并行、并发 Thread: a single execution sequence that represents a separately schedulable task.
Thread abstraction
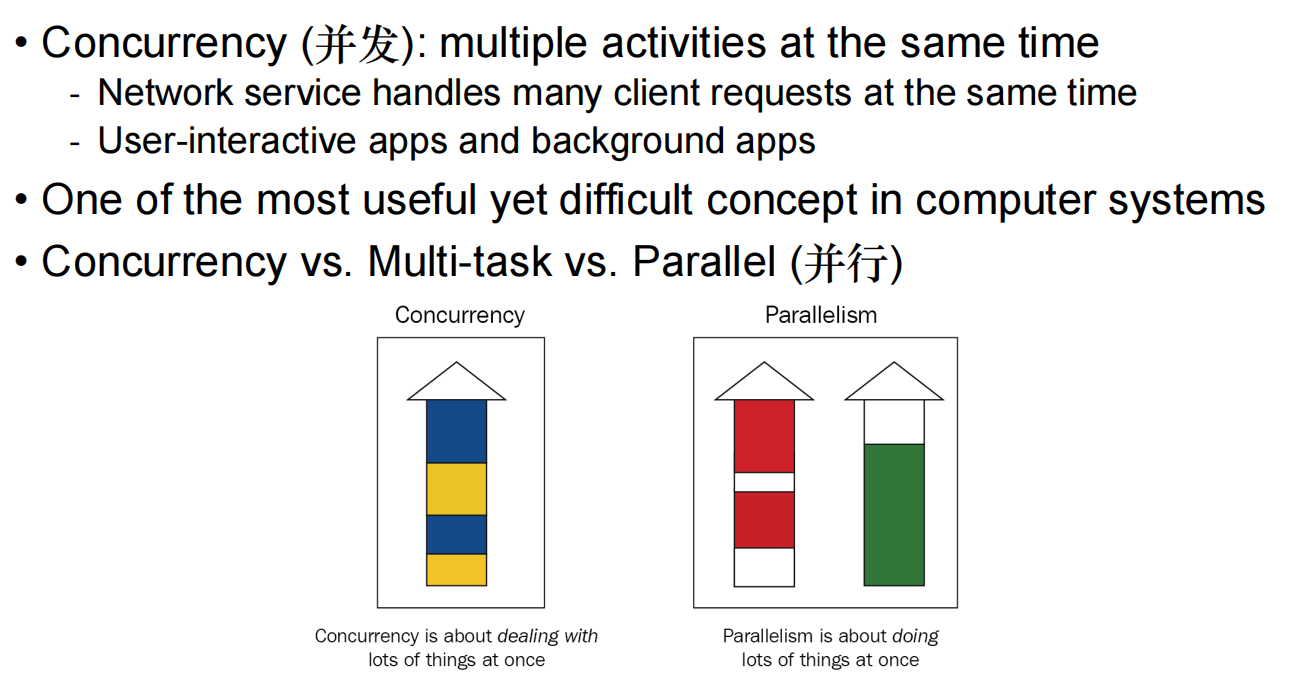
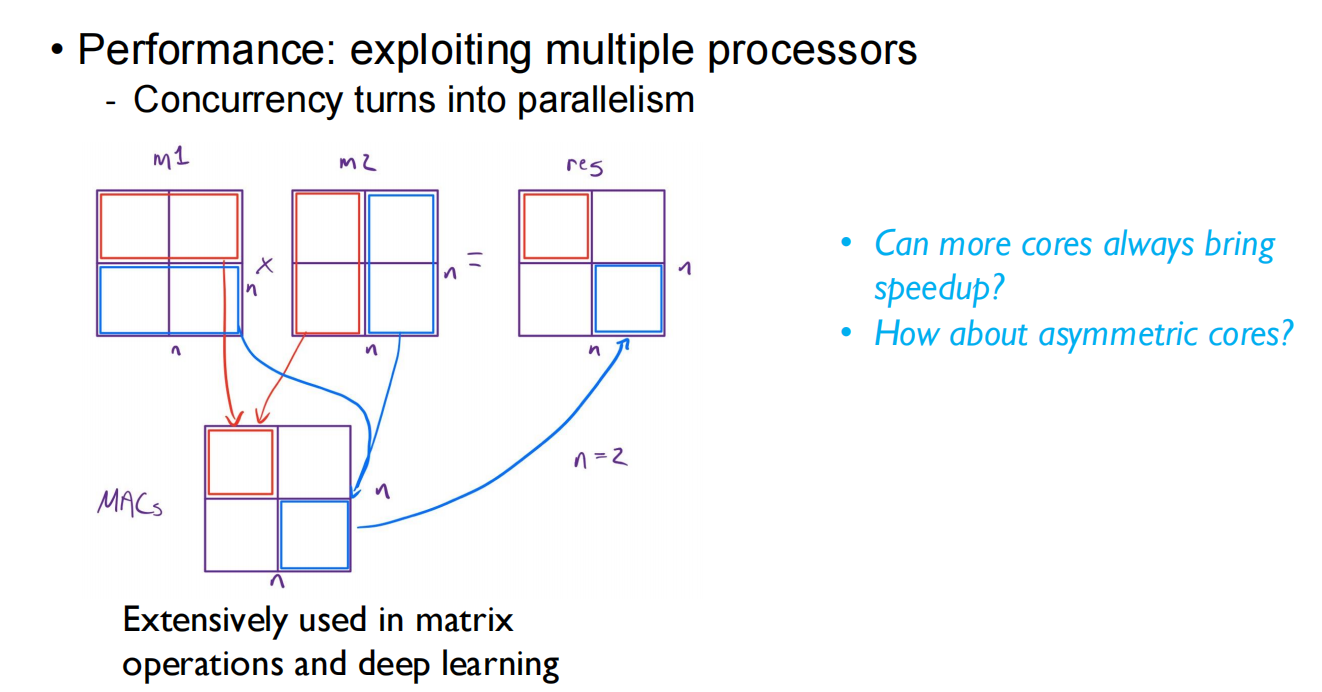 一般可以,但是会有其他方面的限制,比如说访存
一般可以,但是会有其他方面的限制,比如说访存
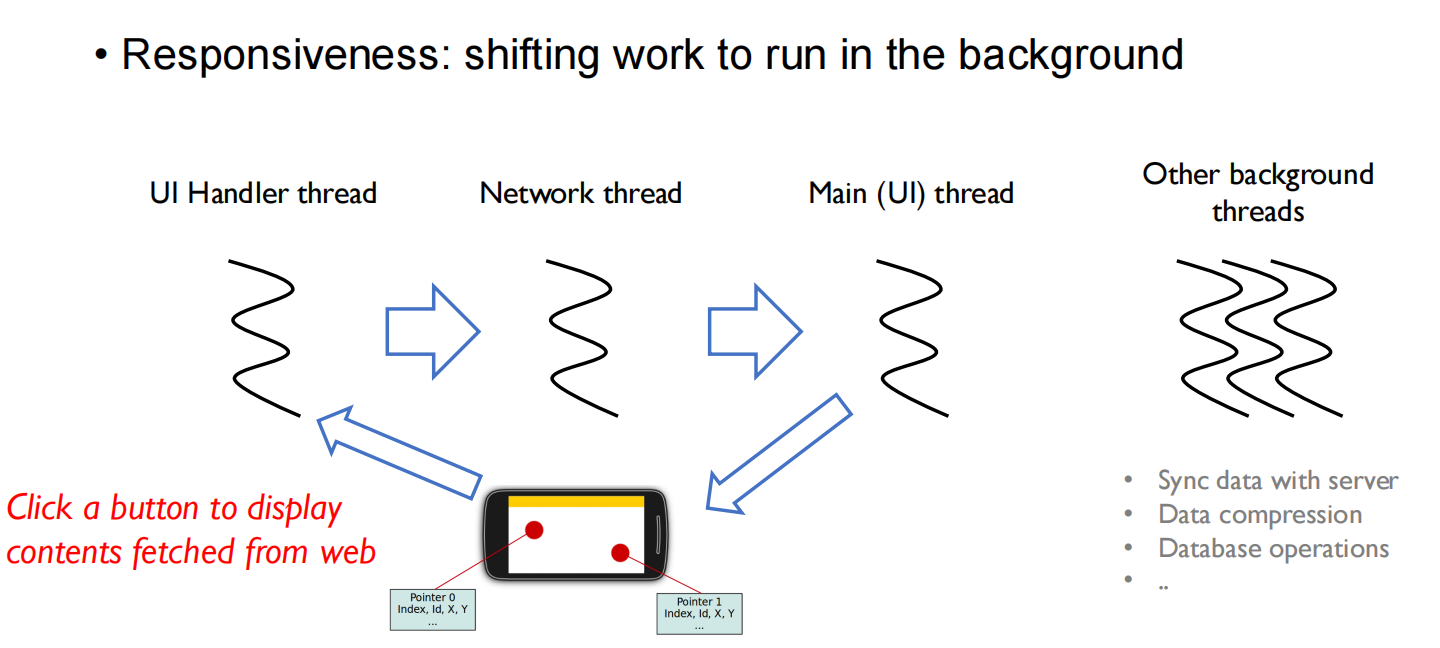
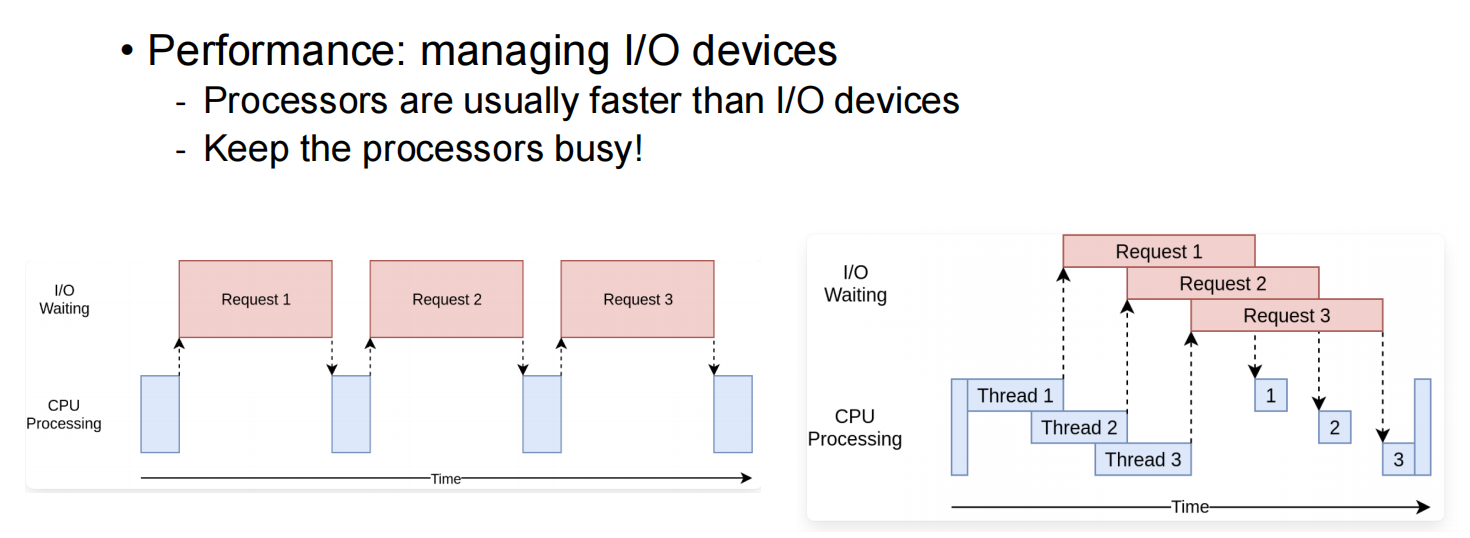 响应时间没变,但是提升了吞吐率(每秒跑多少个任务) related to CPU使用率
响应时间没变,但是提升了吞吐率(每秒跑多少个任务) related to CPU使用率
Thread: a single execution sequence that represents a separately schedulable task
一个线程是最小的被独立调度的单元
Important
The minimal scheduling unit in OS
允许被单独调度的执行序列
在单个线程中,执行的逻辑就是程序编写的逻辑,按顺序执行
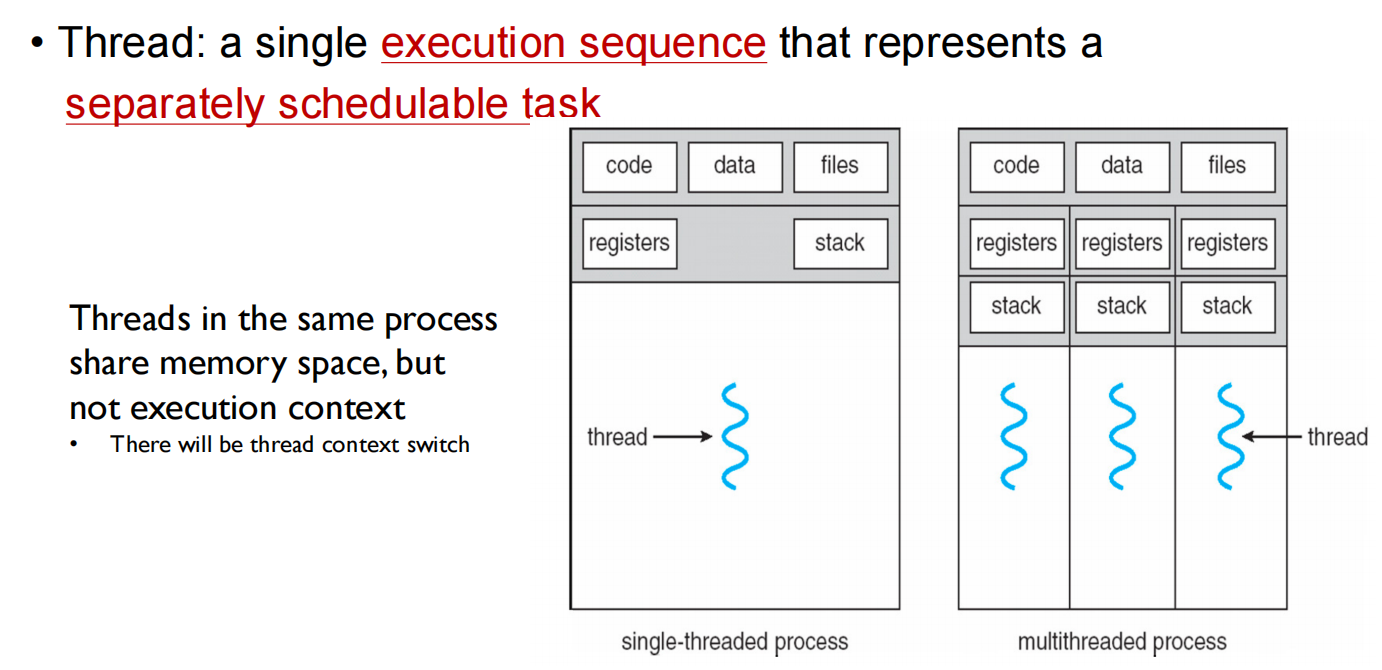 不共享执行的上下文
