User-kernel mode switch types
三大类,中断,异常和系统调用
- Exceptions
- When the processor encounters unexpected condition
- Illegal memory access, divide-by-zero
- Interrupts
- Asynchronous(异步) signal to the processor that some external event has occurred that may require its attention.
- Timer intterrupts, I/O requests such as mouse movement/clicks, etc
- System calls
- User processes request the kernel do some oeration on the user’s behalf.
- R/W files, create new processes, network connections, etc.
让我来解释异常和中断的区别,并分别举例:
主要区别:
- 来源不同:
- 异常是来自CPU内部的事件,由程序执行过程中的错误或特定指令引起
- 中断是来自CPU外部的事件,由外部设备或硬件产生
- 同步/异步:
- 异常是同步的,在指令执行时产生,具有确定性
- 中断是异步的,可以在任何指令执行期间发生,时间不确定
- 处理完成后的返回:
- 异常处理后通常重新执行产生异常的那条指令
- 中断处理后继续执行被中断时的下一条指令
具体例子:
异常的例子:
- 除零异常(Division by Zero):当程序试图将一个数除以0时,CPU会产生此异常
int a = 5;
int b = 0;
int c = a/b; // 这里会触发除零异常中断的例子:
- 键盘中断:当用户按下键盘按键时,键盘控制器向CPU发送中断信号,CPU暂停当前执行的程序,转而处理键盘输入,处理完成后返回继续执行原程序

- Inter-processor interrupt (IPI) - 会切换
- 处理器间中断是一种硬件中断
- 用于多处理器系统中处理器之间的通信
- 中断会触发从用户态切换到内核态
- Invalid opcode - 会切换
- 非法操作码会触发异常
- 操作系统需要处理这个异常
- 因此会从用户态切换到内核态
- Segmentation fault - 会切换
- 段错误是一种内存访问违例
- 需要操作系统进行处理
- 会触发从用户态到内核态的切换
- Network card interrupt - 会切换
- 网卡中断是硬件中断
- 需要操作系统的中断处理程序处理
- 会导致从用户态切换到内核态
- Divide-by-zero in Python/Java - 不会切换
- 这是高级语言层面的异常
- 由语言的运行时环境处理
- 不会触发操作系统级别的模式切换
- 它们通过语言自己的异常处理机制来处理
总结:前四种是系统级别的事件,会触发用户态到内核态的切换,而最后一种是应用程序级别的异常,由编程语言自己处理,不需要切换到内核态。
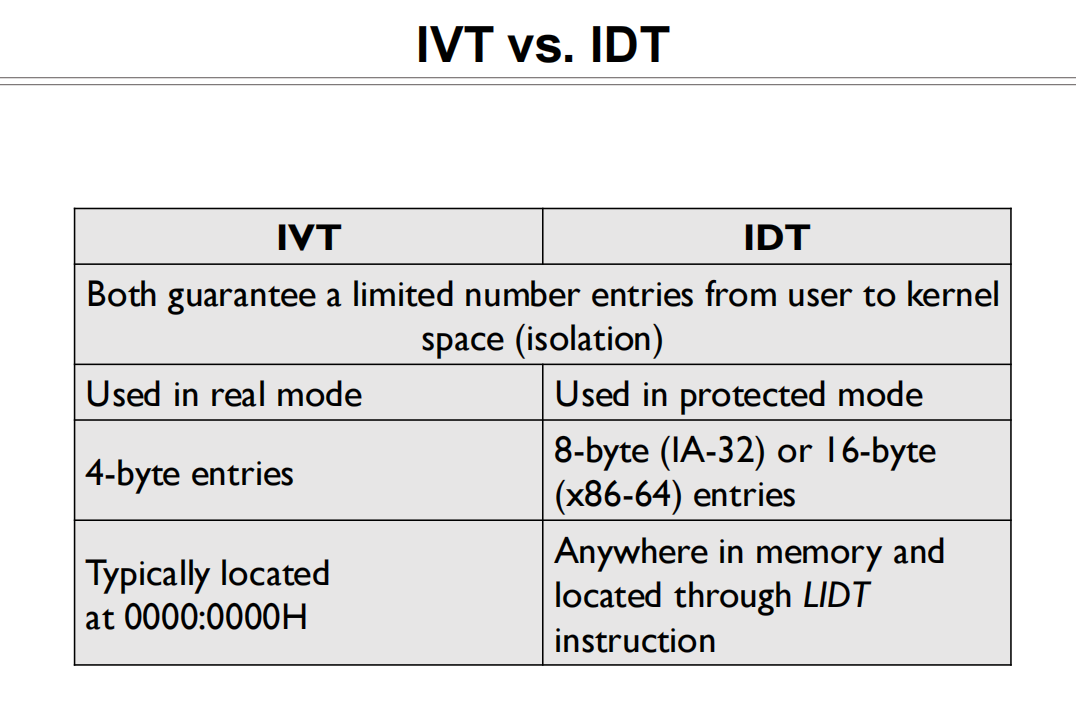
中断向量表
Stores the entries of different handlers for exceptions, interrupts, and traps in real mode.
