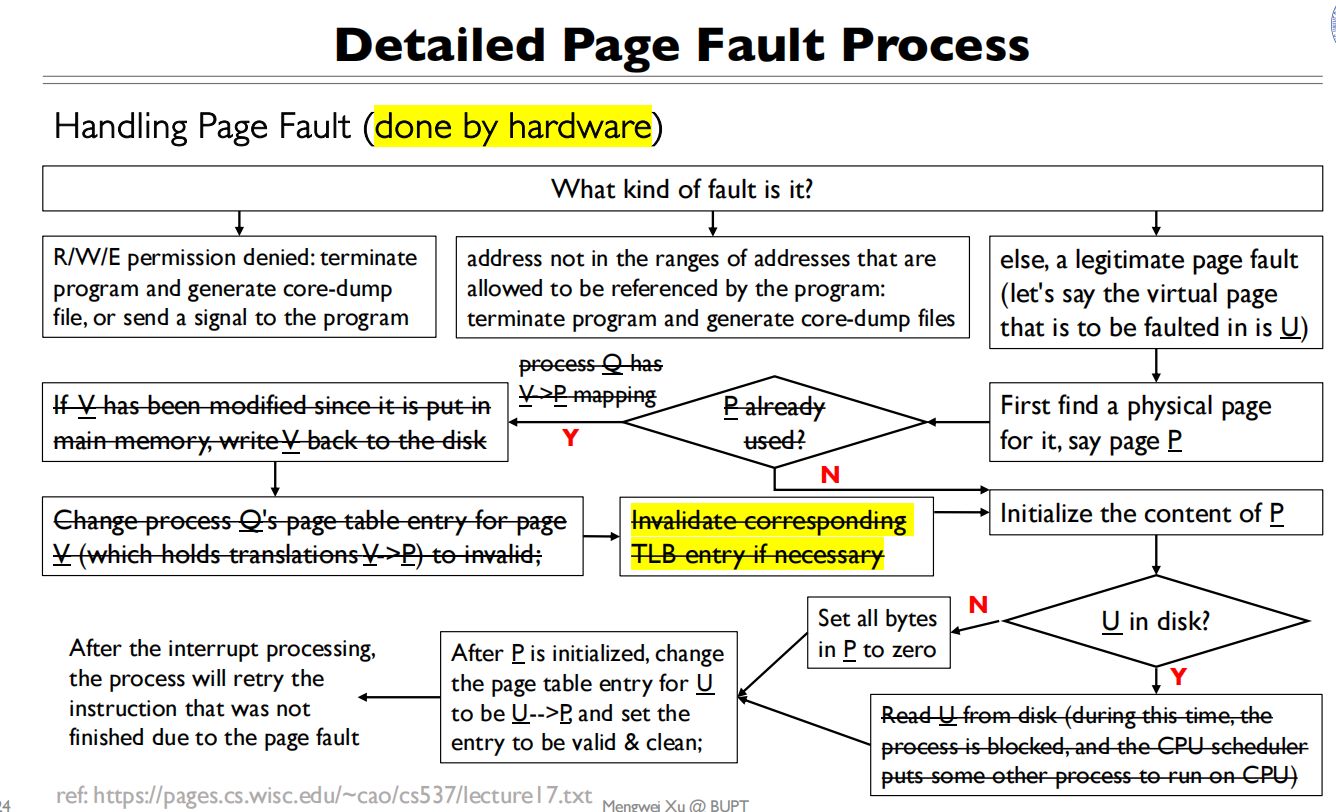
缺页中断
 当访问到没有被映射的地方会缺页中断(字面意义上理解,缺失了这一页)
当访问到没有被映射的地方会缺页中断(字面意义上理解,缺失了这一页)
缺页中断是异常
malloc的”lazily”:会立刻分配一个虚拟地址,但是对应的物理内存会在使用的时候才会被分配(触发page fault)



一些问题
 为什么PDE/PTD使用20bits 作为基地址 分析可见 多级页表 里面的Question