不共享执行的上下文
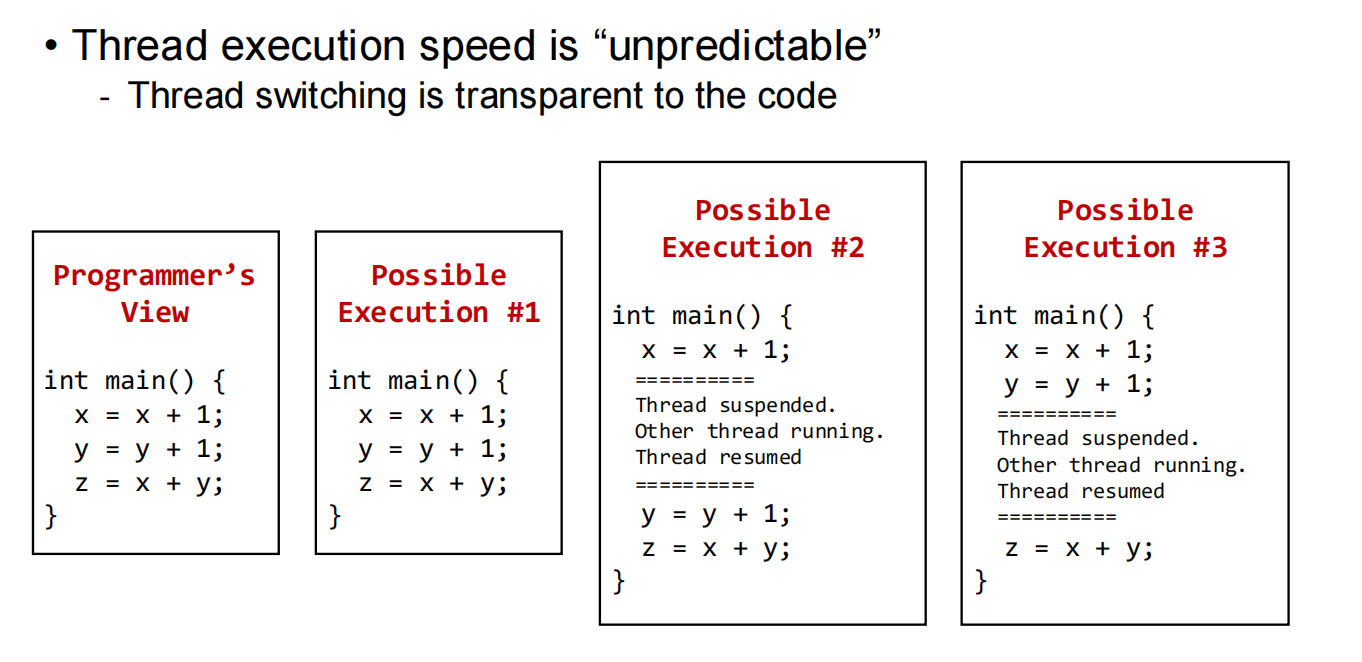 线程之间的执行顺序是不可预测的
线程之间的执行顺序是不可预测的
 两种可能的输出结果
两种可能的输出结果
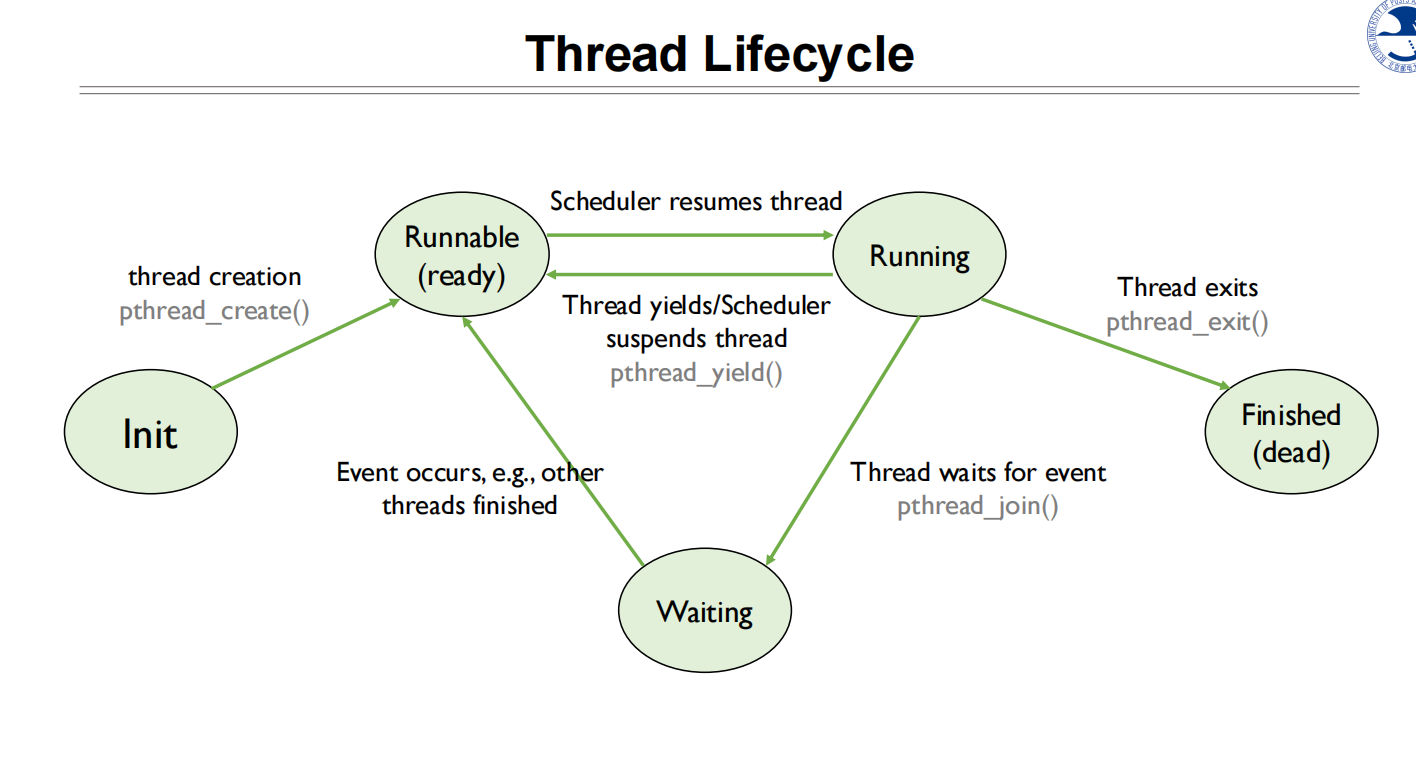
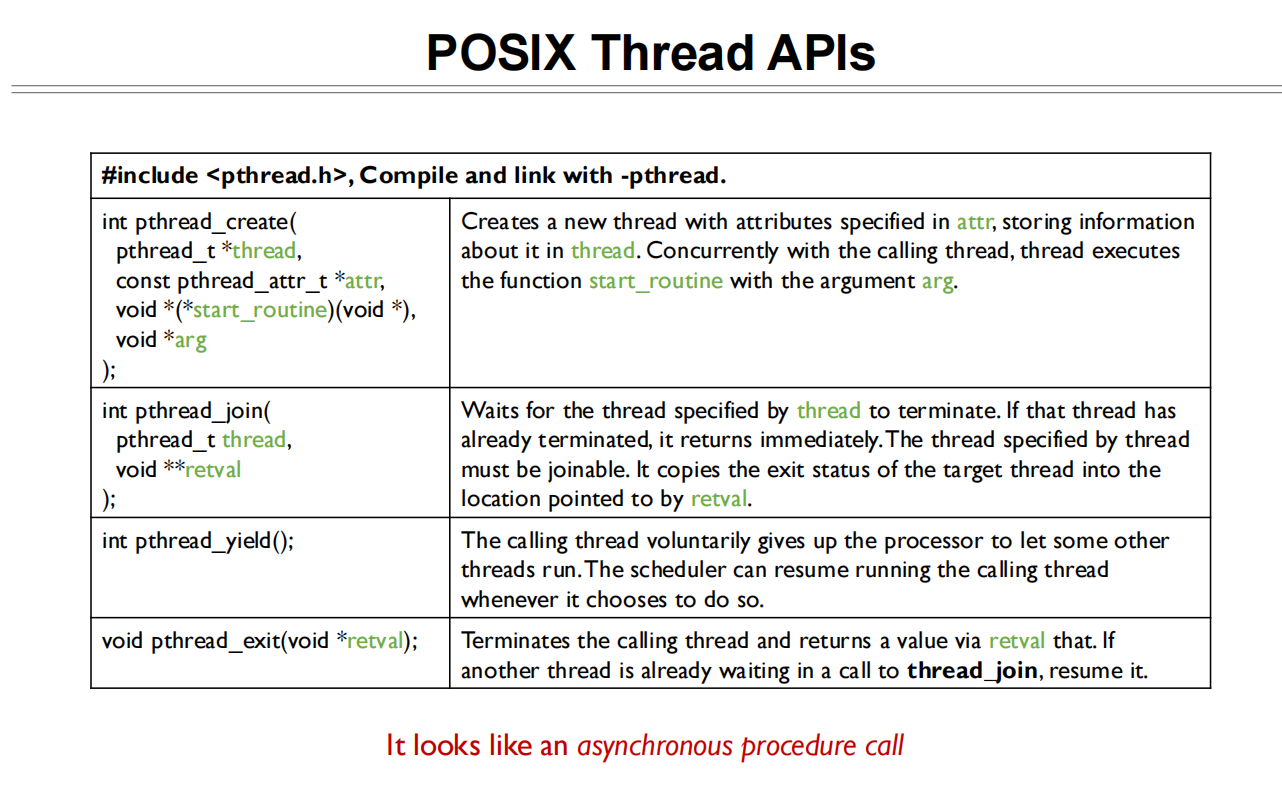
Thread implementation
TCB(Thread Control Block)
- Stack pointer: each thread needs their own stack
- Copy of processor registers
- Metadata
- Thread ID
- Scheduling priority
- Status
What’s different from PCB

 内核态的栈比较小,做精简的事情
内核态的栈比较小,做精简的事情
Shared State
- Code
- Global variables
- Heap variables
操作系统不会主动去隔离线程之间的数据,共享同一块地址空间
If thread A has a pointer to the stack location of thread B, A can access/modify the variables on the stack of thread B