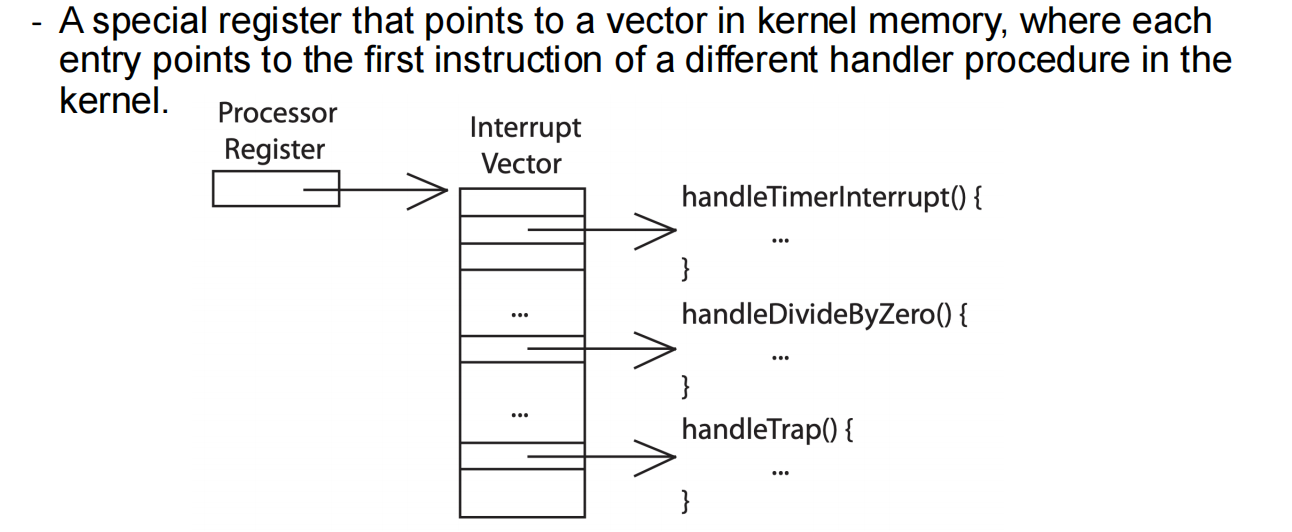
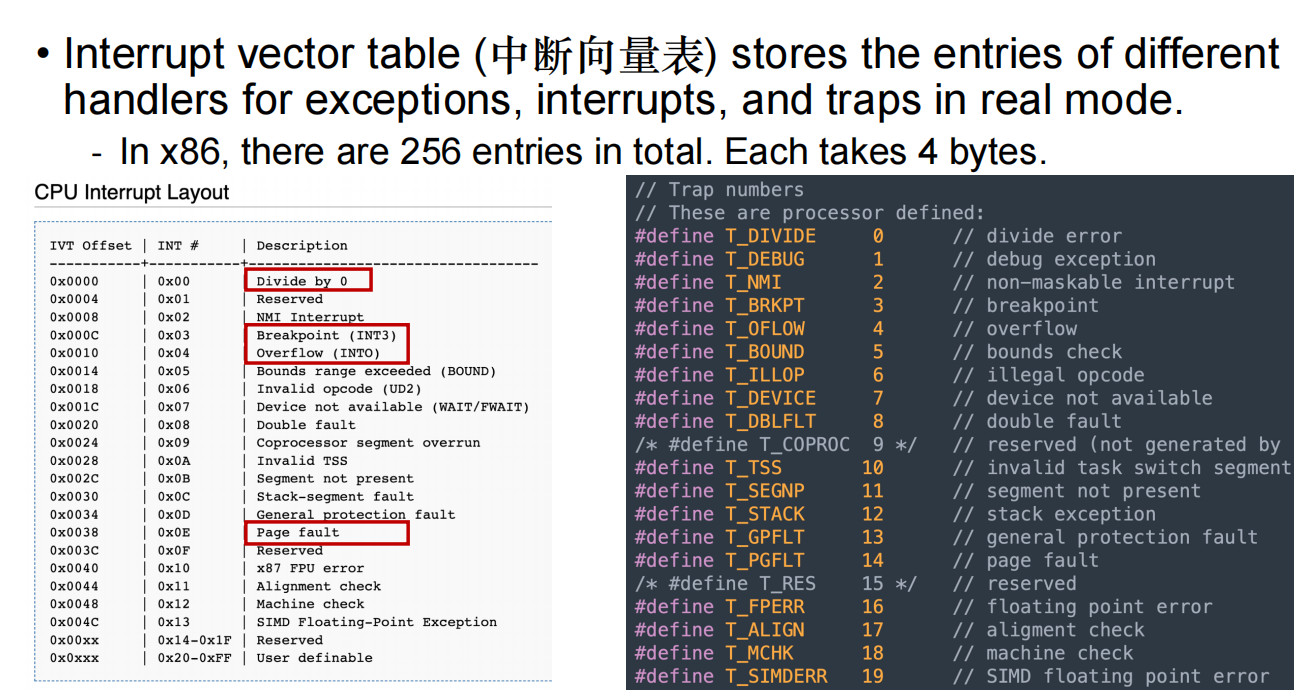
IDT可以看作是IVT的升级版
Interrupt Desctiptor Table(IDT,中断描述符表) tells the CPU where the Interrupt Service Routines (ISR,中断服务程序) are locatted
- Entries are called “Gates”, and there are 256 gates in total
- Each gate is 8-bytes long on 32-bit processors;or 16-bytes long on 64-bit processors
- Its location is kept in IDTR(IDT register), loaded with LIDT assembly instruction

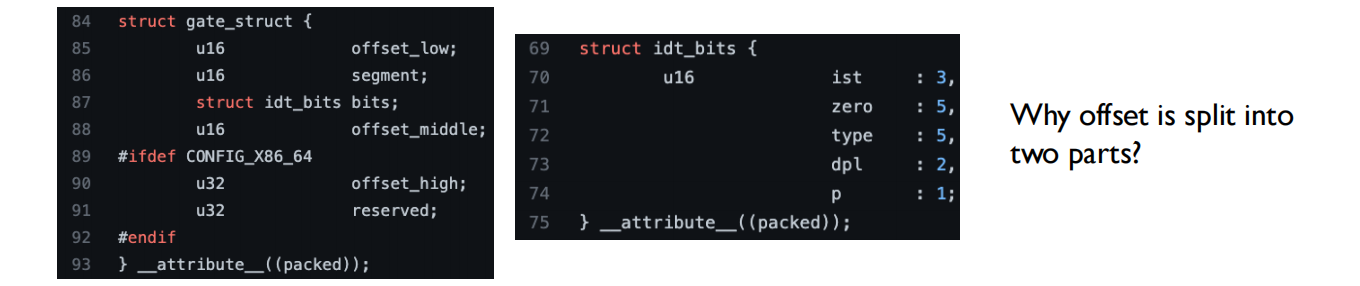
IDT (中断描述符表) 中的 offset 被分成两部分的原因主要有以下几个:
- 历史原因:
- 这个设计源于早期的x86架构(16位时代)
- 当时的地址总线宽度有限,将地址分段是常见做法
- 技术限制:
- 在早期的x86处理器中,寄存器大小有限
- 分成两部分可以在16位架构下处理更大的地址空间
- 实现方式:
31-16位:offset的高16位
15-0位:offset的低16位
- 优势:
- 更灵活的内存寻址
- 便于地址对齐和管理
- 可以更有效地利用CPU的寄存器
- 现代处理器:
- 虽然现代处理器已经是32位或64位
- 但为了保持向后兼容性,这种设计仍然保留
- 在64位系统中,offset甚至被分成更多部分
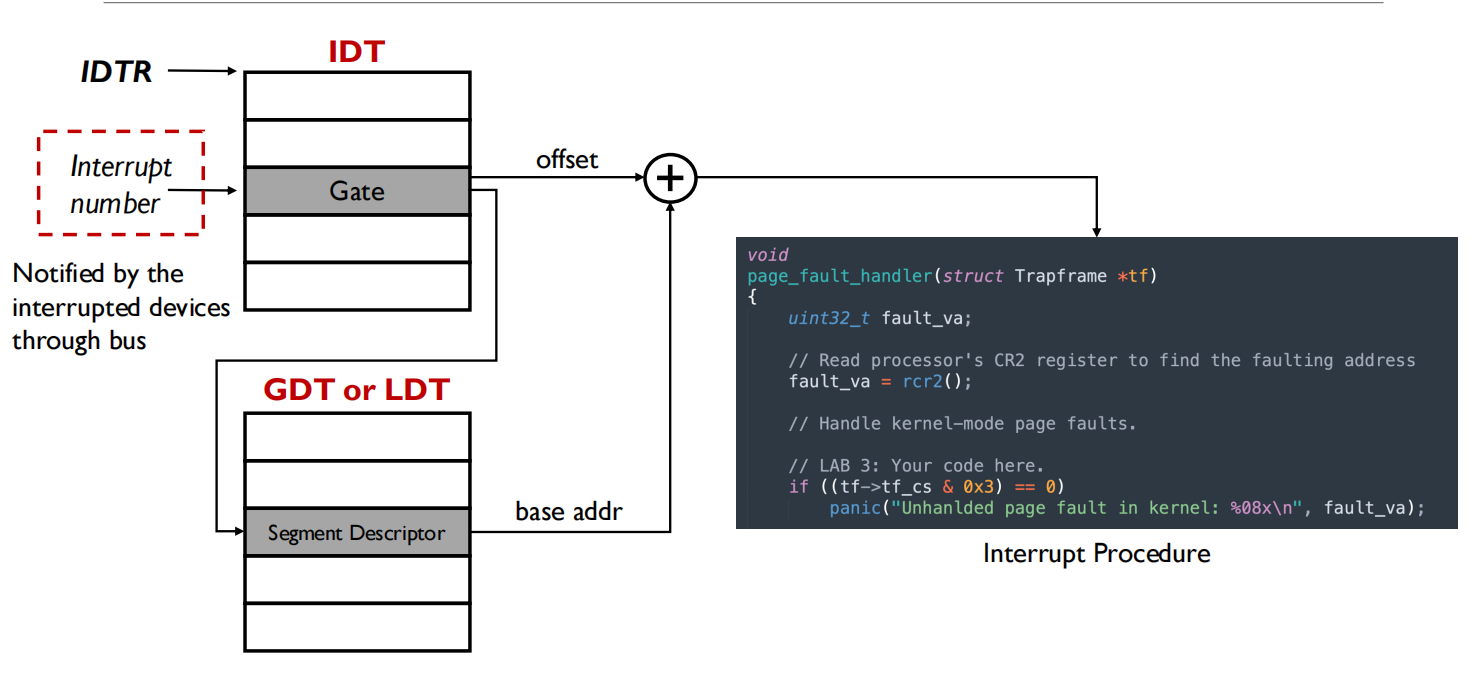