为什么PDE/PTD使用20bits 作为基地址 分析可见 多级页表 里面的Question
页目录的物理地址是存在CR3里面的

- CR3存的是页目录的物理地址
- PDE/PTE存储的地址是物理地址
- 被内核使用的指针式物理的
- 内核可以通过以下方式操作页目录/页表:
- 直接写入存储这些结构的物理内存
- 修改条目中的权限位和标志位
- 设置或清除存在位(present bit)
- 更新物理地址映射
- 在做出更改后必要时刷新 TLB(转换后备缓冲器)
页表是存储在物理内存里面的,要访问内存的其他数据,首先要访问页表。
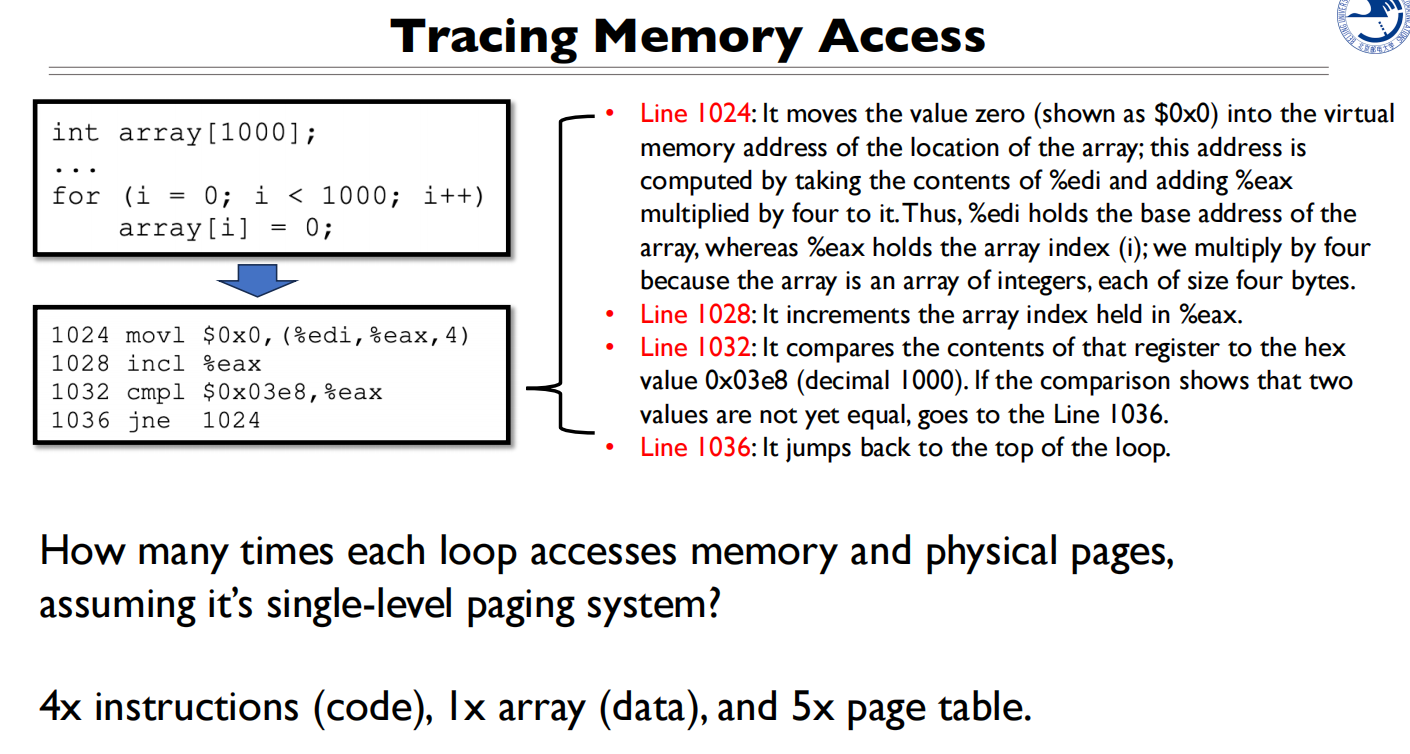 访问了多少次内存:对数组的访问,对指令的访问(从内存中读取指令解码执行),对页表的访问
访问了多少次内存:对数组的访问,对指令的访问(从内存中读取指令解码执行),对页表的访问
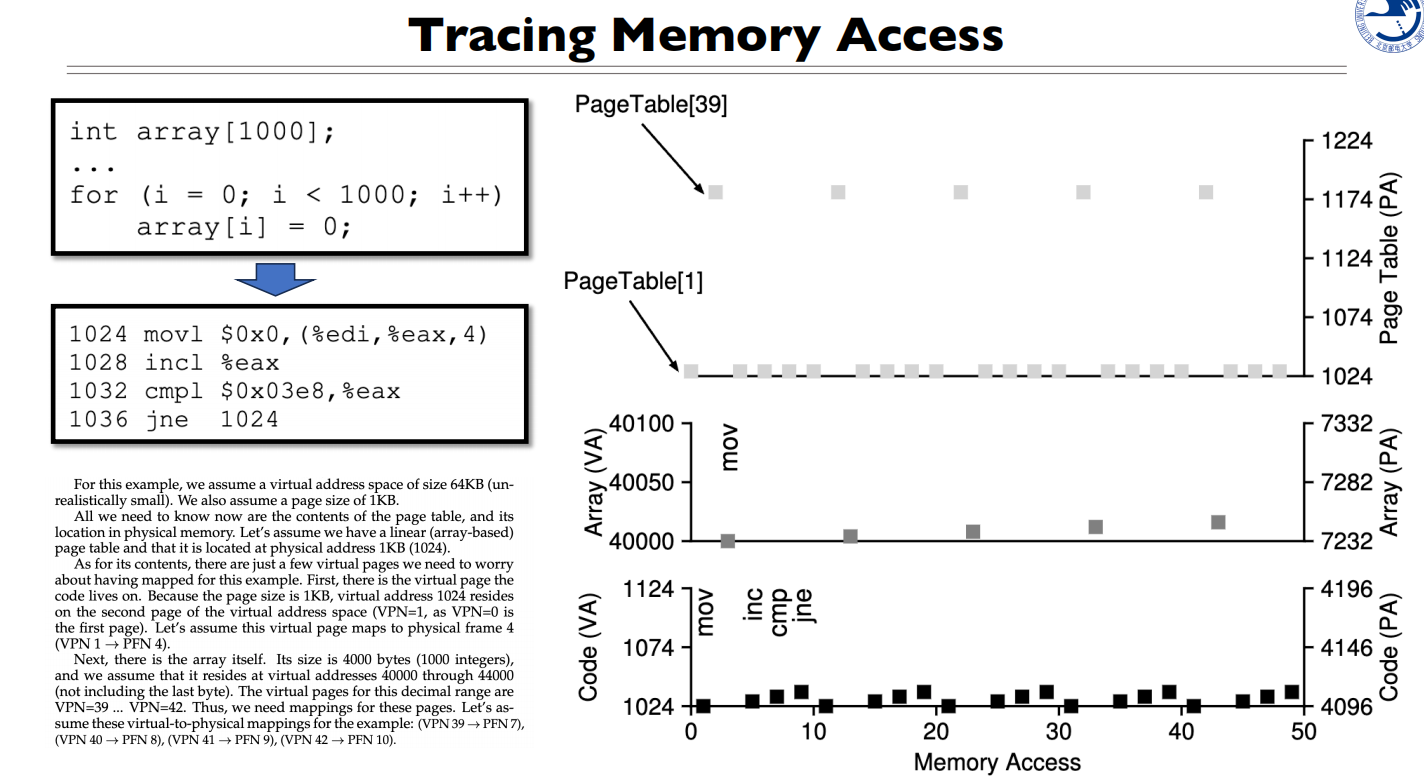
如何求物理地址
给一个虚拟地址,如何通过代码的方式得到物理地址
难点:给任何一个地址,CPU都会默认为虚拟地址,进行地址翻译
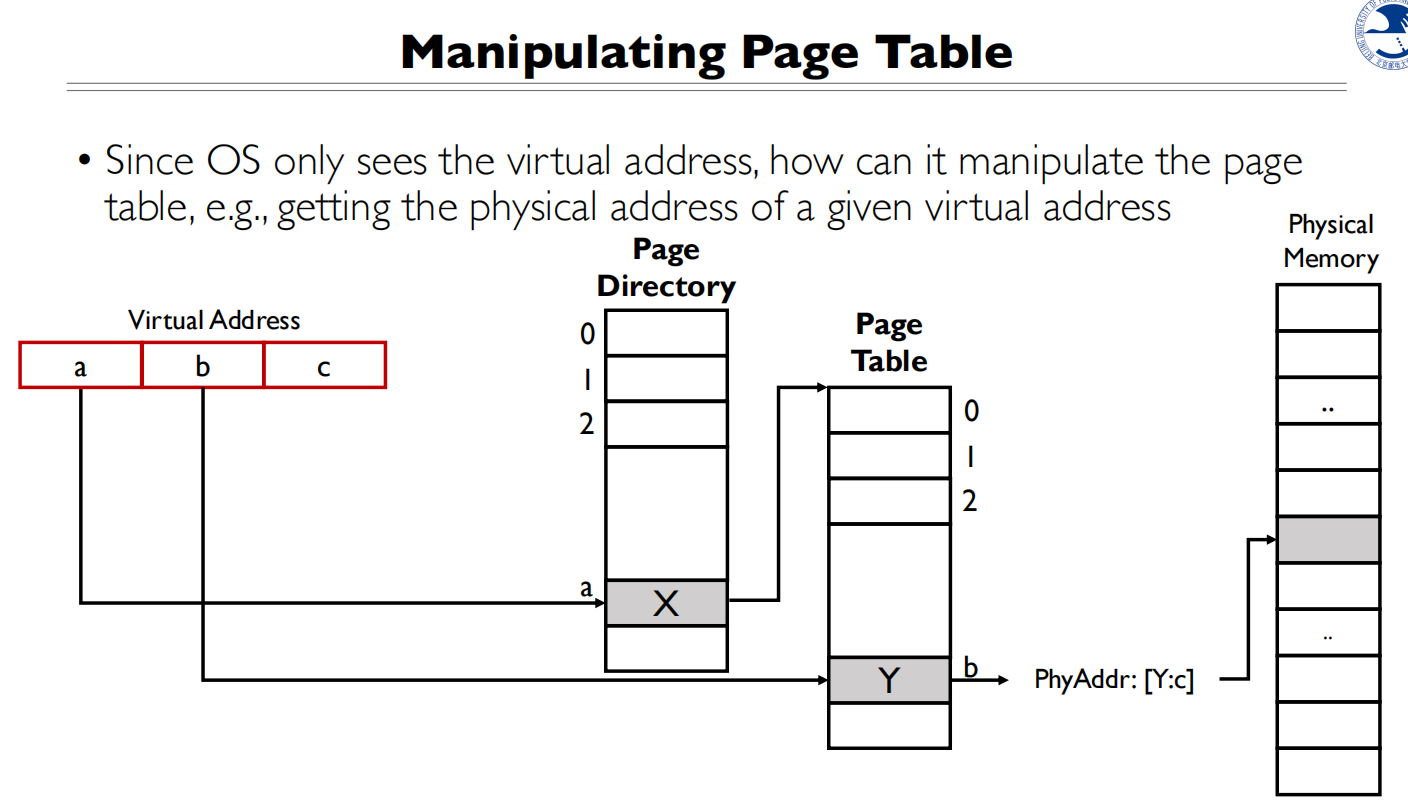 我想得到X和Y的地址