Code 内核态线程实现
和easy_lab1有关
 栈是从上往下增长,
栈是从上往下增长,tcb->sp需要指向栈顶的位置
stub是要执行的函数
为什么要有一个stub,不能直接将func压栈呢
- 为了主动加一个
thread_exit(0),每次调用都能显式exit - 封装了用户函数的执行



thread_switch是精华
pushad保存当前所有通用寄存器的值到当前栈上,这样保存了旧线程的上下文信息oldTCB->sp=%esp存储当前线程的栈为oldTCB,这样旧线程下次恢复的时候能知道从哪里开始执行%esp=newTCB->sp将栈指针移到新线程popad弹出新栈的寄存器值return;执行 return 时,会从当前栈顶弹出返回地址,由于栈已经切换到新线程的栈,弹出的是新线程的返回地址,因此程序会跳转到新线程上次被中断的位置继续执行
为什么要关中断
- 因为线程切换过程中的栈和寄存器操作必须是原子的
- 如果中间发生中断,可能会破坏切换过程,导致系统崩溃


- When does switch (change of pc) actually happen?
- PC的切换实际发生在 thread_switch 函数的 return 指令执行时
- 因为 return 指令会从栈顶弹出返回地址到 PC
- 由于之前已经切换到了新线程的栈,所以会跳转到新线程的执行点
- What’s the goal of thread_dummySwitch?