中断向量表(Interrupt Vector Table,简称IVT是计算机体系结构中用于处理中断和异常的一种数据结构。它包含了一组指针或地址,这些指针指向处理特定中断或异常的中断服务程序(Interrupt Service Routine,ISR)。当中断发生时,系统通过中断向量表快速定位并执行相应的ISR,从而响应中断事件。
中断向量表通常是一个数组或表格,每个表项对应一个特定的中断类型。每个表项包含了中断处理程序的地址信息,可能包括:
- 中断向量号(Interrupt Vector Number):唯一标识一个中断或异常的编号。
- 中断服务程序地址:指向ISR的指针或地址。
- 其他控制信息:如中断类型、优先级等(视具体架构而定)。
中断向量表的主要作用包括:
- 快速定位ISR:通过中断向量号,系统可以迅速找到对应的ISR地址,减少中断处理的延迟。
- 支持多种中断类型:不同的中断类型(如硬件中断、软件中断、异常等)有各自的处理程序,通过中断向量表进行区分和管理。
- 提高系统可扩展性:通过修改中断向量表,可以灵活地添加、移除或替换中断处理程序,增强系统的可维护性。
在x86架构中,中断向量表通常被称为中断描述符表(Interrupt Descriptor Table,IDT)。IDT包含了中断门(Interrupt Gate)、陷阱门(Trap Gate)等描述符,每个描述符对应一个中断或异常类型。IDT的主要特点包括:
- 描述符类型:包括中断门、陷阱门和任务门,决定了中断的处理方式。
- 段选择子(Segment Selector):指向代码段的选择子,用于切换到正确的代码段执行ISR。
- 偏移量(Offset):指向ISR入口的地址。
- 特权级别(Privilege Level):定义中断的权限级别,确保安全性。
在x86架构中,IDT的基地址和限制通过IDTR寄存器进行存储和访问。操作系统在初始化时会设置IDT,并为每个中断类型指定相应的ISR。