我想得到X和Y的地址
拿到的CR3是物理地址,无法直接使用,所以并不能得到X的地址,CPU会进行翻译
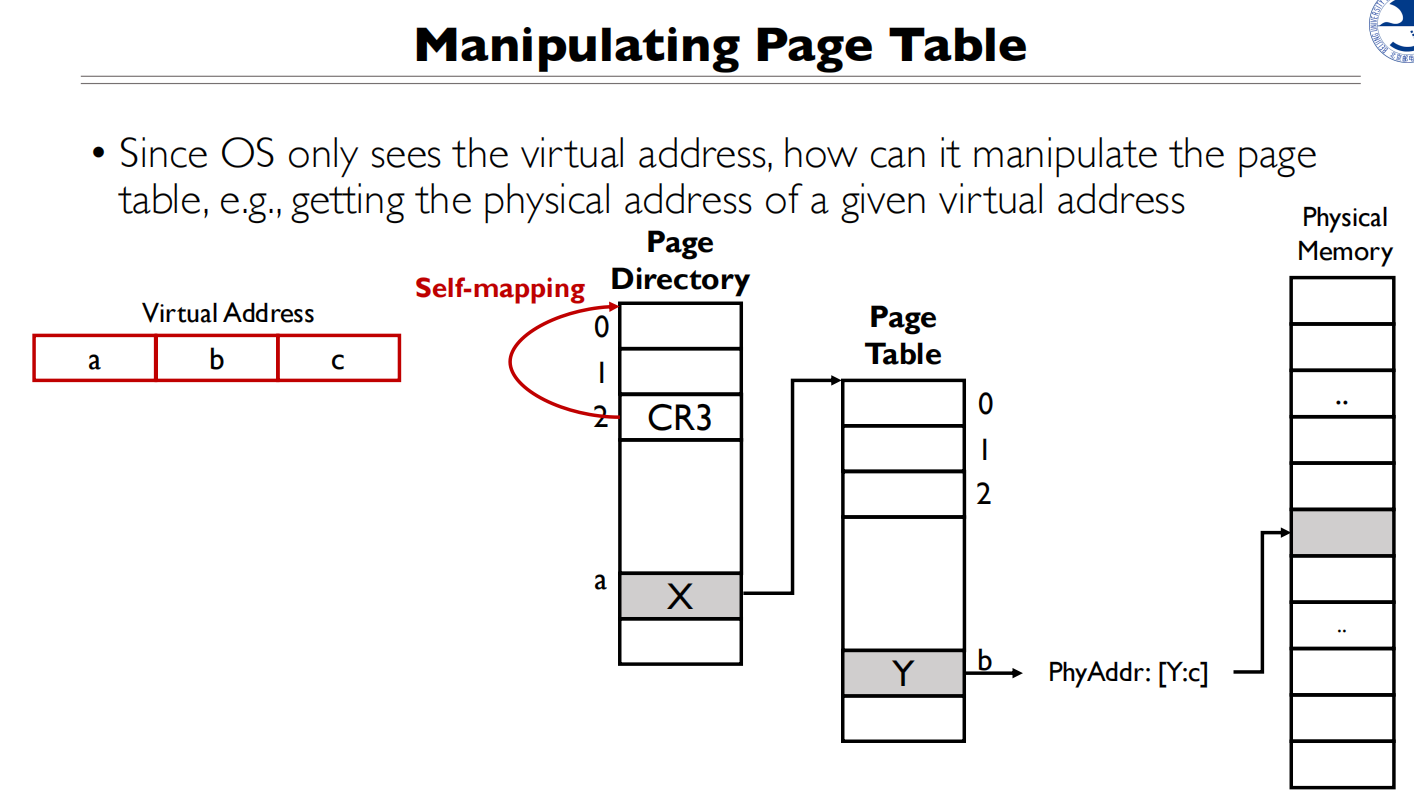
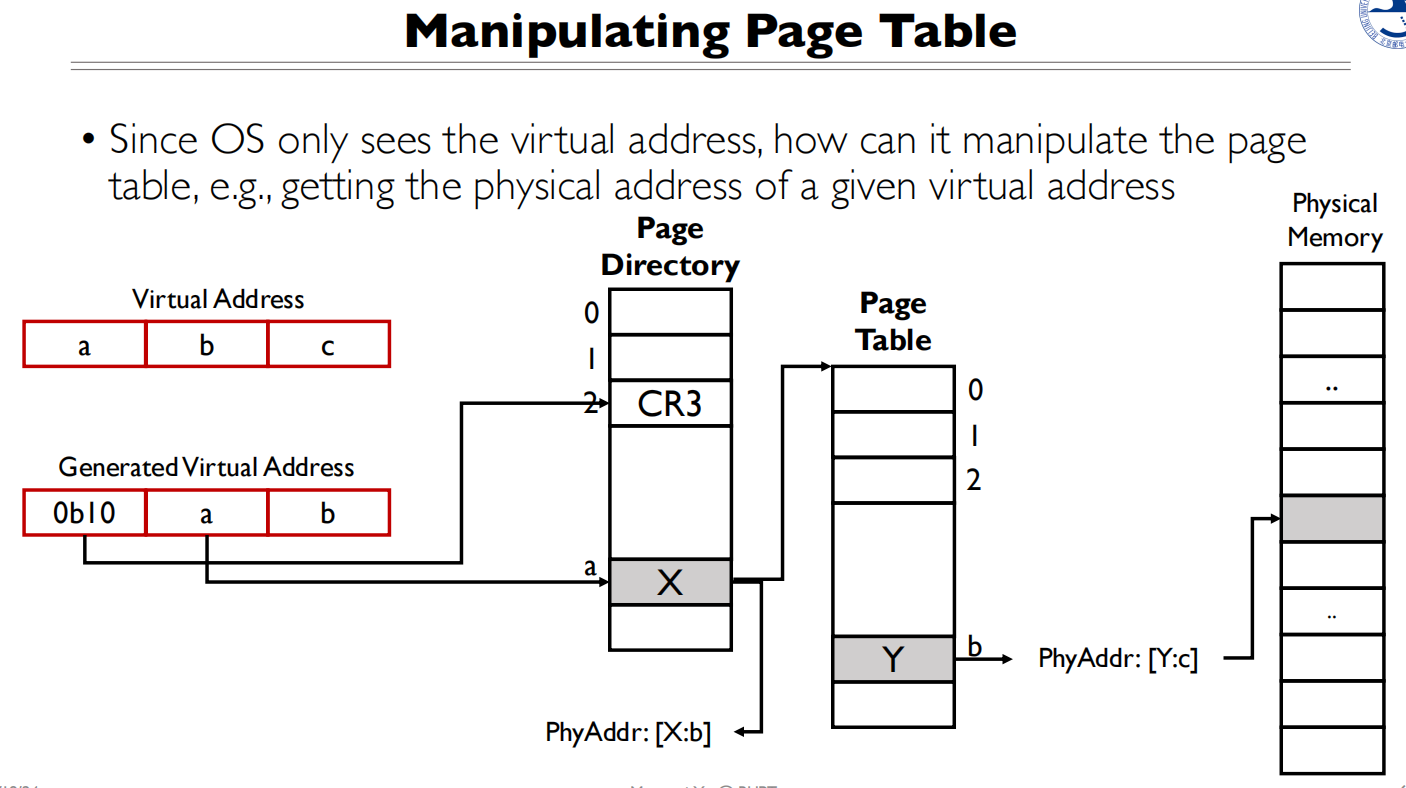 做一个自映射,即0b10会映射到CR3,再次映射到页目录,那么0b10ab拼起来取值,就能得到Y的物理地址
做一个自映射,即0b10会映射到CR3,再次映射到页目录,那么0b10ab拼起来取值,就能得到Y的物理地址
