大纲如下
基础知识
- Bootloader
- context switch
- 异常,中断,系统调用
- 线程
内存
- address translation
- TLB and cache
- demand paging
并发
- scheduling
- lcok and conditional variables
- RW lock
磁盘,文件系统
- fs design
- reliable fs
Virtual machine
重点
- 上下文切换部分的那个例子An x86 example of mode transfer
- 系统调用的fork()
- 线程的实现内核态线程实现
- 分页的地址翻译过程05 Address Translation
- TLB&Cache 06 TLB&Cache
- 需求分页,时钟算法
例题

- Cache Tag:21 bits
- Cache Index:5 bits
- Byte Select:6 bits
b:他们的Cache Index 部分相同,即第22位到第27位相同的时候会冲突
让我逐步解释这个缓存地址冲突的等式 |x/64-y/64|%32==0:
- 为什么用64做除数:
- 因为题目说明block大小是64 bytes
- x/64 和 y/64 实际上是在计算这些地址属于哪个块
- 为什么做差的绝对值:
- |x/64-y/64| 计算两个地址所在块的距离
- 为什么对32取模:
- 缓存有128个数据块空间,是4路组相连
- 所以每一路有128/4 = 32组
- %32 就是在计算这个距离映射到哪一组
- 为什么等于0:
- 如果两个地址映射到同一组,它们的块号之差必须是32的整数倍
- %32==0 就表示这个差值是32的整数倍
 a.线程被调度
b.等待某个锁、等待I/O完成、pthread_join()
c.获得了锁、收到了信号
a.线程被调度
b.等待某个锁、等待I/O完成、pthread_join()
c.获得了锁、收到了信号
 FIFO:6次,0,1,2,3和第一次访问4以及最后访问0