- 为新创建的线程准备初始栈环境
- 在栈上设置返回地址(stub函数)
- 为 popad 指令预留空间
- 确保新线程第一次被调度时能够正确运行,与普通线程切换机制保持一致
- What’s the purpose of stub function and how it is correctly called?
- stub函数的目的:
- 包装用户线程函数的执行
- 确保线程函数执行完后能够正确退出
- 正确调用方式:
void stub(void (*func)(int), int arg) { (*func)(arg); // 执行用户函数 thread_exit(0); // 确保线程正确退出 } - 参数通过线程创建时压入栈中的方式传递
- Why we need to disable interrupts during thread_switch?
- 线程切换过程中涉及关键的栈和寄存器操作
- 这些操作必须是原子的,不能被中断打断
- 如果在切换过程中发生中断:
- 可能破坏栈的状态
- 可能导致寄存器值保存/恢复错误
- 可能引起系统崩溃
- 所以必须通过关中断来保证切换过程的原子性


多线程实现

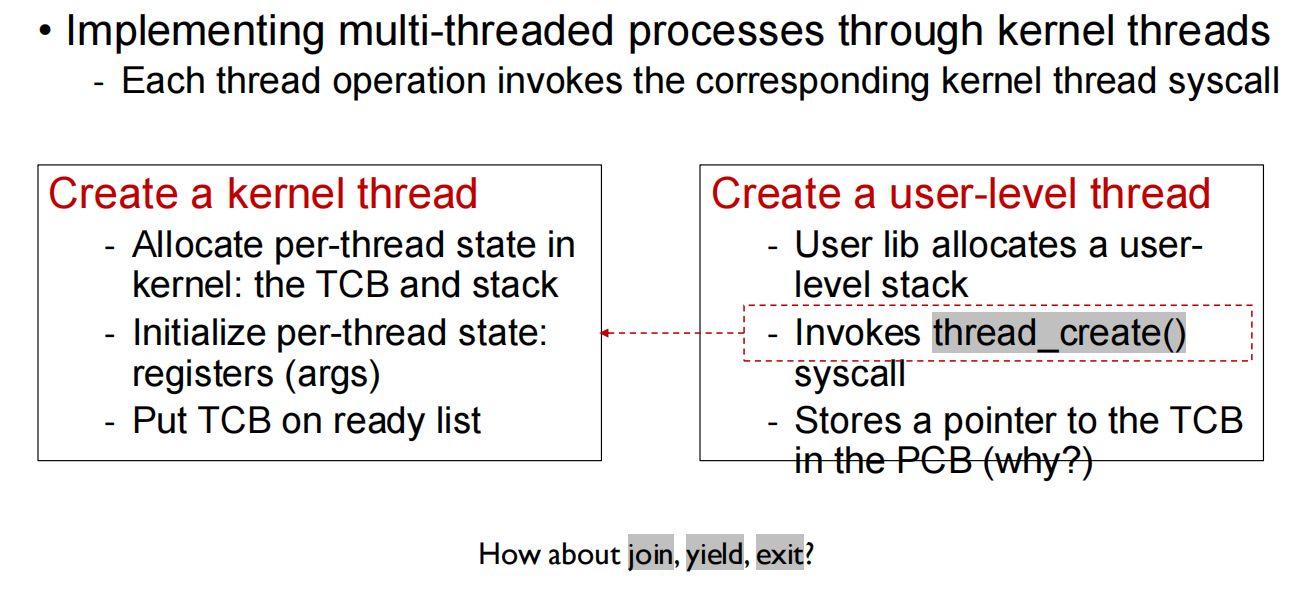
 用户级线程的实现方式和关键概念:
用户级线程的实现方式和关键概念:
- 用户级线程库的实现特点:
- 所有线程相关的数据结构都在用户空间维护:
- TCBs (线程控制块)
- 线程栈
- 就绪队列
- 完成队列
- 线程库负责线程调度
- 线程操作实际上就是普通的过程调用
- 实现用户级线程并发执行的两种方式:
- 抢占式(preemptive):
- 通过内核的定时器中断(upcall)实现
- 强制线程切换
- 协作式(cooperative):
- 线程主动让出 CPU(yield)
- 需要线程自己配合
- 如何改变程序的执行流:
- 通过修改:
- PC(程序计数器):使用 jmp 指令
- 栈指针(esp):直接修改 esp 寄存器 这样可以实现线程切换


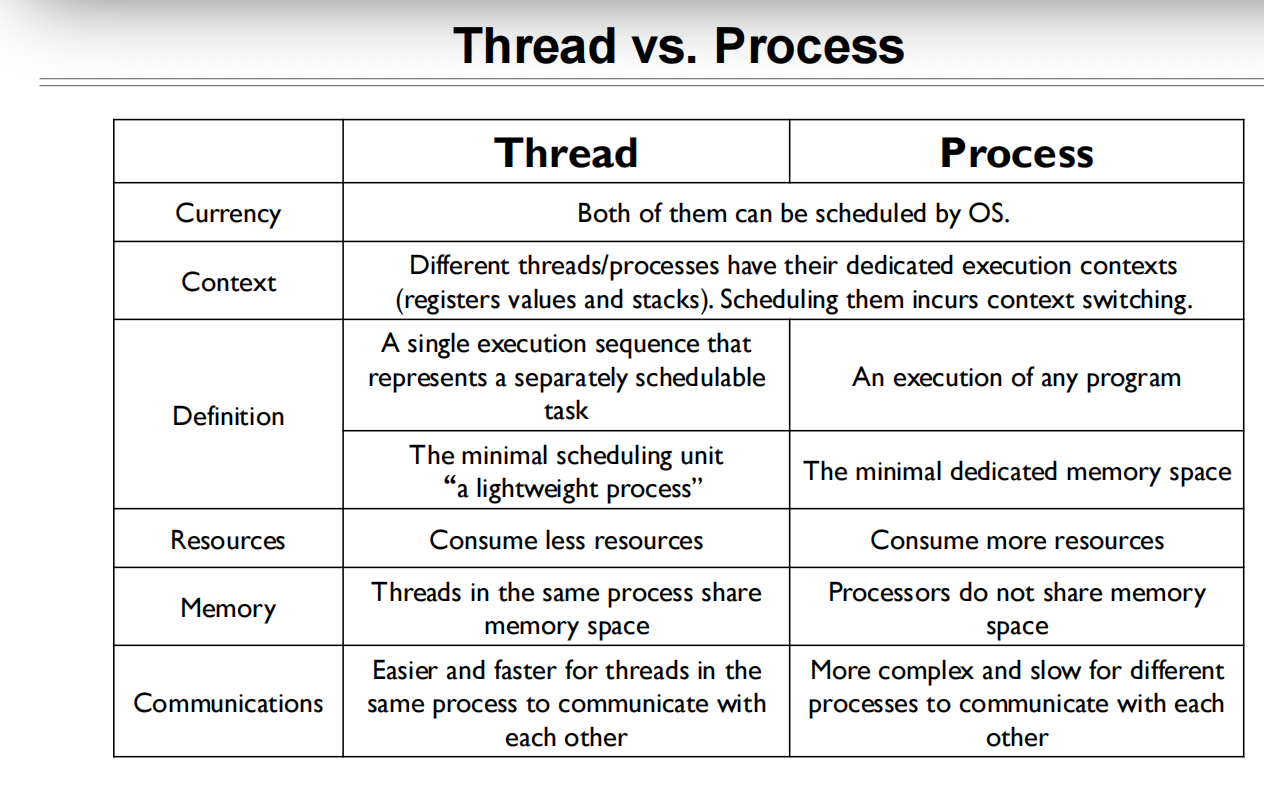
Thread VS Process
进程(Process)和线程(Thread)是操作系统中的两种基本并发执行单位。它们有许多相似之处,但也有重要的区别。下面从多个角度对进程和线程进行对比和说明。
1. 定义:
-
进程:进程是操作系统分配资源的基本单位。每个进程拥有自己独立的内存空间、文件描述符表、程序计数器、堆栈等。进程之间相互独立,切换进程时会发生上下文切换(Context Switch)。
-
线程:线程是 CPU 调度的基本单位。一个进程可以包含多个线程,同一进程中的线程共享进程的内存和资源,但每个线程有自己的栈、程序计数器和寄存器。线程通常被称为“轻量级进程”,因为创建和切换线程的开销比进程小。
2. 内存和资源分配:
-
进程:
- 每个进程有自己独立的地址空间(包括代码段、数据段、堆和栈)。
- 进程之间相互隔离,一个进程无法直接访问另一个进程的内存,除非通过进程间通信(IPC)。
- 每个进程有独立的资源(如文件描述符、全局变量等)。
-
线程:
- 线程是同一进程内的执行单位,线程之间共享进程的全部资源和内存空间。
- 线程共享代码段、数据段和堆内存,但每个线程有自己的栈和程序计数器。
- 线程之间的通信可以通过共享内存完成,因为它们在同一个地址空间中。
3. 创建和切换:
-
进程:
- 创建一个进程需要操作系统为其分配独立的内存空间,并创建相应的资源(如 PCB 等)。
- 进程切换的开销较大,因为切换时需要保存和恢复整个进程的上下文,包括内存地址空间、寄存器等。
- 进程通过
fork()、exec()等系统调用创建,常常伴随着资源的复制和分配。
-
线程:
- 线程的创建相对轻量,因为线程共享进程的资源,只需为其分配少量的独立资源(如栈、程序计数器等)。
- 线程切换的开销比进程切换小,因为不需要切换内存空间,只需切换 CPU 寄存器等上下文信息。
- 线程通过库函数(如
pthread_create())创建,且在同一个进程中可以快速切换。
4. 通信方式:
- 进程:
- 进程之间不能直接访问对方的内存空间,因此需要通过进程间通信(IPC)机制进行数据交换。常见的 IPC 方式包括管道(Pipe)、消息队列(Message Queue)、共享内存(Shared Memory)、信号(Signal)等。