在ARM架构中,中断向量表的实现与x86有所不同。ARM使用中断向量基地址(Vector Base Address)来定位中断向量表。典型的ARM中断向量表包含固定位置的指令或跳转指令,用于处理不同类型的中断,如:
- 重置(Reset)
- 未定义指令(Undefined Instruction)
- 软件中断(Software Interrupt,SWI)
- 预取异常(Prefetch Abort)
- 数据异常(Data Abort)
- 中断请求(IRQ)
- 快速中断请求(FIQ)
ARM的中断向量表通常位于内存的固定地址(如0x00000000或0xFFFF0000),具体取决于系统配置。
在x86架构中,中断向量表被具体实现为中断描述符表(IDT)。IDT不仅包含中断向量号和ISR地址,还包含了描述符类型、段选择子和特权级别等信息。IDT的使用使得中断处理更加灵活和安全,支持多种中断类型和不同的权限控制。
在现代操作系统中,中断向量表的管理通常由内核负责。操作系统在启动时会初始化中断向量表,并为每个中断类型注册相应的ISR。内核还提供机制来处理动态中断(如设备驱动程序注册新的中断处理程序)和静态中断(如处理CPU异常)。
虚拟化环境中,中断向量表的管理更加复杂。虚拟机管理器(Hypervisor)需要管理物理和虚拟中断向量表,以确保虚拟机的中断处理与物理机的中断处理隔离开来。
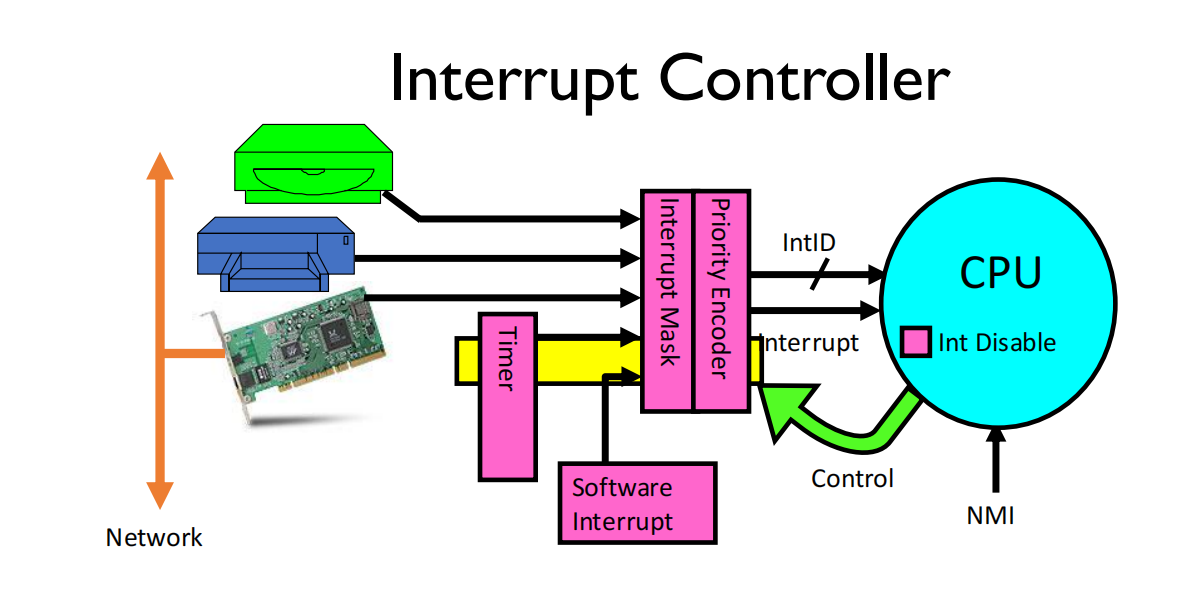
Interrupt Masking中断屏蔽
Disable interrupts and enable interrupts are two privileged instructions
- Maskable interrupts(可屏蔽中断):all software interrupts, all system calls, and partial hardware exceptions 所有软件中断,系统调用和部分软件异常
- Non-maskable interrupts (NMI, 不可屏蔽中断):partial hardware exceptions