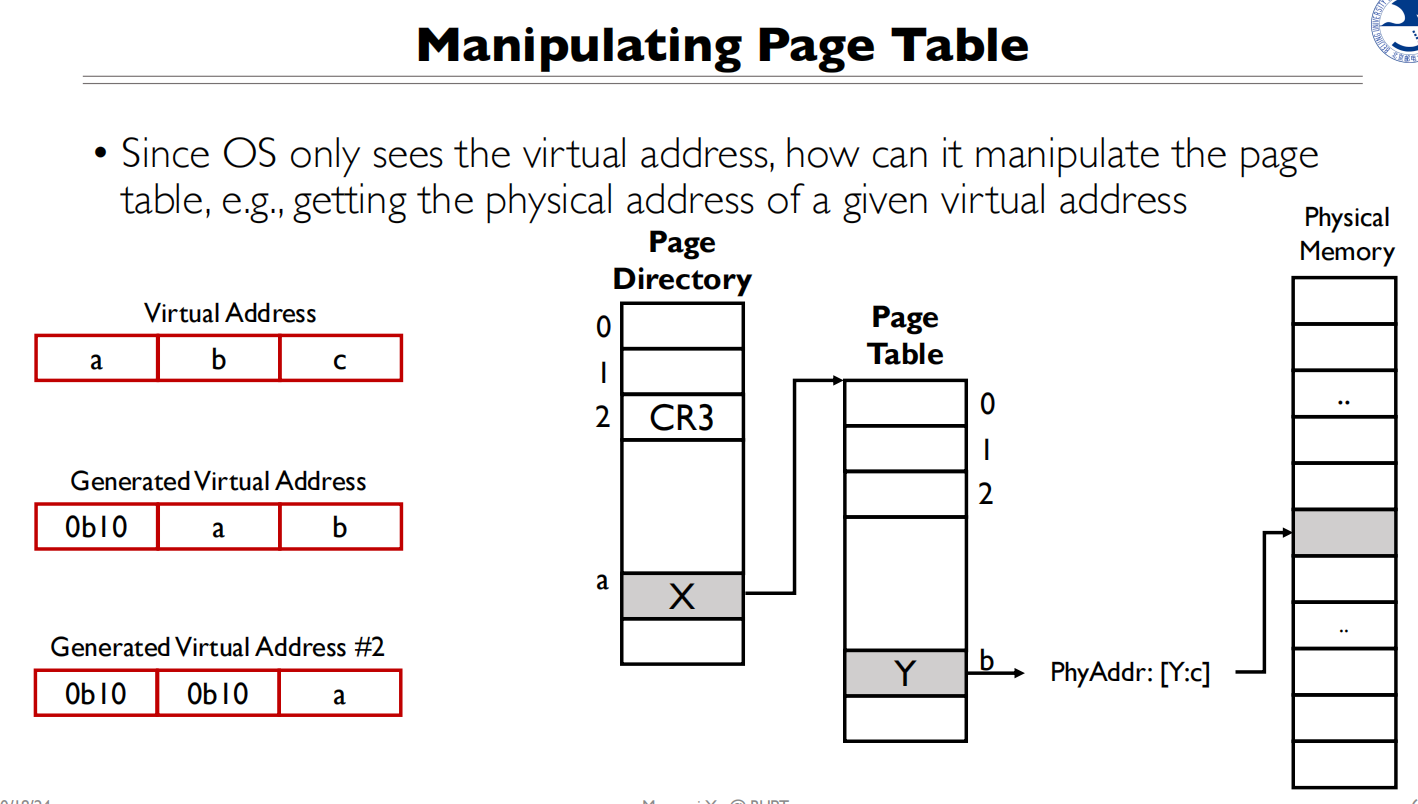 同理,如果想拿到X的物理地址,可以自映射两次,0b10 0b10 a 就能拿到X的地址
同理,如果想拿到X的物理地址,可以自映射两次,0b10 0b10 a 就能拿到X的地址
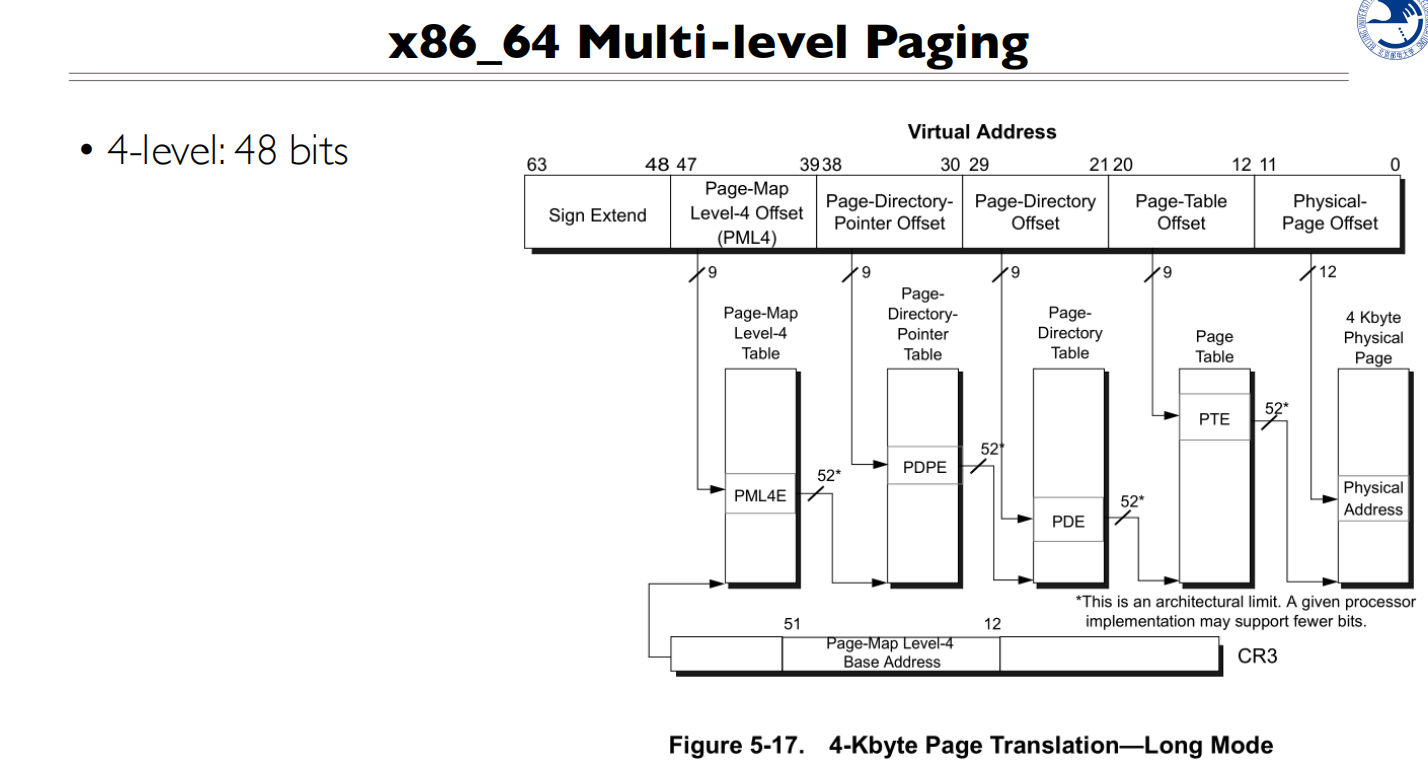 9 9 9 9
9 9 9 9
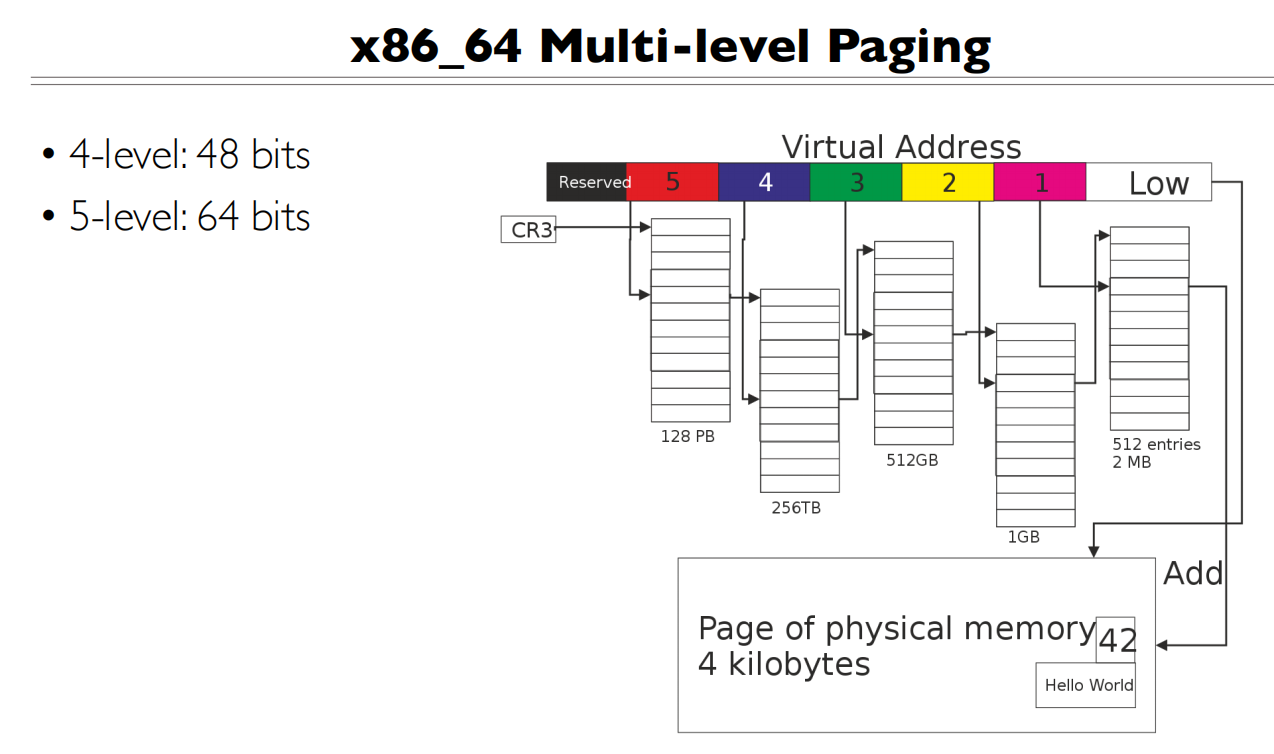
 多级页表最大的问题是访问太慢了
多级页表最大的问题是访问太慢了