- 线程:
- 线程之间由于共享同一地址空间,可以直接访问共享变量或内存,线程之间的通信非常高效。不需要复杂的通信机制,通常使用锁(Mutex)、信号量(Semaphore)或条件变量(Condition Variable)来确保同步和数据一致性。
5. 开销:
-
进程:
- 进程的创建、销毁和切换开销较大,因为需要分配独立的资源和上下文切换涉及更多的系统操作。
- 进程之间通信开销较大,因为它们不共享内存空间,必须使用 IPC 机制。
-
线程:
- 线程的创建、销毁和切换开销小,线程共享进程的资源,系统不需要为其分配独立的内存空间。
- 线程之间的通信开销小,可以直接共享数据。
6. 安全性:
-
进程:
- 由于进程之间互相隔离,一个进程的崩溃不会影响到其他进程。
- 进程的独立性使得它们更适合处理不同任务或保护数据的独立性(例如浏览器中的多个标签页作为不同进程运行,防止一个页面崩溃导致整个浏览器崩溃)。
-
线程:
- 线程之间共享内存,因此一个线程的崩溃可能会导致整个进程崩溃,特别是在多个线程操作共享数据时出现竞争条件或死锁问题。
- 由于线程共享进程内存,必须小心处理同步问题以避免数据不一致或内存冲突。
7. 并发性:
-
进程:
- 多个进程可以同时运行在多个 CPU 核心上,通过进程的并发实现任务并行。
- 进程并发较为独立,互不干扰,适用于复杂的应用程序和隔离性要求较高的任务。