- Specified by eflags registers(用eflags 这个寄存器标注中断屏蔽状态)
Interrupt Stack
Interrupt stack (中断栈) is a special stack in kernel memory that saves the interrupt process status.
Question
Why not directly use the user-space stack?
使用独立的中断栈(内核栈)而不是用户栈有几个重要原因:
- 安全性:
用户栈可能被恶意程序修改或破坏
用户栈可能已满或损坏
内核栈是受保护的,只能被内核访问
避免用户程序干扰中断处理过程
- 可靠性:
中断发生时,用户栈的状态是不可预知的
内核栈总是处于已知的良好状态
确保中断处理程序有可靠的栈空间使用
- 隔离性:
用户空间和内核空间需要严格分离
每个进程有自己的内核栈
避免中断处理影响用户程序的栈空间
- 性能考虑:
内核栈大小是固定的,便于管理
避免检查用户栈的有效性
减少地址空间切换的开销
- 并发处理:
- 支持嵌套中断
- 多个中断可以共享同一个内核栈
- 更容易进行中断优先级管理
这些原因使得使用独立的中断栈成为操作系统设计中的一个重要选择。
Question
How many interrupt stacks in kernel?
Things never to do in an OS:
- Swap out the page swapping code (trible-fault here we come) … 做page swapping 的代码在磁盘中,需要调用的时候又需要调用page swapping 的代码,这样就无终止递归了 Make it easier to switch to a new process inside an interrupt or system call handler.