LRU:6次
FIFO:6次,0,1,2,3和第一次访问4以及最后访问0
LRU:6次
 因为CPU一个核内有TLB和L1cache等缓存信息,将同一个线程调度到同一个核上,避免了反复刷新缓存信息,提升线程的TLB和Cache的命中率。
因为CPU一个核内有TLB和L1cache等缓存信息,将同一个线程调度到同一个核上,避免了反复刷新缓存信息,提升线程的TLB和Cache的命中率。
 平均延迟的时间:60000(ms/min)/10000RPM/2=3ms
平均延迟的时间:60000(ms/min)/10000RPM/2=3ms
读取一个扇区的时间:
完全随机读取的时间:3+3+0.128 = 6.128ms
读取速率:6KB/6.128ms
 5. 异常、中断、系统调用
6. +一个进程切换
7. a.异常、中断、系统调用、 b.会发生异常
5. 异常、中断、系统调用
6. +一个进程切换
7. a.异常、中断、系统调用、 b.会发生异常
 a. popf指令阻止透明虚拟化的原因:
a. popf指令阻止透明虚拟化的原因:
- 行为不一致性:同一条popf指令在特权模式和非特权模式下表现不同(特权模式下可以修改所有标志位,非特权模式下只能修改ALU标志位)
- 语义差异:客户操作系统认为自己运行在特权模式下,期望popf能修改所有标志位,但实际上它运行在用户模式下,只能修改ALU标志位
- 行为无法模拟:虚拟机监视器(VMM)很难准确模拟这种特权级别相关的指令行为差异
b. 修改x86硬件的解决方案:
- 添加虚拟化扩展指令集,允许客户操作系统的特权指令被VMM捕获和模拟
- 引入新的处理器模式,专门用于虚拟机监视器运行
- 为popf等问题指令添加专门的虚拟化支持,使其在虚拟机环境中能够产生一致的行为
- 增加硬件级别的支持,允许VMM更细粒度地控制guest OS对处理器标志位的访问
这些问题最终在2006年后的x86处理器中通过添加硬件虚拟化支持(如Intel VT-x和AMD-V)得到了解决。

让我依次回答这三个问题:
- 在没有trap指令的情况下实现系统调用: 可以用异常来代替trap,具体实现方式为:
- 故意触发一个可预测的异常(比如除零异常)
- 在异常处理程序中检查是否是系统调用请求
- 如果是系统调用请求,则执行相应的系统服务
- 如果是真实的异常,则执行正常的异常处理
这种方案可行,但效率较低,因为异常处理的开销比trap指令大。
- 在没有中断的情况下实现I/O处理: 不能完全用异常或trap来替代中断,原因是:
- 中断是异步的,由外部设备触发
- 异常和trap是同步的,由程序执行触发
- 如果没有中断,系统只能通过轮询(polling)方式检查I/O设备状态
- 这会导致CPU资源浪费,系统响应速度降低
- 对于时钟这样的设备,无法及时获知时间变化
- CPU接收到中断后的处理步骤:
- 保存当前程序的执行状态(PC、寄存器等)
- 切换到内核模式
- 保存额外的处理器状态(如标志寄存器)
- 确定中断源,获取中断向量
- 跳转到对应的中断处理程序
- 执行中断处理程序
- 恢复保存的处理器状态
- 通过中断返回指令(如iret)返回到用户程序
- 继续执行被中断的程序
 会导致资源用尽报错
会导致资源用尽报错
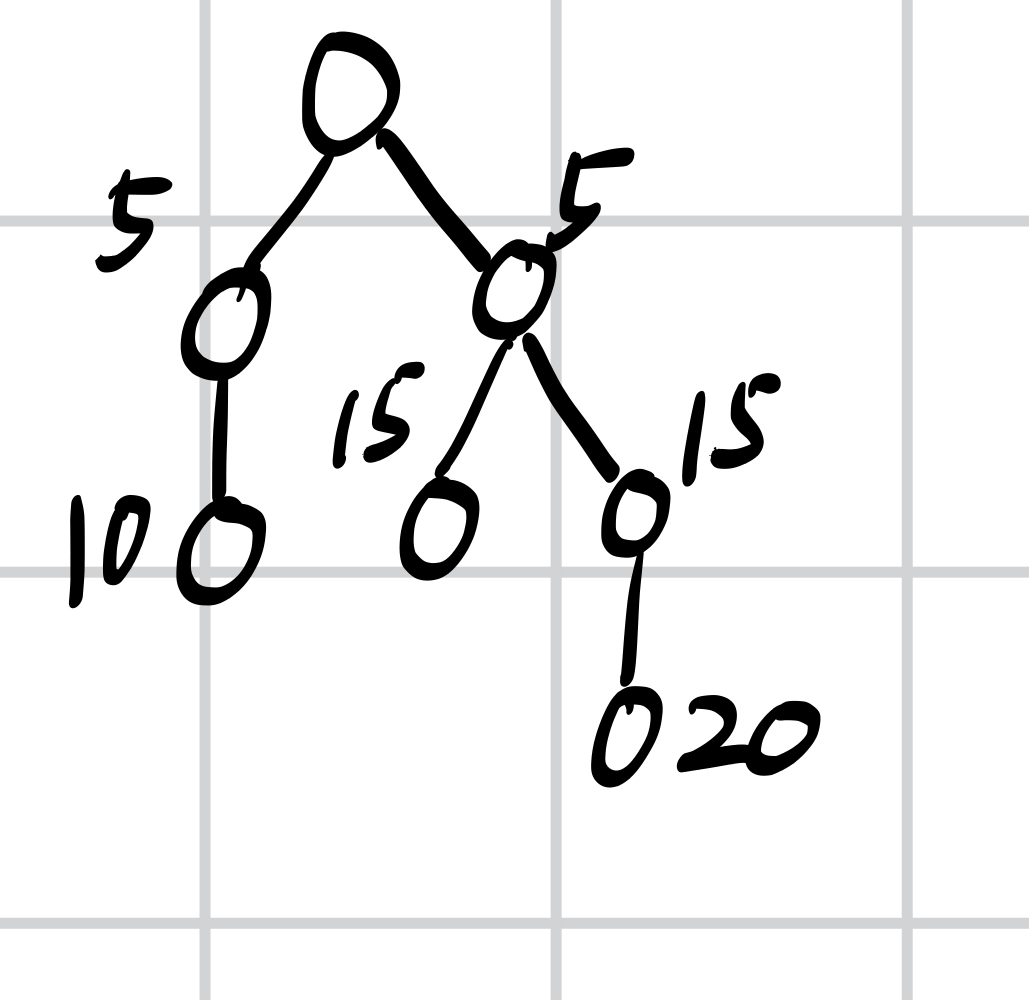
 三份copies,10,15,20
三份copies,10,15,20
 输出两个6和输出一个6
输出两个6和输出一个6

- 为什么线程2的”Hello”消息可能在线程5的”Hello”消息之后打印:
- 这是因为线程调度是由操作系统控制的,即使线程2先创建,它不一定会先执行
- 线程的执行顺序取决于操作系统的调度策略
- 每个线程获得CPU时间片的顺序是不确定的
- 因此,尽管创建顺序是确定的,执行顺序是不确定的
- 为什么线程2的”Thread returned”消息一定在线程5的”Thread returned”消息之前打印:
- 这是因为在第二个for循环中使用了thread_join()
- thread_join()会按照i的顺序(0到9)依次等待每个线程结束
- 所以无论线程实际什么时候结束,“Thread returned”消息都会按照i的顺序打印