-
线程:
- 同一进程的多个线程也可以并发运行在多个 CPU 核心上,线程的并发通常比进程更加高效。
- 线程非常适合用于需要处理密切相关任务的并发场景(例如 Web 服务器中处理多个用户请求)。
总结对比表:
| 属性 | 进程 (Process) | 线程 (Thread) |
|---|---|---|
| 内存空间 | 独立的地址空间 | 共享进程的地址空间 |
| 资源开销 | 创建和切换开销大 | 创建和切换开销小 |
| 通信方式 | 进程间通信(IPC)需要系统调用和较高开销 | 线程间通信直接共享数据,开销小 |
| 稳定性 | 独立性强,一个进程崩溃不会影响其他进程 | 线程共享内存,一个线程崩溃可能导致整个进程崩溃 |
| 创建方式 | 系统调用(如 fork()) | 库函数(如 pthread_create()) |
| 并发能力 | 独立运行,可并发执行 | 共享资源并发执行,适合并行处理任务 |
| 使用场景 | 用于需要资源隔离、独立运行的场景(如多个应用) | 用于需要轻量并发的场景(如 Web 服务器) |
典型使用场景:
-
进程:适合大型应用程序,如独立的服务器、数据库服务、浏览器的隔离标签页等。这些场景通常要求资源隔离和独立性,以避免进程间的干扰。
-
线程:适合并发密集型任务,如 Web 服务器中的多用户请求处理、游戏引擎中的多任务处理。线程提供了更高的并发性能,但需要注意同步和数据一致性问题。