COW
系统调用的fork()用到了
 COW的基本原理:
COW的基本原理:
- fork()时不立即复制内存内容
- 而是让父子进程共享同一块物理内存
- 将这些共享的页面都标记为”只读”
- 父子进程都只能读取这些页面,不能写入
COW的写入处理:
- 当任一进程尝试写入共享页面时,会触发缺页中断(page fault)
- 系统会捕获这个故障并进行处理:
- 为写入进程分配新的物理页面
- 复制原页面的内容到新页面
- 更新进程的页表,指向新的物理页面
- 新页面标记为可写
- 另一个进程继续使用原来的页面
COW的优势:
- 延迟复制操作,只在必要时才复制
- 共享只读页面,节省物理内存
- 特别适合fork()后立即执行exec()的情况,因为完全不需要复制
- 提高了系统性能和资源利用率
对于问题”fork()后立即执行exec()会复制多少页面?”:
- 理论上不需要复制任何页面,但还是要copy页表
- 因为exec()会直接替换进程的内存内容
- COW机制避免了不必要的复制操作
 页大小是,那么可以得到页内偏移Offset的大小是.
所以对于32bit系统,13用作Offset,剩余19bit 要用在页目录和页表中,就可以拆分成高位9bit 用于页目录,中位10bit用在页表
页大小是,那么可以得到页内偏移Offset的大小是.
所以对于32bit系统,13用作Offset,剩余19bit 要用在页目录和页表中,就可以拆分成高位9bit 用于页目录,中位10bit用在页表
| 页目录(9bit) | 页表(10bit) | Offset(13bit) |
|---|
所以页目录的大小为,页表的大小是
可以映射的总大小还是不变,
这种页面大小的设计在一些嵌入式系统中比较常见,因为它能提供更细粒度的内存管理。