- thread_join是阻塞的,必须等前面的线程join完成才会继续下一个
- 当线程5打印”Hello”时,系统中存在的线程数量:
- 最小值:6个线程(主线程 + 前5个创建的线程)
- 最大值:10个线程(主线程 + 所有NTHREADS个线程)
- 这取决于主线程创建线程的速度和每个线程执行的速度
- 当线程5打印时,线程0-4一定已经创建,但线程6-9可能已创建也可能还未创建

 False. 使用分页的虚拟内存系统不会受到外部碎片化的影响。
False. 使用分页的虚拟内存系统不会受到外部碎片化的影响。
- 页面大小固定:
- 所有物理内存都被分成大小相同的页框(page frames)
- 所有虚拟内存也被分成相同大小的页面(pages)
- 分配单位统一,不会产生难以利用的小碎片
- 分配机制:
- 任何空闲页框都可以被分配给任何虚拟页面
- 虚拟页面不需要连续的物理页框
- 内存分配以页为单位,不需要寻找连续空间
- 可能存在的问题:
- 可能存在内部碎片(页面内的未使用空间)
- 但不会有外部碎片(页框之间的未使用空间)
所以虽然分页系统可能有内部碎片问题,但由于其固定大小的分配单位和灵活的映射机制,本质上避免了外部碎片化问题。
 分页,32 bit
分页,32 bit
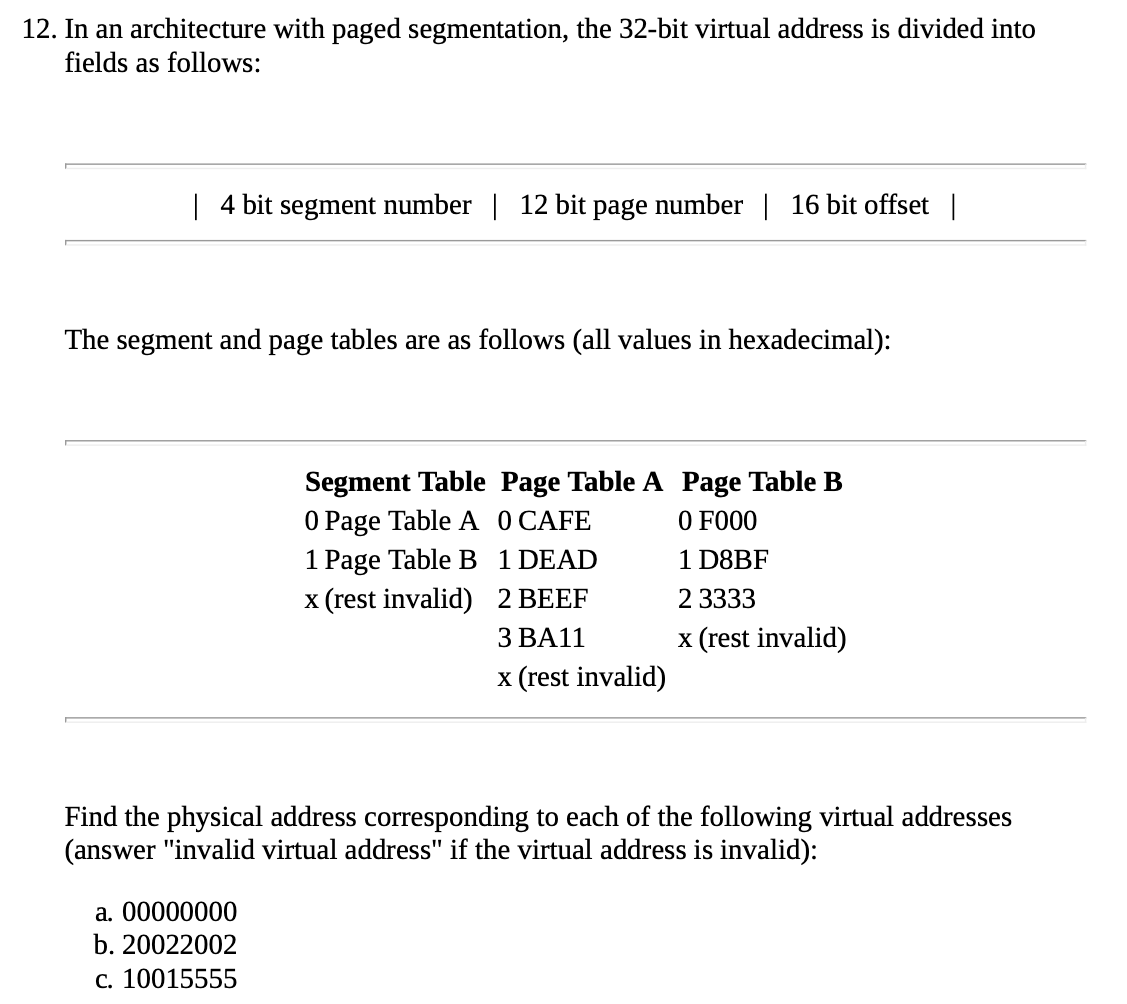
a. 0 Segment TableA 000
CAFE0000
b.Invalid virtual address c.D8BF5555
先根据第一位找到表A还是B
然后在表A/B中根据2-4位找到前4位地址,比如A[000]=CAFE,然后像分页一样拼接Offset

第二题 让我分析一下将页面大小从4KB增加到8KB的优缺点:
a. 增加性能的原因:
- 页表更小:
- 相同大小的内存需要更少的页表项
- 页表占用更少的内存空间
- TLB能覆盖更大的地址空间
- I/O效率提高:
- 每次磁盘I/O可以传输更多数据
- 减少了磁盘寻道和旋转延迟的开销