Kernel to User Mode Switch
- New process
- Resume after an interrupt/exception/syscall
- Switch to a difference process
- After a timer interrupt
- User-level upcall
Upcalls
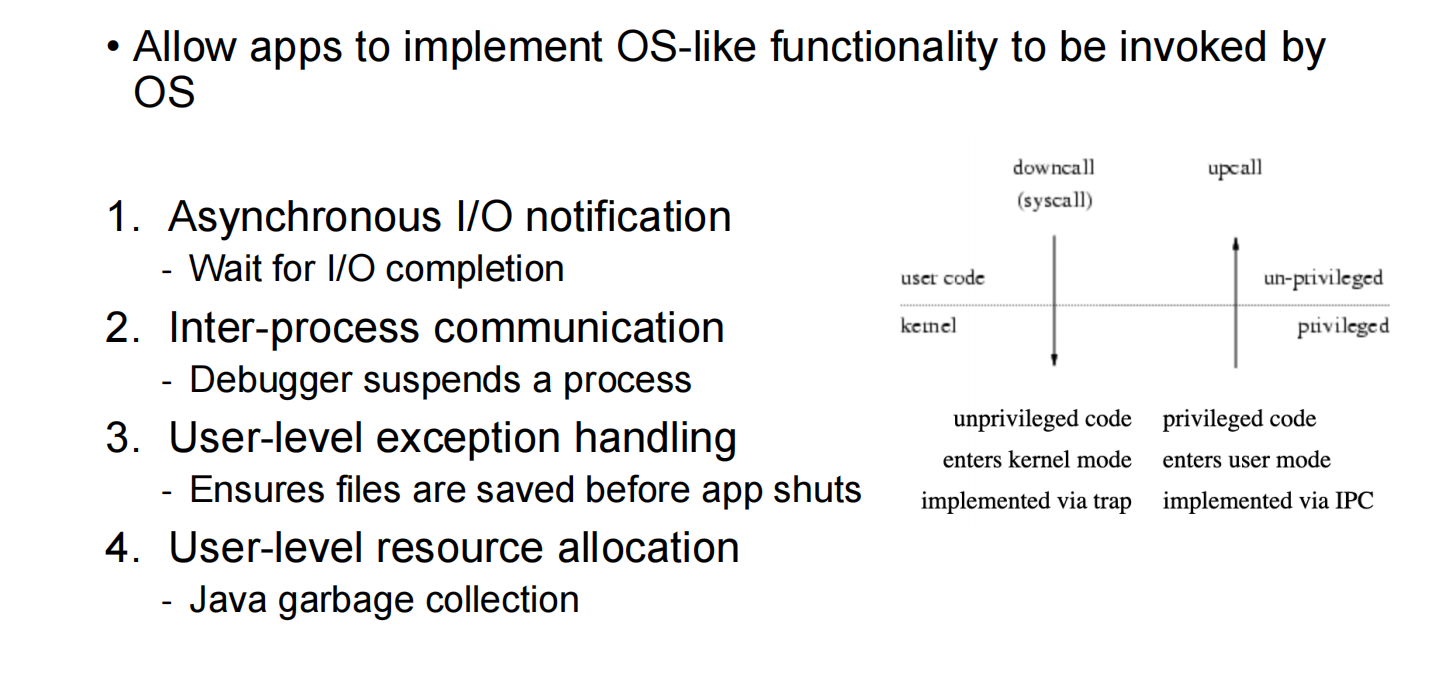
An x86 example of mode transfer
x86 Background
 这里需要记忆一下寄存器分别存的是什么,related to lab1
这里需要记忆一下寄存器分别存的是什么,related to lab1
cs和eip指向的是下一条指令
为什么是2^20:
eflags保存处理器的某些状态,比如说中断是开着还是关着的
Question
CPL is stored as the 2 lower-bits of cs register, Why is it possible(2 bits wasted)?
CS 寄存器的最低两位实际上不用于段寻址,在段寻址中,内存地址必须是4字节对齐的,这就意味着最低两位总是0
在x86架构中,代码段必须按照4字节对齐,因此地址的最低两位在寻址的时候不会被使用,所以就能用空闲的两个位去存储CPL
效率考虑:
- 将 CPL 存储在 CS 寄存器中避免了额外的寄存器开销
- CPU 在检查特权级时可以直接读取 CS 寄存器
- 不需要额外的内存访问或寄存器切换
设计优势:
- 每次代码段切换时自动携带了特权级信息
- 简化了特权级检查的实现
- 提高了系统的执行效率
所以这两个位并没有被浪费,而是被巧妙地重用来存储 CPL,这是一个非常精妙的设计。
 只有少部分指令可以改变
只有少部分指令可以改变cs寄存器,重点记忆INT, IRET
INT: 系统调用,从用户态陷入到内核态的指令
IRET:将程序从异常/中断处理程序带回程序中,从内核态回到用户态
下面是一个重点的🌰
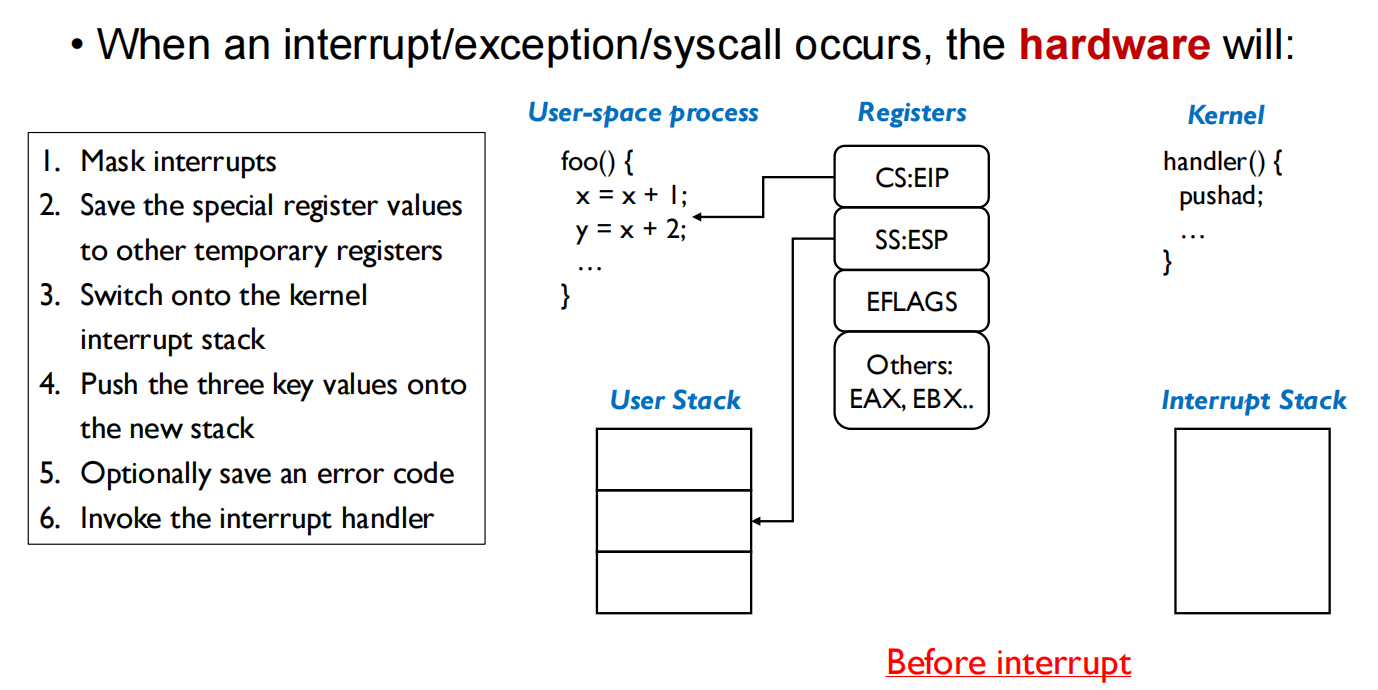
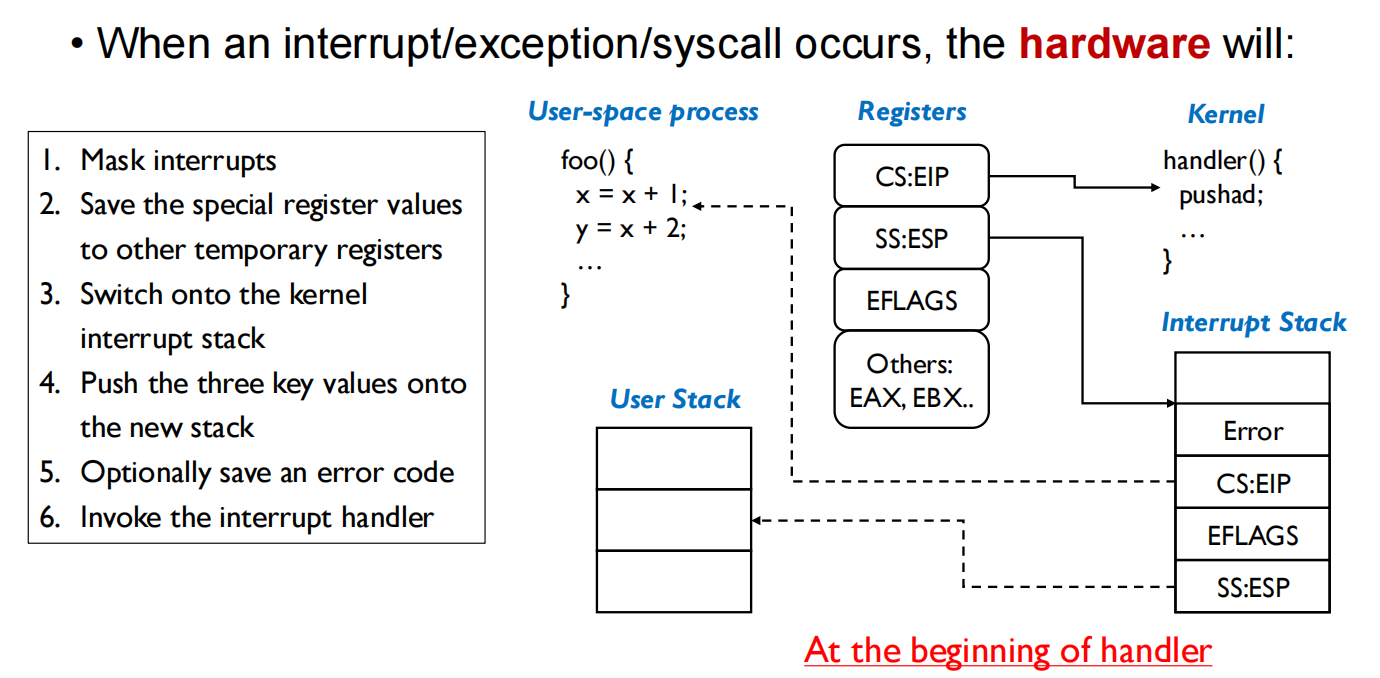

步骤2-4不能调换,因为交换a和b,需要一个中间c作为临时存储的地方
用户态和内核态在第6步切换
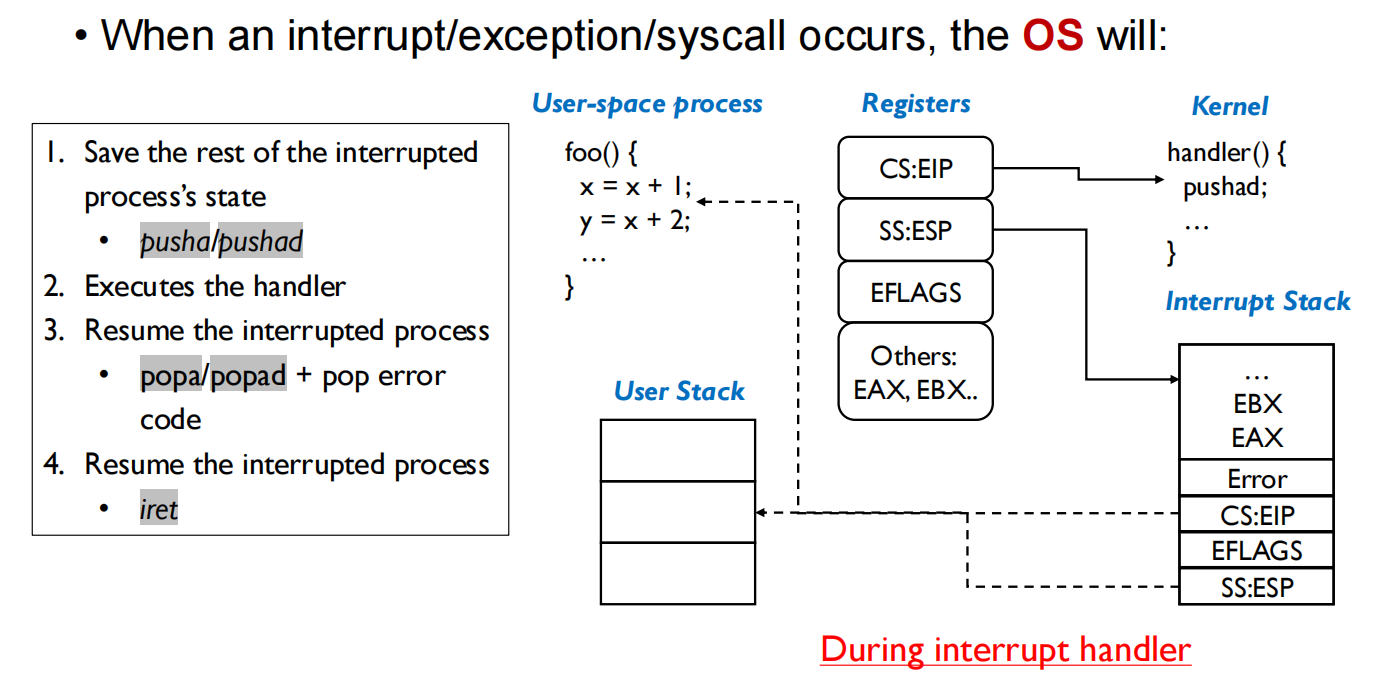 iret把程序计数器和栈指针重新指回用户态的程序和用户栈中,只需要将中断栈的值POP到对应的寄存器中
iret把程序计数器和栈指针重新指回用户态的程序和用户栈中,只需要将中断栈的值POP到对应的寄存器中
内核态到用户态在第4步切换,本质上是对 CS寄存器的更改
IRET是特权指令,可以切换权限
Question
Why OS does not track the “heap pointer” as for stack?
堆是用户态的行为,OS完全不关心
Summary