- 空间局部性:
- 如果程序具有良好的空间局部性
- 更大的页面可以减少缺页次数
b. 降低性能的原因:
- 内部碎片增加:
- 每个页面中未使用的空间可能更多
- 浪费更多的物理内存
- 页面调入/调出开销增加:
- 读写更大的页面需要更多时间
- 特别是当程序只需要页面中的小部分数据时
- 工作集问题:
- 可能装入更多不需要的数据
- 有效内存利用率下降
- 可能增加页面交换频率
- 时间局部性:
- 如果程序访问模式分散
- 更大的页面可能带来更多无用的数据传输

 a. 获得更快的CPU:
a. 获得更快的CPU:
- 会显著降低(significantly decrease)处理器利用率
- 原因:
- 系统明显是I/O受限的(分页磁盘利用率99.7%)
- 更快的CPU只会让CPU在I/O等待上花费更多时间
- 当前CPU利用率已经很低(20%),更快的CPU会进一步降低这个比率
b. 获得更快的分页磁盘:
- 会显著增加(significantly increase)处理器利用率
- 原因:
- 分页磁盘是明显的瓶颈(99.7%利用率)
- 更快的分页磁盘会减少I/O等待时间
- CPU将有更多时间执行实际工作
- 能缓解当前系统的瓶颈
c. 增加多道程序设计的程度:
- 会轻微降低(marginally decrease)处理器利用率
- 原因:
- 系统已经I/O受限
- 增加更多进程会增加页面调度的负担
- 会让已经过载的分页磁盘(99.7%)负担更重
- 可能导致更多的thrashing
- CPU会花更多时间等待I/O完成
解答题
 A=0,B=N,C=1
A=0,B=N,C=1
问题二: 不能调换,调换可能会导致死锁
 一个块可以存储个指针
一个块可以存储个指针
读取90KB,数据上需要读取12个block,需要读取10个直接索引,还需要读取一个间接索引的额外block,所以一共是13个
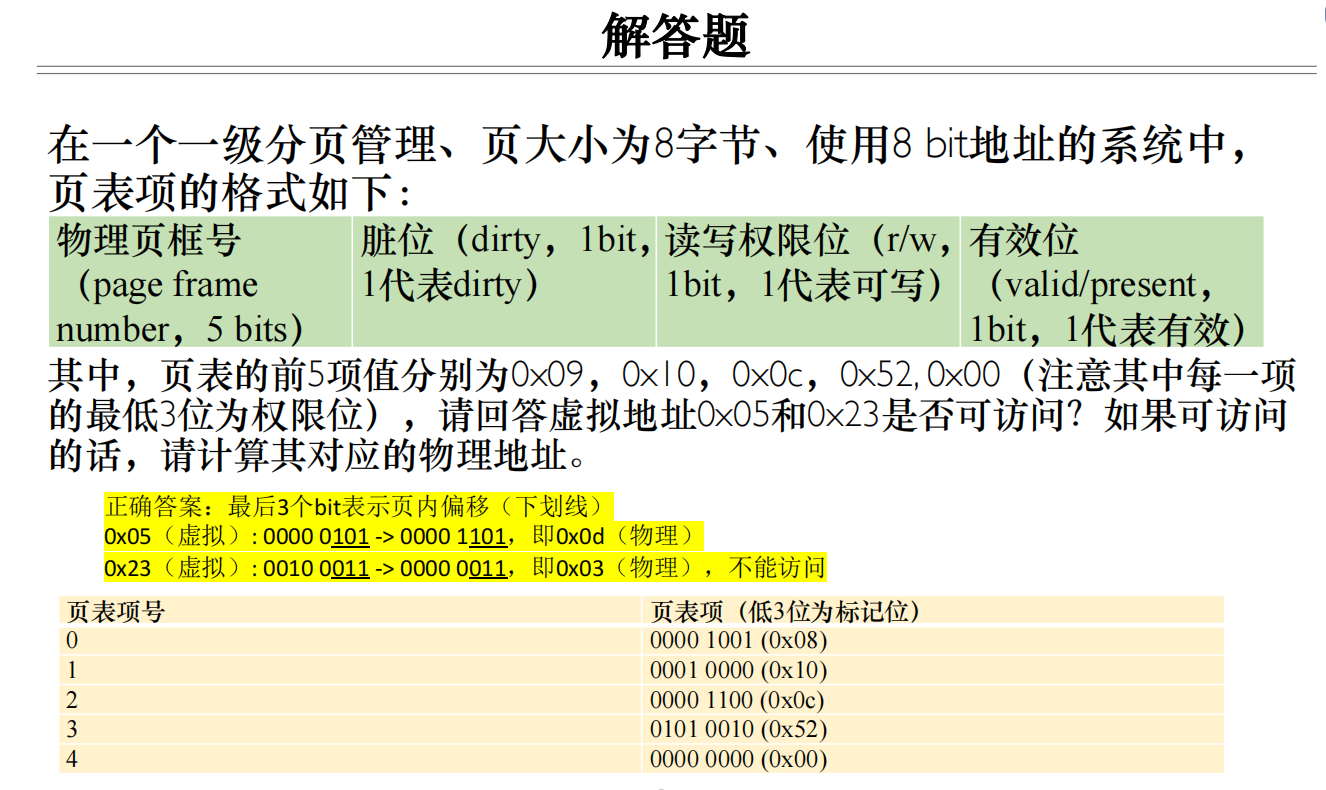 0x05=0000 0101
0x05=0000 0101
0x23=0010 0011